
Cuando se habla de «big data», hay un ejemplo muy citado: una propuesta de herramienta de salud pública llamada Google Flu Trends. Se ha convertido en una especie de pin-up para el movimiento de los grandes datos, pero podría no ser tan eficaz como muchos afirman.
La idea detrás de los grandes datos es que una gran cantidad de información puede ayudarnos a hacer cosas que volúmenes más pequeños no pueden. Google esbozó por primera vez el enfoque de Flu Trends en un artículo publicado en 2008 en la revista Nature. En lugar de basarse en la vigilancia de enfermedades utilizada por los Centros de Control y Prevención de Enfermedades (CDC) de EE.UU. -como las visitas a los médicos y las pruebas de laboratorio-, los autores sugirieron que sería posible predecir epidemias a través de las búsquedas en Google. Cuando padecen gripe, muchos estadounidenses buscan información relacionada con su enfermedad.
El equipo de Google recopiló más de 50 millones de posibles términos de búsqueda -todo tipo de frases, no sólo la palabra «gripe»- y comparó la frecuencia con la que la gente buscaba estas palabras con la cantidad de casos de gripe registrados entre 2003 y 2006. Estos datos revelaron que, de los millones de frases, había 45 que se ajustaban mejor a los datos observados. A continuación, el equipo probó su modelo con los informes sobre la enfermedad de la posterior epidemia de 2007. Las predicciones parecían acercarse bastante a los niveles de enfermedad de la vida real. Dado que Flu Trends fue capaz de predecir un aumento de casos antes que los CDC, se anunció como la llegada de la era de los grandes datos.
Entre 2003 y 2008, las epidemias de gripe en Estados Unidos habían sido fuertemente estacionales, apareciendo cada invierno. Sin embargo, en 2009, los primeros casos (según los CDC) comenzaron en Semana Santa. Flu Trends ya había hecho sus predicciones cuando se publicaron los datos de los CDC, pero resultó que el modelo de Google no se ajustaba a la realidad. Había subestimado sustancialmente el tamaño del brote inicial.
El problema era que Flu Trends sólo podía medir lo que la gente buscaba; no analizaba por qué buscaban esas palabras. Al eliminar la aportación humana y dejar que los datos brutos hicieran el trabajo, el modelo tuvo que hacer sus predicciones utilizando sólo las consultas de búsqueda de los años anteriores. Aunque esos 45 términos coincidían con los brotes estacionales regulares de 2003-8, no reflejaban la pandemia que apareció en 2009.
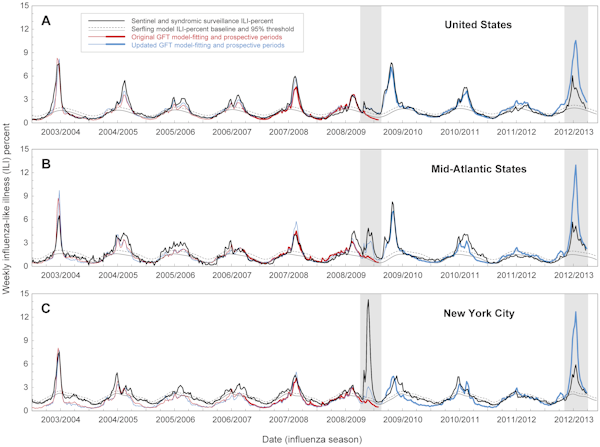
Seis meses después del inicio de la pandemia, Google -que ahora tenía la ventaja de la retrospectiva- actualizó su modelo para que coincidiera con los datos de los CDC de 2009. A pesar de estos cambios, la versión actualizada de Flu Trends volvió a tener dificultades el pasado invierno, cuando sobrestimó el tamaño de la epidemia de gripe en el estado de Nueva York. Los incidentes de 2009 y 2012 plantearon la cuestión de la eficacia de Flu Trends a la hora de predecir futuras epidemias, en lugar de limitarse a encontrar patrones en datos pasados.
En un nuevo análisis, publicado en la revista PLOS Computational Biology, investigadores estadounidenses informan de que existen «errores sustanciales en las estimaciones de Google Flu Trends sobre el momento y la intensidad de la gripe». Esto se basa en la comparación de las predicciones de Google Flu Trends y los datos reales de la epidemia a nivel nacional, regional y local entre 2003 y 2013
Incluso cuando el comportamiento de búsqueda se correlacionó con los casos de gripe, el modelo a veces estimó erróneamente importantes métricas de salud pública como el tamaño máximo del brote y los casos acumulados. Las predicciones fueron especialmente erróneas en 2009 y 2012:
Aunque criticaron ciertos aspectos del modelo Flu Trends, los investigadores creen que el seguimiento de las consultas de búsqueda en Internet podría resultar aún valioso, especialmente si se vinculara con otros métodos de vigilancia y predicción.
Otros investigadores también han sugerido que otras fuentes de datos digitales -desde los feeds de Twitter hasta el GPS de los teléfonos móviles- tienen el potencial de ser herramientas útiles para estudiar las epidemias. Además de ayudar a analizar los brotes, estos métodos podrían permitir a los investigadores analizar los movimientos humanos y la difusión de información (o desinformación) sobre salud pública.
Aunque se ha prestado mucha atención a las herramientas basadas en la web, hay otro tipo de big data que ya está teniendo un gran impacto en la investigación de enfermedades. La secuenciación del genoma está permitiendo a los investigadores averiguar cómo se transmiten las enfermedades y de dónde pueden proceder. Los datos de secuencias pueden incluso revelar la existencia de una nueva variante de la enfermedad: a principios de esta semana, los investigadores anunciaron un nuevo tipo de virus del dengue.
No hay duda de que los grandes datos tendrán algunas aplicaciones importantes en los próximos años, ya sea en medicina o en otros campos. Pero los defensores deben tener cuidado con lo que utilizan para ilustrar las ideas. Aunque están surgiendo muchos ejemplos de éxito, todavía no está claro que Google Flu Trends sea uno de ellos.