
Wenn von „Big Data“ die Rede ist, gibt es ein oft zitiertes Beispiel: ein vorgeschlagenes Tool für das öffentliche Gesundheitswesen namens Google Flu Trends. Es ist zu einer Art Pin-up für die Big-Data-Bewegung geworden, aber es könnte nicht so effektiv sein, wie viele behaupten.
Die Idee hinter Big Data ist, dass große Mengen von Informationen uns helfen können, Dinge zu tun, die kleinere Mengen nicht können. Google hat den Ansatz von Flu Trends erstmals 2008 in einem Artikel in der Zeitschrift Nature vorgestellt. Anstatt sich auf die von den US-amerikanischen Centers for Disease Control and Prevention (CDC) durchgeführte Krankheitsüberwachung – wie Arztbesuche und Labortests – zu verlassen, schlugen die Autoren vor, dass es möglich sein sollte, Epidemien durch Google-Suchen vorherzusagen. Wenn sie an einer Grippe erkranken, suchen viele Amerikaner nach Informationen über ihre Erkrankung.
Das Google-Team sammelte mehr als 50 Millionen potenzielle Suchbegriffe – alle Arten von Phrasen, nicht nur das Wort „Grippe“ – und verglich die Häufigkeit, mit der Menschen nach diesen Begriffen suchten, mit der Anzahl der gemeldeten grippeähnlichen Fälle zwischen 2003 und 2006. Diese Daten ergaben, dass von den Millionen von Begriffen 45 die beste Übereinstimmung mit den beobachteten Daten lieferten. Das Team testete sein Modell dann anhand von Krankheitsberichten aus der darauf folgenden Epidemie von 2007. Die Vorhersagen schienen den realen Krankheitsniveaus ziemlich nahe zu kommen. Da Flu Trends in der Lage war, einen Anstieg der Fälle vor der CDC vorherzusagen, wurde es als Beginn des Big-Data-Zeitalters gefeiert.
Zwischen 2003 und 2008 waren die Grippeepidemien in den USA stark saisonabhängig und traten jeden Winter auf. Im Jahr 2009 begannen die ersten Fälle (wie von der CDC gemeldet) jedoch zu Ostern. Flu Trends hatte seine Vorhersagen bereits gemacht, als die CDC-Daten veröffentlicht wurden, aber es stellte sich heraus, dass das Google-Modell nicht der Realität entsprach. Es hatte das Ausmaß des ersten Ausbruchs erheblich unterschätzt.
Das Problem war, dass Flu Trends nur messen konnte, wonach die Menschen suchten; es analysierte nicht, warum sie nach diesen Wörtern suchten. Da die menschlichen Eingaben wegfielen und die Rohdaten die Arbeit erledigten, musste das Modell seine Vorhersagen nur anhand der Suchanfragen der letzten paar Jahre treffen. Obwohl diese 45 Begriffe den regelmäßigen saisonalen Ausbrüchen von 2003 bis 2008 entsprachen, spiegelten sie nicht die Pandemie wider, die 2009 auftrat.
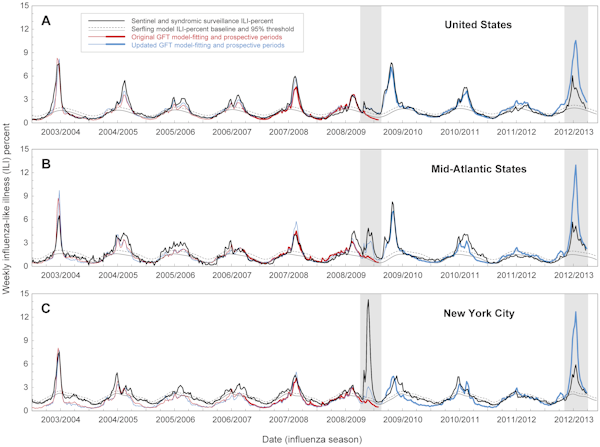
Sechs Monate nach Ausbruch der Pandemie aktualisierte Google – nun mit dem Vorteil der Rückschau – sein Modell, so dass es mit den CDC-Daten von 2009 übereinstimmte. Trotz dieser Änderungen geriet die aktualisierte Version von Flu Trends im letzten Winter erneut in Schwierigkeiten, als sie das Ausmaß der Grippeepidemie im Staat New York überschätzte. Die Vorfälle in den Jahren 2009 und 2012 warfen die Frage auf, wie gut Flu Trends bei der Vorhersage künftiger Epidemien ist, im Gegensatz zum bloßen Auffinden von Mustern in vergangenen Daten.
In einer neuen Analyse, die in der Fachzeitschrift PLOS Computational Biology veröffentlicht wurde, berichten US-Forscher, dass es „erhebliche Fehler in den Google Flu Trends-Schätzungen des Influenza-Zeitpunkts und der Intensität“ gibt. Dies geht aus einem Vergleich der Vorhersagen von Google Flu Trends mit den tatsächlichen Epidemiedaten auf nationaler, regionaler und lokaler Ebene zwischen 2003 und 2013 hervor
Selbst wenn das Suchverhalten mit den Influenzafällen korreliert war, schätzte das Modell manchmal wichtige Kennzahlen für die öffentliche Gesundheit falsch ein, wie etwa die Größe des Spitzenausbruchs und die kumulativen Fälle. Die Vorhersagen lagen besonders in den Jahren 2009 und 2012 weit daneben:
Obwohl sie bestimmte Aspekte des Grippetrends-Modells kritisierten, sind die Forscher der Meinung, dass sich die Überwachung von Internet-Suchanfragen dennoch als wertvoll erweisen könnte, insbesondere wenn sie mit anderen Überwachungs- und Vorhersagemethoden verknüpft würde.
Andere Forscher haben auch vorgeschlagen, dass andere Quellen digitaler Daten – von Twitter-Feeds bis zu Handy-GPS – das Potenzial haben, nützliche Werkzeuge für die Untersuchung von Epidemien zu sein. Solche Methoden könnten nicht nur bei der Analyse von Seuchenausbrüchen helfen, sondern den Forschern auch ermöglichen, die Bewegungen von Menschen und die Verbreitung von Informationen (oder Fehlinformationen) über die öffentliche Gesundheit zu analysieren.
Obwohl webbasierten Tools viel Aufmerksamkeit geschenkt wurde, gibt es noch eine andere Art von Big Data, die bereits große Auswirkungen auf die Krankheitsforschung hat. Die Genomsequenzierung ermöglicht es den Forschern, herauszufinden, wie sich Krankheiten übertragen und woher sie kommen könnten. Sequenzdaten können sogar die Existenz einer neuen Krankheitsvariante aufdecken: Anfang dieser Woche gaben Forscher eine neue Art von Dengue-Fieber-Virus bekannt.
Es besteht kaum ein Zweifel daran, dass Big Data in den kommenden Jahren einige wichtige Anwendungen haben wird, sei es in der Medizin oder in anderen Bereichen. Aber die Befürworter müssen vorsichtig sein, was sie zur Veranschaulichung ihrer Ideen verwenden. Es gibt zwar viele erfolgreiche Beispiele, aber es ist noch nicht klar, dass Google Flu Trends eines davon ist.