
Lorsque les gens parlent de « big data », il y a un exemple souvent cité : un outil de santé publique proposé appelé Google Flu Trends. Il est devenu une sorte de pin-up pour le mouvement du big data, mais il pourrait ne pas être aussi efficace que beaucoup le prétendent.
L’idée derrière le big data est que de grandes quantités d’informations peuvent nous aider à faire des choses que de plus petits volumes ne peuvent pas faire. Google a d’abord décrit l’approche de Flu Trends dans un article publié en 2008 dans la revue Nature. Plutôt que de s’appuyer sur la surveillance des maladies utilisée par les centres américains de contrôle et de prévention des maladies (CDC) – comme les visites chez le médecin et les tests de laboratoire – les auteurs ont suggéré qu’il serait possible de prédire les épidémies grâce aux recherches effectuées sur Google. Lorsqu’ils souffrent de la grippe, de nombreux Américains recherchent des informations relatives à leur état.
L’équipe de Google a recueilli plus de 50 millions de termes de recherche potentiels – toutes sortes de phrases, pas seulement le mot « grippe » – et a comparé la fréquence à laquelle les gens recherchaient ces mots avec la quantité de cas de grippe signalés entre 2003 et 2006. Ces données ont révélé que, parmi les millions d’expressions, 45 correspondaient le mieux aux données observées. L’équipe a ensuite testé son modèle sur la base des rapports de maladie de l’épidémie qui a suivi en 2007. Les prédictions se sont révélées assez proches des niveaux de maladie réels. Parce que Flu Trends serait capable de prédire une augmentation des cas avant le CDC, il a été claironné comme l’arrivée de l’ère du big data.
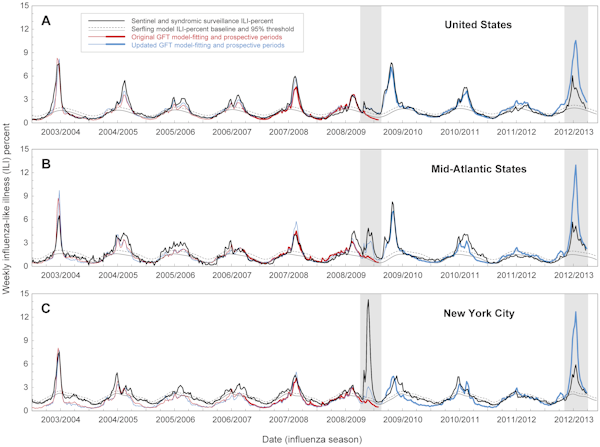
Entre 2003 et 2008, les épidémies de grippe aux États-Unis avaient été fortement saisonnières, apparaissant chaque hiver. Cependant, en 2009, les premiers cas (tels que rapportés par le CDC) ont commencé à Pâques. Flu Trends avait déjà fait ses prédictions lorsque les données du CDC ont été publiées, mais il s’est avéré que le modèle de Google ne correspondait pas à la réalité. Il avait considérablement sous-estimé la taille de l’épidémie initiale.
Le problème était que Flu Trends ne pouvait mesurer que ce que les gens recherchaient ; il n’analysait pas pourquoi ils recherchaient ces mots. En supprimant l’apport humain, et en laissant les données brutes faire le travail, le modèle a dû faire ses prédictions en utilisant uniquement les requêtes de recherche de la poignée d’années précédentes. Si ces 45 termes correspondaient aux épidémies saisonnières régulières de 2003 à 2008, ils ne reflétaient pas la pandémie apparue en 2009.
Six mois après le début de la pandémie, Google – qui avait maintenant le bénéfice du recul – a mis à jour son modèle afin qu’il corresponde aux données du CDC de 2009. Malgré ces changements, la version actualisée de Flu Trends a de nouveau rencontré des difficultés l’hiver dernier, lorsqu’elle a surestimé l’ampleur de l’épidémie de grippe dans l’État de New York. Les incidents de 2009 et 2012 ont soulevé la question de la capacité de Flu Trends à prédire les épidémies futures, par opposition à la simple recherche de modèles dans les données passées.
Dans une nouvelle analyse, publiée dans la revue PLOS Computational Biology, des chercheurs américains signalent qu’il y a « des erreurs substantielles dans les estimations de Google Flu Trends concernant le moment et l’intensité de la grippe ». Cette constatation est basée sur la comparaison des prédictions de Google Flu Trends et des données épidémiques réelles au niveau national, régional et local entre 2003 et 2013
Même lorsque le comportement de recherche était corrélé avec les cas de grippe, le modèle a parfois mal estimé des paramètres de santé publique importants tels que la taille du pic épidémique et les cas cumulés. Les prédictions étaient particulièrement fausses en 2009 et 2012:
Bien qu’ils aient critiqué certains aspects du modèle Flu Trends, les chercheurs pensent que la surveillance des requêtes de recherche sur Internet pourrait encore s’avérer précieuse, surtout si elle était liée à d’autres méthodes de surveillance et de prédiction.
D’autres chercheurs ont également suggéré que d’autres sources de données numériques – des flux Twitter aux GPS des téléphones portables – pourraient être des outils utiles pour étudier les épidémies. En plus d’aider à analyser les épidémies, ces méthodes pourraient permettre aux chercheurs d’analyser les mouvements humains et la diffusion d’informations de santé publique (ou de désinformation).
Bien qu’une grande attention ait été accordée aux outils basés sur le web, il existe un autre type de big data qui a déjà un impact énorme sur la recherche sur les maladies. Le séquençage du génome permet aux chercheurs de reconstituer le mode de transmission des maladies et leur origine. Les données de séquençage peuvent même révéler l’existence d’une nouvelle variante de maladie : en début de semaine, des chercheurs ont annoncé l’existence d’un nouveau type de virus de la dengue.
Il ne fait aucun doute que le big data aura des applications importantes dans les années à venir, que ce soit en médecine ou dans d’autres domaines. Mais les défenseurs de cette cause doivent faire attention à ce qu’ils utilisent pour illustrer ces idées. Si de nombreux exemples réussis émergent, il n’est pas encore évident que Google Flu Trends en fasse partie.