
När folk talar om ”stora datamängder” finns det ett ofta citerat exempel: ett föreslaget folkhälsoverktyg kallat Google Flu Trends. Det har blivit något av en pin-up för big data-rörelsen, men det kanske inte är så effektivt som många hävdar.
Tanken bakom big data är att stora mängder information kan hjälpa oss att göra saker som mindre volymer inte kan göra. Google beskrev först Flu Trends-strategin i en artikel i tidskriften Nature 2008. I stället för att förlita sig på den sjukdomsövervakning som används av USA:s Centers for Disease Control and Prevention (CDC) – t.ex. läkarbesök och laboratorietester – föreslog författarna att det skulle vara möjligt att förutsäga epidemier med hjälp av Google-sökningar. När många amerikaner lider av influensa söker de efter information om sitt tillstånd.
Google-teamet samlade in mer än 50 miljoner potentiella söktermer – alla slags fraser, inte bara ordet ”influensa” – och jämförde hur ofta människor sökte efter dessa ord med antalet rapporterade influensaliknande fall mellan 2003 och 2006. Dessa uppgifter visade att av de miljontals fraserna var det 45 som bäst passade till de observerade uppgifterna. Teamet testade sedan sin modell mot sjukdomsrapporter från den efterföljande epidemin 2007. Prognoserna verkade ligga ganska nära de verkliga sjukdomsnivåerna. Eftersom Flu Trends kunde förutsäga en ökning av antalet fall före CDC, så utropades det som ankomsten av big data-åldern.
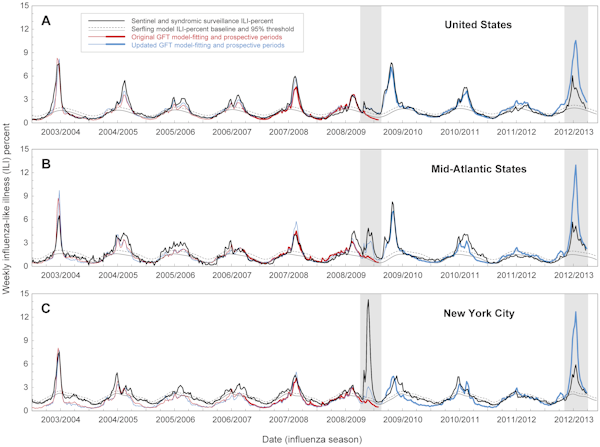
Mellan 2003 och 2008 hade influensaepidemier i USA varit starkt säsongsbetonade och uppträtt varje vinter. År 2009 började dock de första fallen (enligt CDC:s rapport) under påsken. Flu Trends hade redan gjort sina förutsägelser när CDC:s uppgifter publicerades, men det visade sig att Googles modell inte stämde överens med verkligheten. Den hade väsentligt underskattat storleken på det första utbrottet.
Problemet var att Flu Trends bara kunde mäta vad folk sökte efter; den analyserade inte varför de sökte efter dessa ord. Genom att ta bort mänsklig input och låta rådata göra jobbet var modellen tvungen att göra sina förutsägelser med hjälp av endast sökfrågor från de senaste åren. Även om dessa 45 termer matchade de regelbundna säsongsutbrotten från 2003-8 återspeglade de inte den pandemi som dök upp 2009.
Sex månader efter det att pandemin startade uppdaterade Google – som nu hade fördelen av efterklokhet – sin modell så att den matchade CDC:s data från 2009. Trots dessa ändringar stötte den uppdaterade versionen av Flu Trends på problem igen förra vintern, när den överskattade storleken på influensaepidemin i delstaten New York. Incidenterna 2009 och 2012 väckte frågan om hur bra Flu Trends är på att förutsäga framtida epidemier, till skillnad från att bara hitta mönster i tidigare uppgifter.
I en ny analys, som publiceras i tidskriften PLOS Computational Biology, rapporterar amerikanska forskare att det finns ”betydande fel i Googles Flu Trends uppskattningar av tidpunkter och intensitet av influensa”. Detta baseras på en jämförelse mellan Google Flu Trends förutsägelser och faktiska epidemidata på nationell, regional och lokal nivå mellan 2003 och 2013
Även när sökbeteendet var korrelerat med influensafall, underskattade modellen ibland viktiga folkhälsometriska mått, som t.ex. toppstorlek av utbrottet och kumulativa fall. Prognoserna var särskilt felaktiga 2009 och 2012:
Och även om de kritiserade vissa aspekter av Flu Trends-modellen anser forskarna att övervakningen av sökfrågor på internet ändå kan visa sig vara värdefull, särskilt om den kopplas samman med andra övervaknings- och prognosmetoder.
Andra forskare har också föreslagit att andra källor till digitala data – från Twitterflöden till GPS i mobiltelefoner – har potential att bli användbara verktyg för att studera epidemier. Förutom att hjälpa till att analysera utbrott skulle sådana metoder kunna göra det möjligt för forskare att analysera mänskliga rörelser och spridningen av folkhälsoinformation (eller felaktig information).
Och även om mycket uppmärksamhet har ägnats åt webbaserade verktyg finns det en annan typ av stora data som redan har en enorm inverkan på sjukdomsforskningen. Genomsekvensering gör det möjligt för forskare att sätta ihop hur sjukdomar smittar och varifrån de kan komma. Sekvensdata kan till och med avslöja förekomsten av en ny sjukdomsvariant: tidigare i veckan tillkännagav forskarna en ny typ av denguefebervirus.
Det råder knappast någon tvekan om att stora data kommer att få en del viktiga tillämpningar under de kommande åren, oavsett om det är inom medicin eller andra områden. Men förespråkare måste vara försiktiga med vad de använder för att illustrera idéerna. Även om det finns gott om framgångsrika exempel som håller på att växa fram är det ännu inte säkert att Google Flu Trends är ett av dem.