
Når folk taler om “big data”, er der et ofte citeret eksempel: et foreslået folkesundhedsværktøj kaldet Google Flu Trends. Det er blevet lidt af en pin-up for big data-bevægelsen, men det er måske ikke så effektivt, som mange hævder.
Tanken bag big data er, at store mængder information kan hjælpe os med at gøre ting, som mindre mængder ikke kan. Google skitserede først Flu Trends-tilgangen i en artikel i 2008 i tidsskriftet Nature. I stedet for at stole på den sygdomsovervågning, der anvendes af de amerikanske centre for sygdomskontrol og forebyggelse (CDC) – såsom lægebesøg og laboratorieundersøgelser – foreslog forfatterne, at det ville være muligt at forudsige epidemier ved hjælp af Google-søgninger. Når de lider af influenza, søger mange amerikanere efter oplysninger om deres tilstand.
Google-holdet indsamlede mere end 50 millioner potentielle søgetermer – alle mulige sætninger, ikke kun ordet “influenza” – og sammenlignede den hyppighed, hvormed folk søgte efter disse ord, med antallet af rapporterede influenzalignende tilfælde mellem 2003 og 2006. Disse data afslørede, at ud af de millioner af sætninger var der 45, der passede bedst til de observerede data. Holdet testede derefter deres model på baggrund af sygdomsrapporter fra den efterfølgende epidemi i 2007. Forudsigelserne viste sig at ligge ret tæt på det virkelige sygdomsniveau. Fordi Flu Trends var i stand til at forudsige en stigning i antallet af tilfælde før CDC, blev det udråbt som ankomsten af big data-æraen.
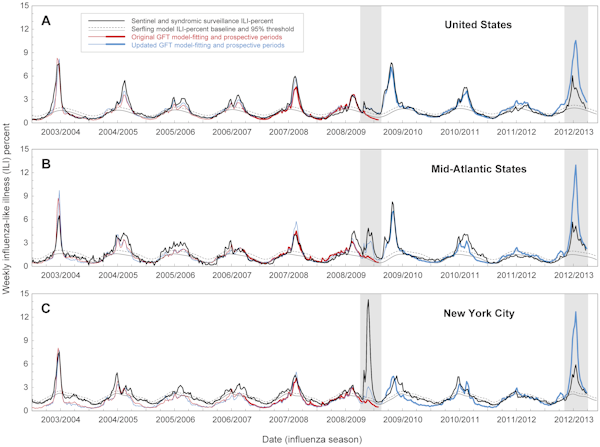
Mellem 2003 og 2008 havde influenzaepidemier i USA været stærkt sæsonbestemte og optrådte hver vinter. I 2009 begyndte de første tilfælde (som rapporteret af CDC) imidlertid i påsken. Flu Trends havde allerede lavet sine forudsigelser, da CDC-dataene blev offentliggjort, men det viste sig, at Googles model ikke stemte overens med virkeligheden. Den havde undervurderet størrelsen af det første udbrud betydeligt.
Problemet var, at Flu Trends kun kunne måle, hvad folk søgte efter; den analyserede ikke, hvorfor de søgte efter disse ord. Ved at fjerne menneskeligt input og lade de rå data gøre arbejdet, måtte modellen lave sine forudsigelser ved kun at bruge søgeforespørgsler fra den foregående håndfuld år. Selv om disse 45 termer passede til de regelmæssige sæsonbestemte udbrud fra 2003-8, afspejlede de ikke den pandemi, der opstod i 2009.
Seks måneder efter pandemien startede, opdaterede Google – som nu havde fordelen af at se bagud – deres model, så den matchede CDC-dataene fra 2009. På trods af disse ændringer stødte den opdaterede version af Flu Trends igen på problemer sidste vinter, da den overvurderede størrelsen af influenzaepidemien i staten New York. Hændelserne i 2009 og 2012 rejste spørgsmålet om, hvor god Flu Trends er til at forudsige fremtidige epidemier i modsætning til blot at finde mønstre i tidligere data.
I en ny analyse, der er offentliggjort i tidsskriftet PLOS Computational Biology, rapporterer amerikanske forskere, at der er “betydelige fejl i Google Flu Trends’ estimater af influenzatidspunkt og -intensitet”. Dette er baseret på en sammenligning af Google Flu Trends’ forudsigelser og de faktiske epidemidata på nationalt, regionalt og lokalt plan mellem 2003 og 2013
Selv når søgeadfærd var korreleret med influenzatilfælde, fejlvurderede modellen undertiden vigtige folkesundhedsmålinger som f.eks. peak-udbruddets størrelse og kumulative tilfælde. Forudsigelserne var især langt fra målet i 2009 og 2012:
Selv om de kritiserede visse aspekter af Flu Trends-modellen, mener forskerne, at overvågning af internet-søgningsforespørgsler alligevel kan vise sig at være værdifuld, især hvis den blev forbundet med andre overvågnings- og forudsigelsesmetoder.
Andre forskere har også foreslået, at andre kilder til digitale data – fra Twitter-feeds til mobiltelefoners GPS – har potentiale til at være nyttige værktøjer til undersøgelse af epidemier. Ud over at hjælpe med at analysere udbrud kan sådanne metoder give forskerne mulighed for at analysere menneskers bevægelser og spredningen af folkesundhedsinformation (eller misinformation).
Selv om der er blevet lagt stor vægt på webbaserede værktøjer, er der en anden type big data, som allerede har stor betydning for sygdomsforskningen. Genomsekventering sætter forskerne i stand til at finde ud af, hvordan sygdomme smitter, og hvor de kan komme fra. Sekvensdata kan endda afsløre eksistensen af en ny sygdomsvariant: Tidligere i denne uge offentliggjorde forskere en ny type denguefebervirus.
Der er næppe tvivl om, at big data vil få nogle vigtige anvendelser i de kommende år, hvad enten det er inden for medicin eller på andre områder. Men fortalerne skal være forsigtige med, hvad de bruger til at illustrere idéerne. Selv om der er masser af vellykkede eksempler på vej frem, er det endnu ikke sikkert, at Google Flu Trends er et af dem.