Wprowadzenie
Wszystko czym jest kompilator, to tylko program. Program bierze wejście (które jest kodem źródłowym – aka plik bajtów lub danych) i generalnie produkuje zupełnie inaczej wyglądający program, który jest teraz wykonywalny; w przeciwieństwie do wejścia.
Na większości nowoczesnych systemów operacyjnych, pliki są zorganizowane w jednowymiarowe tablice bajtów. Format pliku jest definiowany przez jego zawartość, ponieważ plik jest wyłącznie pojemnikiem na dane, chociaż na niektórych platformach format jest zwykle wskazywany przez rozszerzenie nazwy pliku, określające zasady, w jaki sposób bajty muszą być zorganizowane i interpretowane sensownie. Na przykład, bajty pliku tekstowego (
.txtw Windows) są związane ze znakami ASCII lub UTF-8, podczas gdy bajty plików graficznych, wideo i audio są interpretowane inaczej. (Wikipedia)
(https://en.wikipedia.org/wiki/Computer_file#File_contents)
Kompilator bierze twój czytelny dla człowieka kod źródłowy, analizuje go, a następnie produkuje kod czytelny dla komputera, zwany kodem maszynowym (binarnym). Niektóre kompilatory (zamiast iść prosto do kodu maszynowego) pójdą do montażu, lub innego języka czytelnego dla człowieka.
Języki czytelne dla człowieka są AKA językami wysokiego poziomu. Kompilator, który przechodzi z jednego języka wysokiego poziomu do innego języka wysokiego poziomu nazywany jest kompilatorem źródło-źródło, transkompilatorem lub transpilerem.
(https://en.wikipedia.org/wiki/Source-to-source_compiler)
int main() {
int a = 5;
a = a * 5;
return 0;
}
Powyżej znajduje się program C napisany przez człowieka, który wykonuje następujące czynności w prostszym, jeszcze bardziej czytelnym dla człowieka języku zwanym pseudokodem:
program 'main' returns an integer
begin
store the number '5' in the variable 'a'
'a' equals 'a' times '5'
return '0'
end
Pseudokod jest nieformalnym, wysokopoziomowym opisem zasady działania programu komputerowego lub innego algorytmu. (Wikipedia)
(https://en.wikipedia.org/wiki/Pseudocode)
Przekompilujemy ten program C do kodu asemblera w stylu Intela, tak jak robi to kompilator. Chociaż komputer musi być specyficzny i podążać za algorytmami, aby określić, co tworzy słowa, liczby całkowite i symbole; my możemy po prostu użyć zdrowego rozsądku. To z kolei czyni naszą dezambiguację znacznie krótszą niż w przypadku kompilatora.
Ta analiza jest uproszczona dla łatwiejszego zrozumienia.
Tokenizacja
Zanim komputer może odszyfrować program, musi najpierw podzielić każdy symbol na jego własny token. Token jest ideą znaku, lub grupy znaków, wewnątrz pliku źródłowego. Proces ten nazywany jest tokenizacją i jest wykonywany przez tokenizator.
Nasz oryginalny kod źródłowy zostałby podzielony na tokeny i zachowany wewnątrz pamięci komputera. Spróbuję przekazać pamięć komputera w poniższym diagramie produkcji tokenizera.
Przed:
int main() {
int a = 5;
a = a * 5;
return 0;
}
Po:
Diagram jest ręcznie sformatowany dla czytelności. W rzeczywistości nie byłby on wcięty ani podzielony na linie.
Jak widzisz, tworzy on bardzo dosłowną formę tego, co zostało mu przekazane. Powinieneś być w stanie prawie odtworzyć oryginalny kod źródłowy, biorąc pod uwagę tylko tokeny. Tokeny powinny zachować typ, a jeśli typ może mieć więcej niż jedną wartość, token powinien również zawierać odpowiadającą mu wartość.
Same tokeny nie wystarczą do kompilacji. Musimy znać kontekst i wiedzieć, co te tokeny oznaczają, gdy są połączone razem. To prowadzi nas do parsowania, gdzie możemy nadać sens tym tokenom.
