
Když se mluví o „velkých datech“, často se uvádí příklad: navrhovaný nástroj veřejného zdravotnictví nazvaný Google Flu Trends. Stal se jakýmsi svorníkem hnutí big data, ale možná nebude tak efektivní, jak mnozí tvrdí.
Myšlenka big data spočívá v tom, že velké množství informací nám může pomoci dělat věci, které menší objemy dělat nemohou. Společnost Google poprvé nastínila přístup Flu Trends v roce 2008 v článku v časopise Nature. Autoři navrhli, že namísto spoléhání se na sledování nemocí používané americkým Centrem pro kontrolu a prevenci nemocí (CDC) – jako jsou návštěvy lékařů a laboratorní testy – by bylo možné předpovídat epidemie pomocí vyhledávání na Googlu. Když trpí chřipkou, mnoho Američanů vyhledává informace související s jejich onemocněním.
Tým Google shromáždil více než 50 milionů potenciálních hledaných výrazů – nejrůznějších frází, nejen slova „chřipka“ – a porovnal četnost, s jakou lidé tato slova vyhledávali, s množstvím hlášených případů chřipce podobných onemocnění v letech 2003 až 2006. Tato data odhalila, že z milionů frází bylo 45, které nejlépe odpovídaly sledovaným údajům. Tým poté otestoval svůj model na hlášeních o onemocnění z následné epidemie v roce 2007. Ukázalo se, že předpovědi se dosti blížily skutečným úrovním onemocnění. Protože Flu Trends dokázal předpovědět nárůst případů dříve než CDC, bylo to vytrubováno do světa jako nástup věku velkých dat.
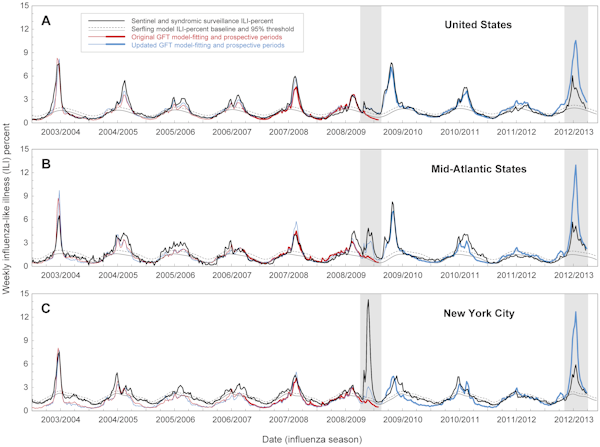
Mezi lety 2003 a 2008 měly chřipkové epidemie v USA výrazně sezónní charakter, objevovaly se každou zimu. V roce 2009 však první případy (podle údajů CDC) začaly o Velikonocích. V době, kdy byly zveřejněny údaje CDC, již společnost Flu Trends vypracovala své předpovědi, ale ukázalo se, že model společnosti Google neodpovídá skutečnosti. Výrazně podcenil velikost počáteční epidemie.
Problém spočíval v tom, že Flu Trends dokázal měřit pouze to, co lidé vyhledávají; neanalyzoval, proč tato slova hledají. Tím, že model odstranil lidský vstup a nechal pracovat surová data, musel své předpovědi vytvářet pouze na základě vyhledávacích dotazů z několika předchozích let. Těchto 45 výrazů sice odpovídalo pravidelným sezónním epidemiím z let 2003-8, ale neodráželo pandemii, která se objevila v roce 2009.
Šest měsíců po začátku pandemie společnost Google – která nyní měla výhodu zpětného pohledu – aktualizovala svůj model tak, aby odpovídal údajům CDC z roku 2009. Navzdory těmto změnám se aktualizovaná verze Flu Trends minulou zimu opět dostala do potíží, když nadhodnotila rozsah chřipkové epidemie ve státě New York. Případy z let 2009 a 2012 vyvolaly otázku, jak dobře umí Flu Trends předpovídat budoucí epidemie, na rozdíl od pouhého hledání vzorců v minulých datech.
V nové analýze, zveřejněné v časopise PLOS Computational Biology, američtí vědci uvádějí, že v odhadech časování a intenzity chřipky v Google Flu Trends jsou „podstatné chyby“. Vyplývá to ze srovnání předpovědí Google Flu Trends a skutečných údajů o epidemii na celostátní, regionální a místní úrovni v letech 2003 až 2013
I když bylo chování při vyhledávání korelováno s případy chřipky, model někdy nesprávně odhadoval důležité ukazatele veřejného zdraví, jako je velikost vrcholu epidemie a kumulativní počet případů. Předpovědi byly obzvláště nepřesné v letech 2009 a 2012:
Ačkoli vědci kritizovali některé aspekty modelu Flu Trends, domnívají se, že sledování internetových vyhledávacích dotazů by se ještě mohlo ukázat jako cenné, zejména pokud by bylo propojeno s dalšími metodami sledování a předpovídání.
Jiní výzkumníci také naznačili, že další zdroje digitálních dat – od kanálů na Twitteru po GPS v mobilních telefonech – mají potenciál být užitečnými nástroji pro studium epidemií. Kromě pomoci při analýze epidemií by tyto metody mohly výzkumníkům umožnit analyzovat pohyb lidí a šíření informací (nebo dezinformací) o veřejném zdraví.
Přestože byla velká pozornost věnována webovým nástrojům, existuje ještě jeden typ velkých dat, který již má na výzkum nemocí velký vliv. Sekvenování genomu umožňuje výzkumníkům dát dohromady, jak se nemoci přenášejí a odkud mohou pocházet. Sekvenční data mohou dokonce odhalit existenci nové varianty onemocnění: začátkem tohoto týdne vědci oznámili nový typ viru horečky dengue.
Není pochyb o tom, že velká data budou mít v příštích letech několik důležitých aplikací, ať už v medicíně, nebo v jiných oblastech. Zastánci těchto myšlenek si však musí dávat pozor na to, co používají k jejich ilustraci. Přestože se objevuje spousta úspěšných příkladů, zatím není jasné, zda mezi ně patří i Google Flu Trends.