
Când oamenii vorbesc despre „big data”, există un exemplu des citat: un instrument de sănătate publică propus numit Google Flu Trends. Acesta a devenit un fel de pin-up pentru mișcarea big data, dar s-ar putea să nu fie atât de eficient pe cât pretind mulți.
Ideea din spatele big data este că o cantitate mare de informații ne poate ajuta să facem lucruri pe care volume mai mici nu le pot face. Google a prezentat pentru prima dată abordarea Flu Trends într-o lucrare din 2008 în revista Nature. În loc să se bazeze pe supravegherea bolilor folosită de Centrele pentru Controlul și Prevenirea Bolilor (CDC) din SUA – cum ar fi vizitele la medic și testele de laborator – autorii au sugerat că ar fi posibil să se prevadă epidemiile prin intermediul căutărilor pe Google. Atunci când suferă de gripă, mulți americani vor căuta informații legate de starea lor.
Echipa Google a colectat peste 50 de milioane de termeni potențiali de căutare – tot felul de fraze, nu doar cuvântul „gripă” – și a comparat frecvența cu care oamenii au căutat aceste cuvinte cu numărul de cazuri de gripă raportate între 2003 și 2006. Aceste date au arătat că, din milioanele de fraze, au existat 45 care au oferit cea mai bună potrivire cu datele observate. Echipa și-a testat apoi modelul pe baza rapoartelor de boală de la epidemia ulterioară din 2007. Predicțiile s-au dovedit a fi destul de apropiate de nivelurile de îmbolnăvire din viața reală. Deoarece Flu Trends ar fi reușit să prezică o creștere a numărului de cazuri înaintea CDC, a fost trâmbițat ca fiind sosirea erei big data.
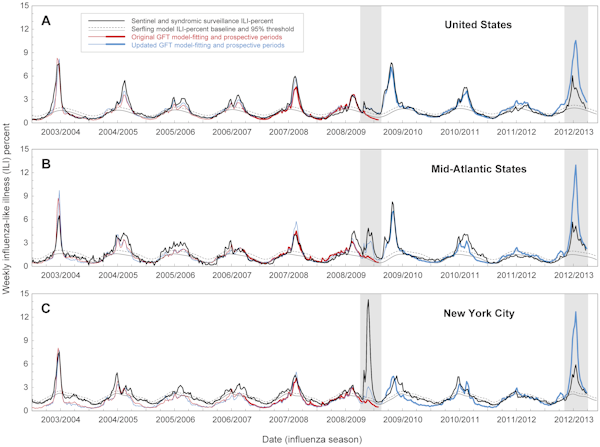
Între 2003 și 2008, epidemiile de gripă din SUA au fost puternic sezoniere, apărând în fiecare iarnă. Cu toate acestea, în 2009, primele cazuri (așa cum au fost raportate de CDC) au început de Paște. Flu Trends își făcuse deja predicțiile atunci când au fost publicate datele CDC, dar s-a dovedit că modelul Google nu corespundea realității. Acesta subestimase în mod substanțial dimensiunea focarului inițial.
Problema era că Flu Trends putea măsura doar ceea ce căutau oamenii; nu analiza de ce căutau acele cuvinte. Eliminând contribuția umană și lăsând datele brute să facă treaba, modelul a trebuit să își facă predicțiile folosind doar interogările de căutare din câțiva ani anteriori. Deși acei 45 de termeni se potriveau cu focarele sezoniere regulate din 2003-8, nu reflectau pandemia care a apărut în 2009.
La șase luni după începerea pandemiei, Google – care acum avea avantajul retrospectivității – și-a actualizat modelul astfel încât să corespundă cu datele CDC din 2009. În ciuda acestor modificări, versiunea actualizată a Flu Trends s-a confruntat din nou cu dificultăți iarna trecută, când a supraestimat dimensiunea epidemiei de gripă din statul New York. Incidentele din 2009 și 2012 au ridicat întrebarea cât de bun este Flu Trends la prezicerea viitoarelor epidemii, spre deosebire de simpla găsire a modelelor în datele din trecut.
Într-o nouă analiză, publicată în revista PLOS Computational Biology, cercetătorii americani raportează că există „erori substanțiale în estimările Google Flu Trends privind calendarul și intensitatea gripei”. Acest lucru se bazează pe compararea previziunilor Google Flu Trends și a datelor epidemice reale la nivel național, regional și local între 2003 și 2013
Chiar și atunci când comportamentul de căutare a fost corelat cu cazurile de gripă, modelul a estimat uneori greșit parametri importanți de sănătate publică, cum ar fi mărimea vârfului epidemiei și cazurile cumulate. Predicțiile au fost deosebit de departe de adevăr în 2009 și 2012:
Deși au criticat anumite aspecte ale modelului Flu Trends, cercetătorii consideră că monitorizarea interogărilor de căutare pe internet s-ar putea dovedi încă valoroasă, mai ales dacă ar fi legată de alte metode de supraveghere și predicție.
Alți cercetători au sugerat, de asemenea, că alte surse de date digitale – de la fluxurile Twitter la GPS-ul telefoanelor mobile – au potențialul de a fi instrumente utile pentru studierea epidemiilor. Pe lângă faptul că ajută la analiza focarelor de epidemii, astfel de metode ar putea permite cercetătorilor să analizeze mișcările umane și răspândirea informațiilor (sau a dezinformărilor) privind sănătatea publică.
Deși s-a acordat multă atenție instrumentelor bazate pe web, există un alt tip de date mari care are deja un impact uriaș asupra cercetării bolilor. Secvențierea genomului le permite cercetătorilor să pună cap la cap modul în care se transmit bolile și de unde ar putea proveni acestea. Datele de secvențiere pot chiar dezvălui existența unei noi variante de boală: la începutul acestei săptămâni, cercetătorii au anunțat un nou tip de virus al febrei dengue.
Nu există nicio îndoială că big data va avea unele aplicații importante în următorii ani, fie în medicină, fie în alte domenii. Dar susținătorii trebuie să fie atenți la ceea ce folosesc pentru a ilustra ideile. Deși există o mulțime de exemple de succes care apar, nu este încă clar că Google Flu Trends este unul dintre ele.
.