Parsing
Faza parsowania bierze tokeny i produkuje abstrakcyjne drzewo składniowe, lub AST. Zasadniczo opisuje ono strukturę programu i może być użyte do określenia sposobu jego wykonania, w bardzo – jak sama nazwa wskazuje – abstrakcyjny sposób. Jest to bardzo podobne do tego, kiedy tworzyłeś drzewa gramatyczne w gimnazjum z angielskiego.
Parser zazwyczaj kończy się byciem najbardziej złożoną częścią kompilatora. Parsery są skomplikowane i wymagają dużo ciężkiej pracy i zrozumienia. Dlatego istnieje wiele programów, które mogą wygenerować cały parser w zależności od tego, jak go opiszesz.
Te „narzędzia do tworzenia parsera” są nazywane generatorami parsera. Generatory parserów są specyficzne dla języków, ponieważ generują parser w kodzie tego języka. Bison (C/C++) jest jednym z najbardziej znanych generatorów parserów na świecie.
Parser, w skrócie, próbuje dopasować tokeny do już zdefiniowanych wzorców tokenów. Na przykład, możemy powiedzieć, że przypisanie przyjmuje następującą postać tokenów, używając EBNF:
EBNF (lub jego dialekt) jest powszechnie używany w generatorach parserów do definiowania gramatyki.
assignment = identifier, equals, int | identifier ;
Oznacza następujące wzorce tokenów są uważane za przypisanie:
a = 5
or
a = a
or
b = 123456789
Ale następujące wzorce nie są, mimo że powinny być:
int a = 5
or
a = a * 5
Te, które nie działają, nie są niemożliwe, ale raczej wymagają dalszego rozwoju i złożoności wewnątrz parsera, zanim będzie można je całkowicie zaimplementować.
Przeczytaj następujący artykuł Wikipedii, jeśli jesteś bardziej zainteresowany tym, jak działają parsery. https://en.wikipedia.org/wiki/Parsing
Teoretycznie, po zakończeniu parsowania, nasz parser wygenerowałby abstrakcyjne drzewo składniowe jak poniżej:
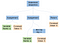
W informatyce, abstrakcyjne drzewo składniowe (AST), lub po prostu drzewo składniowe, jest drzewiastą reprezentacją abstrakcyjnej struktury składniowej kodu źródłowego napisanego w języku programowania. (Wikipedia)
(https://en.wikipedia.org/wiki/Abstract_syntax_tree)
Po tym, jak abstrakcyjne drzewo składniowe określa wysokopoziomową kolejność wykonywania kodu i operacje do wykonania, staje się całkiem proste do rozpoczęcia generowania kodu asemblera.
Generowanie kodu
Ponieważ AST zawiera gałęzie, które prawie całkowicie definiują program, możemy przejść przez te gałęzie, sekwencyjnie generując równoważny asembler. Nazywa się to „chodzeniem po drzewie” i jest to algorytm generowania kodu przy użyciu AST.
Generowanie kodu natychmiast po parsowaniu nie jest powszechne w bardziej złożonych kompilatorach, ponieważ przechodzą one przez więcej faz przed uzyskaniem ostatecznego AST, takich jak pośrednie, optymalizacja itp. Istnieje więcej technik generowania kodu.
https://en.wikipedia.org/wiki/Code_generation_(compiler)
Kompilujemy do asemblera, ponieważ pojedynczy asembler może produkować kod maszynowy dla jednej, lub kilku różnych architektur procesora. Na przykład, gdyby nasz kompilator generował asembler NASM, nasze programy byłyby kompatybilne z architekturami Intel x86 (16-bitową, 32-bitową i 64-bitową). Kompilacja bezpośrednio do kodu maszynowego nie byłaby tak efektywna, ponieważ musielibyśmy napisać backend dla każdej architektury docelowej niezależnie. Chociaż byłoby to dość czasochłonne i przyniosłoby mniejszy zysk niż użycie asemblera innej firmy.
