
Quando si parla di ‘big data’, c’è un esempio spesso citato: uno strumento di salute pubblica proposto chiamato Google Flu Trends. È diventato una specie di pin-up per il movimento dei big data, ma potrebbe non essere così efficace come molti sostengono.
L’idea dietro i big data è che grandi quantità di informazioni possono aiutarci a fare cose che volumi più piccoli non possono. Google ha delineato per la prima volta l’approccio di Flu Trends in un documento del 2008 sulla rivista Nature. Piuttosto che fare affidamento sulla sorveglianza delle malattie utilizzata dai Centri statunitensi per il controllo e la prevenzione delle malattie (CDC) – come le visite ai medici e gli esami di laboratorio – gli autori hanno suggerito che sarebbe stato possibile prevedere le epidemie attraverso le ricerche di Google. Quando soffrono di influenza, molti americani cercano informazioni relative alla loro condizione.
Il team di Google ha raccolto più di 50 milioni di potenziali termini di ricerca – tutti i tipi di frasi, non solo la parola “influenza” – e ha confrontato la frequenza con cui la gente ha cercato queste parole con la quantità di casi di influenza segnalati tra il 2003 e il 2006. Questi dati hanno rivelato che tra i milioni di frasi, ce n’erano 45 che fornivano il miglior adattamento ai dati osservati. Il team ha poi testato il loro modello contro i rapporti di malattia della successiva epidemia del 2007. Le previsioni sembravano essere abbastanza vicine ai livelli di malattia della vita reale. Poiché Flu Trends sarebbe stato in grado di prevedere un aumento dei casi prima del CDC, è stato salutato come l’arrivo dell’era dei big data.
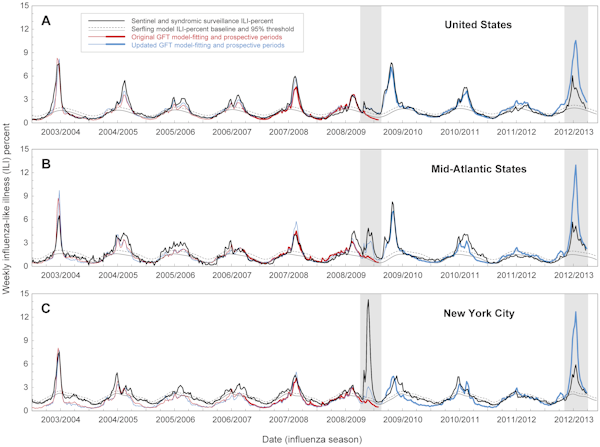
Tra il 2003 e il 2008, le epidemie di influenza negli Stati Uniti erano state fortemente stagionali, comparendo ogni inverno. Tuttavia, nel 2009, i primi casi (come riportato dal CDC) sono iniziati a Pasqua. Flu Trends aveva già fatto le sue previsioni quando i dati del CDC sono stati pubblicati, ma si è scoperto che il modello di Google non corrispondeva alla realtà. Aveva sostanzialmente sottostimato le dimensioni del focolaio iniziale.
Il problema era che Flu Trends poteva solo misurare ciò che la gente cercava; non analizzava il motivo per cui stavano cercando quelle parole. Rimuovendo l’input umano e lasciando che i dati grezzi facessero il lavoro, il modello ha dovuto fare le sue previsioni utilizzando solo le query di ricerca della manciata di anni precedenti. Anche se quei 45 termini corrispondevano alle regolari epidemie stagionali del 2003-8, non riflettevano la pandemia che è apparsa nel 2009.
Sei mesi dopo l’inizio della pandemia, Google – che ora aveva il beneficio del senno di poi – ha aggiornato il suo modello in modo che corrispondesse ai dati CDC del 2009. Nonostante queste modifiche, la versione aggiornata di Flu Trends ha incontrato di nuovo difficoltà lo scorso inverno, quando ha sovrastimato la dimensione dell’epidemia di influenza nello Stato di New York. Gli incidenti del 2009 e del 2012 hanno sollevato la questione di quanto sia bravo Flu Trends a prevedere le epidemie future, invece di limitarsi a trovare modelli nei dati del passato.
In una nuova analisi, pubblicata sulla rivista PLOS Computational Biology, i ricercatori americani riferiscono che ci sono “errori sostanziali nelle stime di Google Flu Trends sui tempi e l’intensità dell’influenza”. Questo si basa sul confronto tra le previsioni di Google Flu Trends e i dati epidemici reali a livello nazionale, regionale e locale tra il 2003 e il 2013
Anche quando il comportamento di ricerca era correlato ai casi di influenza, il modello a volte stimava male importanti parametri di salute pubblica come la dimensione del picco del focolaio e i casi cumulativi. Le previsioni erano particolarmente larghe nel 2009 e nel 2012:
Anche se hanno criticato alcuni aspetti del modello Flu Trends, i ricercatori pensano che il monitoraggio delle query di ricerca su Internet potrebbe ancora rivelarsi prezioso, soprattutto se fosse collegato con altri metodi di sorveglianza e previsione.
Altri ricercatori hanno anche suggerito che altre fonti di dati digitali – dai feed di Twitter al GPS dei telefoni cellulari – hanno il potenziale per essere strumenti utili per studiare le epidemie. Oltre ad aiutare ad analizzare le epidemie, questi metodi potrebbero permettere ai ricercatori di analizzare i movimenti umani e la diffusione delle informazioni sulla salute pubblica (o la disinformazione).
Anche se molta attenzione è stata data agli strumenti basati sul web, c’è un altro tipo di big data che sta già avendo un enorme impatto sulla ricerca sulle malattie. Il sequenziamento del genoma sta permettendo ai ricercatori di mettere insieme come le malattie si trasmettono e da dove potrebbero venire. I dati delle sequenze possono persino rivelare l’esistenza di una nuova variante della malattia: all’inizio di questa settimana, i ricercatori hanno annunciato un nuovo tipo di virus della febbre dengue.
C’è poco dubbio che i big data avranno alcune importanti applicazioni nei prossimi anni, sia in medicina che in altri campi. Ma i sostenitori devono stare attenti a cosa usano per illustrare le idee. Mentre ci sono molti esempi di successo che stanno emergendo, non è ancora chiaro che Google Flu Trends sia uno di questi.
.