
Gdy ludzie mówią o „big data”, często przywoływany jest jeden przykład: proponowane narzędzie zdrowia publicznego o nazwie Google Flu Trends. Stało się ono czymś w rodzaju pin-up dla ruchu big data, ale może nie być tak skuteczne, jak wielu twierdzi.
Pomysł stojący za big data polega na tym, że duża ilość informacji może nam pomóc w robieniu rzeczy, których mniejsze ilości nie mogą. Google po raz pierwszy zarysował podejście Flu Trends w artykule z 2008 r. w czasopiśmie Nature. Zamiast polegać na nadzorze nad chorobami stosowanym przez amerykańskie Centra Kontroli i Zapobiegania Chorobom (CDC) – takim jak wizyty u lekarzy i badania laboratoryjne – autorzy zasugerowali, że możliwe byłoby przewidywanie epidemii poprzez wyszukiwanie w Google. Kiedy cierpi na grypę, wielu Amerykanów będzie szukać informacji związanych z ich stanem.
Zespół Google zebrał ponad 50 milionów potencjalnych terminów wyszukiwania – wszelkiego rodzaju frazy, nie tylko słowo „grypa” – i porównał częstotliwość, z jaką ludzie wyszukiwali te słowa z ilością zgłoszonych przypadków grypopodobnych w latach 2003-2006. Dane te ujawniły, że spośród milionów fraz istniało 45, które najlepiej pasowały do obserwowanych danych. Zespół przetestował następnie swój model na podstawie raportów o zachorowaniach z późniejszej epidemii w 2007 roku. Okazało się, że przewidywania były bardzo zbliżone do rzeczywistych poziomów zachorowań. Ponieważ Flu Trends było w stanie przewidzieć wzrost przypadków przed CDC, zostało to okrzyknięte nadejściem ery big data.
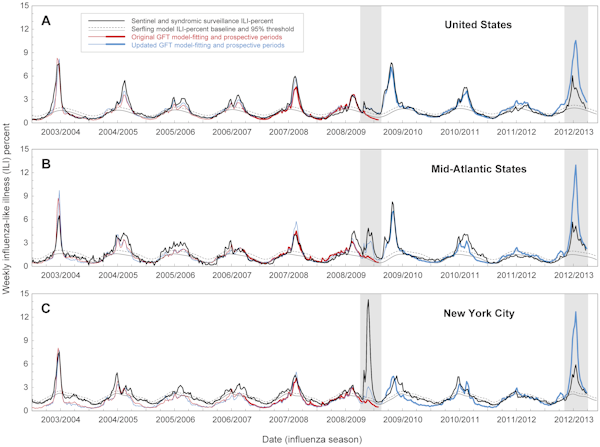
W latach 2003-2008 epidemie grypy w USA były silnie sezonowe, pojawiając się każdej zimy. Jednak w 2009 roku pierwsze przypadki (zgłoszone przez CDC) zaczęły się w Wielkanoc. Flu Trends już przygotowało swoje prognozy, gdy opublikowano dane CDC, ale okazało się, że model Google nie odpowiadał rzeczywistości. Znacząco niedoszacował on wielkości początkowej epidemii.
Problem polegał na tym, że Flu Trends mógł jedynie zmierzyć, czego ludzie szukają; nie analizował, dlaczego szukają tych słów. Usuwając wkład człowieka i pozwalając, aby surowe dane wykonywały pracę, model musiał tworzyć swoje prognozy, używając tylko zapytań z poprzednich kilku lat. Chociaż te 45 terminów pasowało do regularnych sezonowych epidemii z lat 2003-8, nie odzwierciedlały one pandemii, która pojawiła się w 2009 roku.
Sześć miesięcy po rozpoczęciu pandemii, Google – który teraz miał korzyści z perspektywy czasu – zaktualizowane ich model tak, że dopasowane do 2009 CDC danych. Pomimo tych zmian, zaktualizowana wersja Flu Trends ponownie napotkała trudności ostatniej zimy, kiedy to przeszacowała rozmiar epidemii grypy w stanie Nowy Jork. Incydenty z 2009 i 2012 roku podniosły kwestię tego, jak dobry jest Flu Trends w przewidywaniu przyszłych epidemii, w przeciwieństwie do zwykłego znajdowania wzorców w danych z przeszłości.
W nowej analizie, opublikowanej w czasopiśmie PLOS Computational Biology, amerykańscy naukowcy donoszą, że istnieją „znaczące błędy w szacunkach Google Flu Trends dotyczących czasu wystąpienia i intensywności grypy”. Opiera się to na porównaniu przewidywań Google Flu Trends i rzeczywistych danych epidemiologicznych na poziomie krajowym, regionalnym i lokalnym w latach 2003-2013
Nawet gdy zachowania związane z wyszukiwaniem były skorelowane z przypadkami grypy, model czasami błędnie szacował ważne wskaźniki zdrowia publicznego, takie jak szczytowy rozmiar epidemii i skumulowane przypadki. Prognozy były szczególnie błędne w 2009 i 2012 roku:
Choć skrytykowali pewne aspekty modelu Flu Trends, badacze uważają, że monitorowanie zapytań w wyszukiwarkach internetowych może jeszcze okazać się wartościowe, zwłaszcza jeśli byłoby połączone z innymi metodami nadzoru i przewidywania.
Inni badacze zasugerowali również, że inne źródła danych cyfrowych – od Twitter feeds do GPS telefonu komórkowego – mają potencjał, aby być użytecznymi narzędziami do badania epidemii. Oprócz pomocy w analizie ognisk choroby, takie metody mogłyby pozwolić badaczom na analizę ruchu ludzi i rozprzestrzeniania się informacji o zdrowiu publicznym (lub dezinformacji).
Ale chociaż wiele uwagi poświęcono narzędziom internetowym, istnieje inny rodzaj big data, który już ma ogromny wpływ na badania nad chorobami. Sekwencjonowanie genomów umożliwia badaczom ustalenie, w jaki sposób choroby się przenoszą i skąd mogą pochodzić. Dane sekwencyjne mogą nawet ujawnić istnienie nowego wariantu choroby: na początku tego tygodnia naukowcy ogłosili istnienie nowego typu wirusa gorączki denga.
Nie ma wątpliwości, że big data będzie miała kilka ważnych zastosowań w nadchodzących latach, czy to w medycynie, czy w innych dziedzinach. Zwolennicy muszą jednak uważać na to, czego używają do zilustrowania swoich pomysłów. Chociaż pojawia się wiele udanych przykładów, nie jest jeszcze jasne, czy Google Flu Trends jest jednym z nich.
.