
Amikor a “big data”-ról beszélnek, van egy gyakran idézett példa: a Google Influ Trends nevű javasolt közegészségügyi eszköz. Ez lett a big data mozgalom egyik jelképe, de lehet, hogy nem lesz olyan hatékony, mint sokan állítják.
A big data mögött az az elképzelés áll, hogy a nagy mennyiségű információ olyan dolgokat segíthet nekünk, amelyeket a kisebb mennyiségek nem tudnak. A Google először a Nature folyóiratban 2008-ban megjelent tanulmányában vázolta fel a Flu Trends megközelítést. Ahelyett, hogy az amerikai Betegségellenőrzési és Megelőzési Központok (CDC) által használt betegségfelügyeletre – például az orvoslátogatásokra és a laboratóriumi vizsgálatokra – támaszkodnának, a szerzők azt javasolták, hogy a Google-keresések segítségével meg lehetne jósolni a járványokat. Amikor influenzában szenvednek, sok amerikai rákeres az állapotával kapcsolatos információkra.
A Google-csoport több mint 50 millió lehetséges keresőkifejezést gyűjtött össze – mindenféle kifejezést, nem csak az “influenza” szót -, és összehasonlította, hogy az emberek milyen gyakran kerestek ezekre a szavakra, a 2003 és 2006 között bejelentett influenzaszerű megbetegedések számával. Ezekből az adatokból kiderült, hogy a több millió kifejezés közül 45 volt az, amely a legjobban illeszkedett a megfigyelt adatokhoz. A csapat ezután tesztelte modelljét az ezt követő 2007-es járványból származó betegségjelentésekkel. Úgy tűnt, hogy a jóslatok elég közel állnak a valós megbetegedési szintekhez. Mivel a Flu Trends a CDC előtt képes volt megjósolni a megbetegedések növekedését, a nagy adatok korának beköszönteként trombitálták.
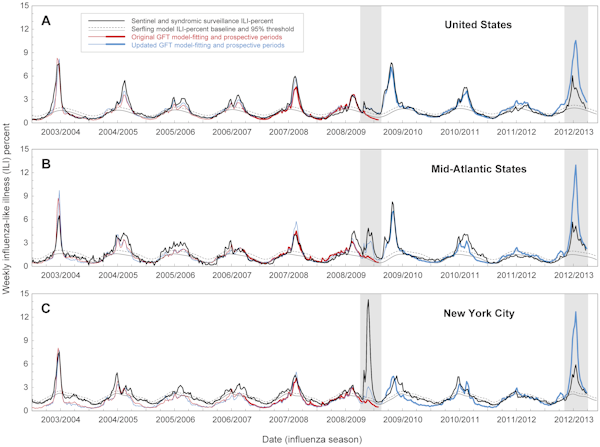
A 2003 és 2008 között az USA-ban az influenzajárványok erősen szezonálisak voltak, minden télen megjelentek. Azonban 2009-ben az első megbetegedések (a CDC jelentése szerint) húsvétkor kezdődtek. A Flu Trends már a CDC adatainak publikálásakor elkészítette előrejelzéseit, de kiderült, hogy a Google modellje nem felel meg a valóságnak. Jelentősen alábecsülte a kezdeti járvány méretét.
A probléma az volt, hogy a Flu Trends csak azt tudta mérni, hogy az emberek mire keresnek rá; nem elemezte, hogy miért keresnek rá ezekre a szavakra. Az emberi input eltávolításával és a nyers adatokra bízva a munkát, a modellnek csak az előző néhány év keresési lekérdezéseinek felhasználásával kellett előrejelzéseket készítenie. Bár ez a 45 kifejezés megfelelt a 2003-8 közötti rendszeres szezonális járványkitöréseknek, nem tükrözte a 2009-ben megjelent világjárványt.
Fél évvel a világjárvány kezdete után a Google – aki most már a visszatekintés előnyeivel rendelkezett – frissítette a modelljét, hogy az megfeleljen a CDC 2009-es adatainak. A változtatások ellenére a Flu Trends frissített változata tavaly télen ismét nehézségekbe ütközött, amikor túlbecsülte az influenzajárvány méretét New York államban. A 2009-es és 2012-es incidensek felvetették a kérdést, hogy a Flu Trends mennyire jó a jövőbeli járványok előrejelzésében, szemben azzal, hogy pusztán mintákat talál a múltbeli adatokban.
A PLOS Computational Biology folyóiratban közzétett új elemzésben amerikai kutatók arról számolnak be, hogy “jelentős hibák vannak a Google Flu Trends influenza időzítésére és intenzitására vonatkozó becsléseiben”. Ezt a Google Flu Trends előrejelzéseinek és a 2003 és 2013 közötti országos, regionális és helyi szintű tényleges járványadatoknak az összehasonlítása alapján állapították meg
Még ha a keresési viselkedés korrelált is az influenzás esetekkel, a modell néha tévesen becsülte meg az olyan fontos közegészségügyi mérőszámokat, mint a járványkitörés csúcsmérete és a kumulatív esetek száma. Az előrejelzések különösen 2009-ben és 2012-ben tévedtek:
Bár kritizálták a Flu Trends modell bizonyos aspektusait, a kutatók úgy vélik, hogy az internetes keresési lekérdezések nyomon követése még értékesnek bizonyulhat, különösen, ha összekapcsolják más felügyeleti és előrejelzési módszerekkel.
Más kutatók is felvetették, hogy a digitális adatok más forrásai – a Twitter-adatoktól a mobiltelefonos GPS-ig – hasznos eszközök lehetnek a járványok tanulmányozásában. Amellett, hogy segítenek a járványok kitörésének elemzésében, az ilyen módszerek lehetővé tehetik a kutatók számára az emberi mozgás és a közegészségügyi információk (vagy téves információk) terjedésének elemzését.
Noha nagy figyelmet kaptak a webalapú eszközök, van egy másik típusú nagy adat, amely már most is nagy hatással van a betegségek kutatására. A genomszekvenálás lehetővé teszi a kutatók számára, hogy összerakják, hogyan terjednek a betegségek, és honnan származhatnak. A szekvenciaadatok akár egy új betegségváltozat létezését is felfedhetik: a hét elején a kutatók bejelentették a dengue-láz vírusának egy új típusát.
Kétségtelen, hogy a big data az elkövetkező években fontos alkalmazásokkal fog rendelkezni, akár az orvostudományban, akár más területeken. A szószólóknak azonban óvatosnak kell lenniük azzal, hogy mivel illusztrálják az elképzeléseket. Bár rengeteg sikeres példa van kialakulóban, még nem egyértelmű, hogy a Google Flu Trends ezek közé tartozik.