
Wanneer mensen het over “big data” hebben, is er een vaak aangehaald voorbeeld: een voorstel voor een instrument voor de volksgezondheid genaamd Google Grieptrends. Het is een soort pin-up geworden voor de big data-beweging, maar het zou wel eens niet zo effectief kunnen zijn als velen beweren.
Het idee achter big data is dat grote hoeveelheden informatie ons kunnen helpen dingen te doen die met kleinere hoeveelheden niet mogelijk zijn. Google schetste de aanpak van Flu Trends voor het eerst in een artikel uit 2008 in het tijdschrift Nature. In plaats van te vertrouwen op ziektesurveillance zoals gebruikt door de Amerikaanse Centers for Disease Control and Prevention (CDC) – zoals doktersbezoeken en laboratoriumtests – suggereerden de auteurs dat het mogelijk zou zijn om epidemieën te voorspellen via zoekopdrachten op Google. Wanneer ze griep hebben, zoeken veel Amerikanen naar informatie over hun aandoening.
Het Google-team verzamelde meer dan 50 miljoen potentiële zoektermen – allerlei soorten zinnen, niet alleen het woord “griep” – en vergeleek de frequentie waarmee mensen naar deze woorden zochten met het aantal gerapporteerde griepachtige gevallen tussen 2003 en 2006. Uit deze gegevens bleek dat van de miljoenen zinnen er 45 het beste pasten bij de waargenomen gegevens. Het team toetste hun model vervolgens aan de ziektemeldingen van de daaropvolgende epidemie van 2007. De voorspellingen bleken vrij goed overeen te komen met de werkelijke ziektecijfers. Omdat Flu Trends een toename van het aantal gevallen eerder kon voorspellen dan de CDC, werd het afgetroefd als de komst van het big data-tijdperk.
Tussen 2003 en 2008 waren griepepidemieën in de VS sterk seizoensgebonden geweest, waarbij ze elke winter opdoken. In 2009 begonnen de eerste gevallen (zoals gemeld door de CDC) echter met Pasen. Flu Trends had zijn voorspellingen al gedaan toen de CDC-gegevens werden gepubliceerd, maar het bleek dat het Google-model niet overeenkwam met de werkelijkheid. Het had de omvang van de eerste uitbraak aanzienlijk onderschat.
Het probleem was dat Flu Trends alleen kon meten waar mensen naar zochten; het kon niet analyseren waarom ze naar die woorden zochten. Door de menselijke input te verwijderen en de ruwe gegevens het werk te laten doen, moest het model zijn voorspellingen alleen doen op basis van zoekopdrachten uit de voorgaande handvol jaren. Hoewel die 45 termen overeenkwamen met de regelmatige seizoensgebonden uitbraken van 2003-8, kwamen ze niet overeen met de pandemie die in 2009 opdook.
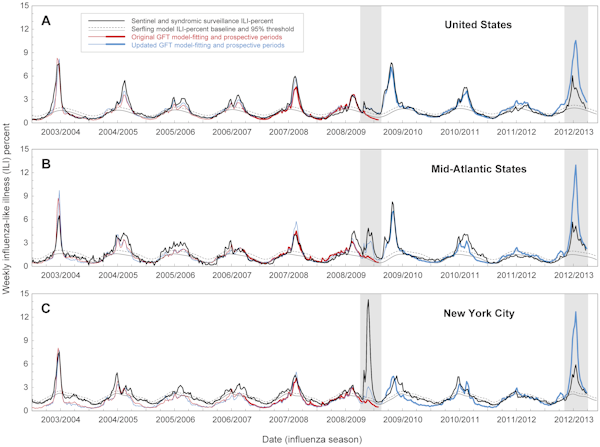
Zes maanden na het begin van de pandemie heeft Google – die nu het voordeel van hindsight had – zijn model bijgewerkt, zodat het overeenkwam met de CDC-gegevens van 2009. Ondanks deze wijzigingen kwam de bijgewerkte versie van Flu Trends afgelopen winter opnieuw in de problemen, toen het de omvang van de griepepidemie in de staat New York overschatte. De incidenten in 2009 en 2012 riepen de vraag op hoe goed Flu Trends is in het voorspellen van toekomstige epidemieën, in tegenstelling tot het louter vinden van patronen in gegevens uit het verleden.
In een nieuwe analyse, gepubliceerd in het tijdschrift PLOS Computational Biology, melden Amerikaanse onderzoekers dat er “substantiële fouten zijn in Google Flu Trends-schattingen van grieptiming en -intensiteit”. Dit is gebaseerd op een vergelijking van Google Flu Trends-voorspellingen en de werkelijke epidemische gegevens op nationaal, regionaal en lokaal niveau tussen 2003 en 2013
Zelfs wanneer zoekgedrag gecorreleerd was met griepgevallen, schatte het model soms belangrijke volksgezondheidsmetriek zoals piekuitbraakgrootte en cumulatieve gevallen verkeerd in. De voorspellingen waren met name in 2009 en 2012 ver bezijden de waarheid:
Hoewel zij kritiek hadden op bepaalde aspecten van het Flu Trends-model, denken de onderzoekers dat het volgen van zoekopdrachten op internet toch waardevol zou kunnen blijken, vooral als het zou worden gekoppeld aan andere bewakings- en voorspellingsmethoden.
Andere onderzoekers hebben ook gesuggereerd dat andere bronnen van digitale gegevens – van Twitter-feeds tot GPS van mobiele telefoons – het potentieel hebben om nuttige hulpmiddelen te zijn voor het bestuderen van epidemieën. Naast hulp bij het analyseren van uitbraken, zouden dergelijke methoden onderzoekers in staat kunnen stellen menselijke bewegingen en de verspreiding van informatie over de volksgezondheid (of verkeerde informatie) te analyseren.
Hoewel veel aandacht is besteed aan webgebaseerde hulpmiddelen, is er een ander type big data dat al een enorme impact heeft op het onderzoek naar ziekten. De sequentiebepaling van het genoom stelt onderzoekers in staat te achterhalen hoe ziekten zich overdragen en waar ze vandaan komen. Sequentiegegevens kunnen zelfs het bestaan van een nieuwe ziektevariant aan het licht brengen: eerder deze week maakten onderzoekers een nieuw type knokkelkoortsvirus bekend.
Het lijdt weinig twijfel dat big data de komende jaren een aantal belangrijke toepassingen zullen kennen, zowel in de geneeskunde als op andere gebieden. Maar voorstanders moeten voorzichtig zijn met wat ze gebruiken om de ideeën te illustreren. Hoewel er tal van succesvolle voorbeelden opduiken, is het nog niet duidelijk dat Google Flu Trends daar een van is.