
Quando as pessoas falam de ‘grandes dados’, há um exemplo frequentemente citado: uma ferramenta de saúde pública proposta chamada Google Flu Trends. Tornou-se uma espécie de pin-up para o grande movimento de dados, mas pode não ser tão eficaz como muitos afirmam.
A ideia por detrás dos grandes dados é que uma grande quantidade de informação pode ajudar-nos a fazer coisas que volumes menores não podem fazer. O Google delineou pela primeira vez a abordagem das tendências da gripe em um artigo de 2008 na revista Nature. Em vez de confiar na vigilância de doenças utilizada pelos Centros de Controle e Prevenção de Doenças (CDC) dos EUA – como visitas a médicos e testes laboratoriais – os autores sugeriram que seria possível prever epidemias através das pesquisas do Google. Quando sofrem de gripe, muitos americanos pesquisarão informações relacionadas à sua condição.
A equipe do Google coletou mais de 50 milhões de termos potenciais de pesquisa – todo tipo de frases, não apenas a palavra “gripe” – e comparou a frequência com que as pessoas pesquisaram essas palavras com a quantidade de casos de gripe relatados entre 2003 e 2006. Estes dados revelaram que dos milhões de frases, 45 foram as que melhor se adequaram aos dados observados. A equipe testou então seu modelo contra relatos de doenças da epidemia subseqüente de 2007. As previsões pareciam estar muito próximas dos níveis de doenças da vida real. Como as tendências da gripe seriam capazes de prever um aumento nos casos antes do CDC, foi trunfado como a chegada da grande era dos dados.
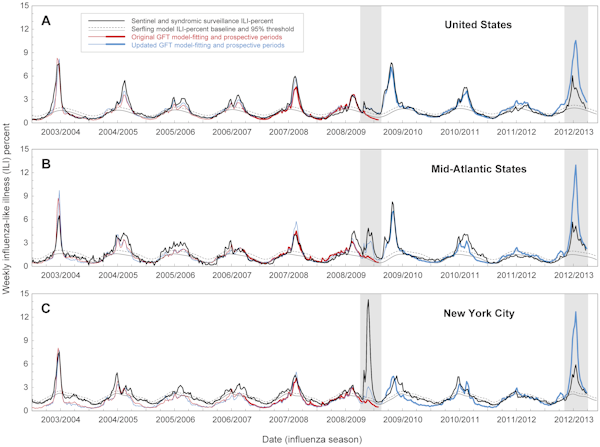
Entre 2003 e 2008, as epidemias de gripe nos EUA tinham sido fortemente sazonais, aparecendo a cada inverno. No entanto, em 2009, os primeiros casos (como relatado pelo CDC) começaram na Páscoa. As tendências da gripe já tinham feito suas previsões quando os dados do CDC foram publicados, mas verificou-se que o modelo do Google não correspondia à realidade. Ele havia subestimado substancialmente o tamanho do surto inicial.
O problema era que a Flu Trends só podia medir o que as pessoas procuravam; ela não analisava porque estavam procurando por essas palavras. Removendo a entrada humana e deixando os dados brutos fazer o trabalho, o modelo tinha que fazer suas previsões usando apenas consultas de pesquisa dos poucos anos anteriores. Embora esses 45 termos correspondessem aos surtos sazonais regulares de 2003-8, eles não refletiam a pandemia que surgiu em 2009.
Seis meses após o início da pandemia, o Google – que agora tinha o benefício de uma visão a posteriori – actualizou o seu modelo de modo a corresponder aos dados do CDC de 2009. Apesar dessas mudanças, a versão atualizada do Flu Trends encontrou dificuldades novamente no inverno passado, quando superestimou o tamanho da epidemia de gripe no estado de Nova York. Os incidentes de 2009 e 2012 levantaram a questão de quão boas são as Tendências da Gripe na previsão de epidemias futuras, ao contrário de meramente encontrar padrões em dados passados.
Numa nova análise, publicada na revista PLOS Computational Biology, pesquisadores dos EUA relatam que existem “erros substanciais nas estimativas do Google Flu Trends sobre o tempo e intensidade da gripe”. Isto é baseado na comparação das previsões do Google Flu Trends e dos dados reais da epidemia a nível nacional, regional e local entre 2003 e 2013
Aven quando o comportamento da pesquisa foi correlacionado com os casos de gripe, o modelo às vezes sugere medidas importantes de saúde pública, tais como pico de surtos e casos cumulativos. As previsões foram particularmente amplas em 2009 e 2012:
Apesar de terem criticado certos aspectos do modelo das Tendências da Gripe, os pesquisadores acham que o monitoramento de consultas de pesquisa na internet ainda pode ser valioso, especialmente se estiver ligado a outros métodos de vigilância e previsão.
Outros pesquisadores também sugeriram que outras fontes de dados digitais – desde feeds do Twitter até GPS de telefones celulares – têm potencial para serem ferramentas úteis para o estudo de epidemias. Além de ajudar a analisar surtos, tais métodos poderiam permitir aos pesquisadores analisar o movimento humano e a disseminação de informações de saúde pública (ou desinformação).
Embora muita atenção tenha sido dada a ferramentas baseadas na web, há outro tipo de grande dado que já está tendo um enorme impacto na pesquisa de doenças. O sequenciamento genético está permitindo que os pesquisadores analisem juntos como as doenças transmitem e de onde elas podem vir. Os dados sequenciais podem até revelar a existência de uma nova variante da doença: no início desta semana, os pesquisadores anunciaram um novo tipo de vírus da dengue.
Não há dúvida de que os grandes dados terão algumas aplicações importantes nos próximos anos, seja na medicina ou em outras áreas. Mas os defensores precisam ter cuidado com o que eles usam para ilustrar as idéias. Embora haja muitos exemplos de sucesso surgindo, ainda não está claro que o Google Flu Trends seja um deles.