
人々が「ビッグデータ」について話すとき、よく引用される例があります。 これは、ビッグデータ運動のピンナップのようなものですが、多くの人が主張するほど効果的ではないかもしれません。
ビッグデータの背後にある考え方は、大量の情報が、少量ではできないことを行うのに役立つということです。 Googleは、Nature誌に掲載された2008年の論文で、Flu Trendsのアプローチについて初めて概説しています。 米国疾病管理予防センター(CDC)が使用している疾病サーベイランス(医師の診察や検査など)に頼るのではなく、著者らは、Google検索を通じて流行を予測することが可能であることを示唆しました。 インフルエンザに罹患すると、多くのアメリカ人は自分の症状に関連する情報を検索します。
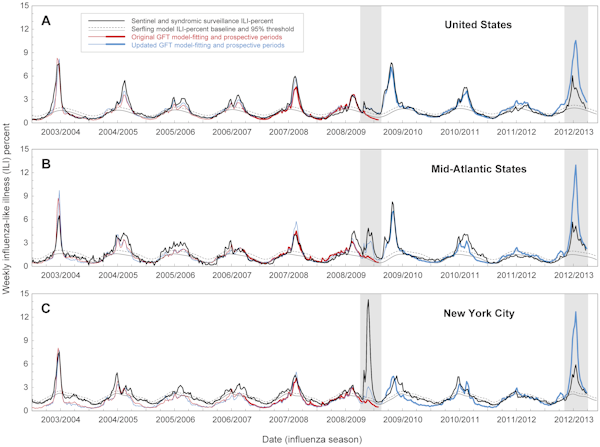
Googleチームは、5000万以上の潜在的な検索キーワード(「インフルエンザ」という単語だけでなく、あらゆる種類のフレーズ)を集め、これらの単語の検索頻度を、2003年から2006年に報告されたインフルエンザ様事例の量と比較しています。 その結果、数百万の語句のうち、観測データに最も適合する語句は45語であることが判明した。 研究チームは、このモデルを、その後に流行した2007年の疾病報告に対してテストした。 その結果、予測値は現実の疾病レベルにかなり近いと思われた。 2003年から2008年にかけて、米国ではインフルエンザの流行は季節性が強く、毎年冬になると発生していた。 しかし、2009年、最初の患者(CDCによる報告)がイースター(復活祭)に始まりました。 CDCのデータが発表されたとき、Flu Trendsはすでに予測を行っていたが、Googleのモデルは現実と一致していないことが判明した。
問題は、Flu Trends は人々が何を検索したかを測定するだけで、なぜその単語を検索したかを分析することはできなかったということです。 人間の入力を排除し、生データに任せることで、モデルは、過去数年間の検索クエリのみを使用して予測を行う必要がありました。 この45語は、2003年から8年にかけての季節的な流行にはマッチしていましたが、2009年に発生したパンデミックは反映されていませんでした。
パンデミック発生から 6 ヶ月後、Google は、後知恵でモデルを更新し、2009 年の CDC データと一致するようにしました。 これらの変更にもかかわらず、更新されたバージョンの Flu Trends は、昨年の冬、ニューヨーク州におけるインフルエンザの流行の規模を過大評価し、再び困難に直面しました。 2009年と2012年の事件は、Flu Trendsが、過去のデータのパターンを見つけるだけでなく、将来の流行を予測するのにどれだけ優れているかという疑問を提起しました。 これは、2003年から2013年までの国、地域、地方レベルでのGoogle Flu Trendsの予測と実際の流行データの比較に基づいています
検索行動がインフルエンザの症例と相関している場合でも、モデルは、ピーク発生サイズや累積症例といった公衆衛生上の重要指標を誤って見積もることがありました。 特に2009年と2012年に予測が大きく外れた。
Flu Trends モデルの特定の側面を批判していますが、研究者は、インターネット検索クエリのモニタリングは、特に他の監視および予測方法とリンクされた場合、まだ価値があることを証明するかもしれないと考えています。
他の研究者も、Twitter のフィードから携帯電話の GPS まで、他のデジタル データ ソースが伝染病の研究に役立つツールになる可能性があることを示唆しています。 集団発生の分析に役立つだけでなく、このような手法により、研究者は人の動きや公衆衛生情報(または誤報)の拡散を分析できるかもしれません。
Webベースのツールに注目が集まっていますが、病気研究にすでに大きな影響を与えている別のタイプのビッグデータもあります。 ゲノム配列の決定により、研究者は病気がどのように伝染し、どこから来るのかを解明することができます。 今週初め、研究者はデング熱ウイルスの新型を発表しました。
ビッグデータが今後数年間、医学やその他の分野で重要な用途を持つことは疑いの余地がありません。 しかし、提唱者は、そのアイデアを説明するために何を使うかについて注意する必要があります。 成功した例がたくさん出てきている一方で、Google Flu Trendsがその1つであることはまだ明らかではありません
。