Z LLVM, możesz po prostu skompilować do LLVM IR, a on zajmie się resztą. Kompiluje się do szerokiej gamy języków asemblerowych, a tym samym kompiluje się do wielu innych architektur. Jeśli słyszałeś o LLVM wcześniej, prawdopodobnie widzisz, dlaczego jest tak ceniony, teraz.
https://en.wikipedia.org/wiki/LLVM
Jeśli mielibyśmy wejść w gałęzie sekwencji oświadczeń, znaleźlibyśmy wszystkie oświadczenia, które są uruchamiane od lewej do prawej. Możemy przejść w dół tych gałęzi od lewej do prawej, umieszczając równoważny kod asemblera. Za każdym razem, gdy kończymy jakąś gałąź, musimy wrócić do góry i rozpocząć pracę nad nową gałęzią.
Najbardziej wysunięta na lewo gałąź naszej sekwencji instrukcji zawiera pierwsze przypisanie do nowej zmiennej całkowitej, a. Przypisana wartość jest listkiem, który zawiera stałą wartość całki, 5. Podobnie jak lewa gałąź, środkowa gałąź jest przypisaniem. Przypisuje ona operację binarną (bin op) mnożenia pomiędzy a i 5, do a . Dla uproszczenia po prostu odwołujemy się do a dwa razy z tego samego węzła, zamiast mieć dwa węzły a.
Ostatnia gałąź jest po prostu powrotem i jest przeznaczona na kod zakończenia programu. Mówimy komputerowi, że wyszedł normalnie, zwracając zero.
Poniżej znajduje się produkcja kompilatora GNU C (x86-64 GCC 8.1), biorąc pod uwagę nasz kod źródłowy bez optymalizacji.
Należy pamiętać, że kompilator nie wygenerował komentarzy ani odstępów.
main:
push rbp
mov rbp, rsp
mov DWORD PTR , 5 ; leftmost branch
mov edx, DWORD PTR ; middle branch
mov eax, edx
sal eax, 2
add eax, edx
mov DWORD PTR , eax
mov eax, 0 ; rightmost branch
pop rbp
ret
Niesamowite narzędzie; Compiler Explorer autorstwa Matta Godbolta, pozwala pisać kod i widzieć produkcje kompilatora w czasie rzeczywistym. Wypróbuj nasz eksperyment na https://godbolt.org/g/Uo2Z5E.
Generator kodu zazwyczaj próbuje zoptymalizować kod w jakiś sposób. Technicznie rzecz biorąc, nigdy nie używamy naszej zmiennej a. Nawet jeśli przypisujemy do niej, nigdy więcej jej nie odczytujemy. Kompilator powinien to rozpoznać i ostatecznie usunąć całą zmienną w końcowej produkcji asemblera. Nasza zmienna pozostała, ponieważ nie skompilowaliśmy jej z optymalizacjami.
Możesz dodać argumenty do kompilatora w Eksploratorze kompilatorów.
-O3to flaga dla GCC, która oznacza maksymalną optymalizację. Spróbuj ją dodać i zobacz, co się stanie z wygenerowanym kodem.
Po wygenerowaniu kodu asemblera, możemy skompilować go do kodu maszynowego, używając asemblera. Kod maszynowy działa tylko dla pojedynczej docelowej architektury procesora. Aby skierować się na nową architekturę, musimy dodać tę architekturę docelową zespołu, aby była produkowalna przez nasz generator kodu.
Atembler, którego używasz do kompilacji zespołu do kodu maszynowego, jest również napisany w języku programowania. Może być nawet napisany w swoim własnym języku asemblera. Pisanie kompilatora w języku, który kompiluje, nazywa się bootstrappingiem.
https://en.wikipedia.org/wiki/Bootstrapping_(compilers)
Wniosek
Kompilatory pobierają tekst, parsują go i przetwarzają, a następnie zamieniają w kod binarny do odczytania przez komputer. To trzyma cię z dala od konieczności ręcznego pisania binarnego dla twojego komputera, a ponadto, pozwala ci pisać złożone programy łatwiej.
Backmatter
I to jest to! Dokonaliśmy tokenizacji, parsowania i wygenerowaliśmy nasz kod źródłowy. Mam nadzieję, że po przeczytaniu tego masz większe zrozumienie komputerów i oprogramowania. Jeśli nadal jesteś zdezorientowany, po prostu sprawdź niektóre z zasobów edukacyjnych, które wymieniłem na dole. Nigdy nie miałem tego wszystkiego po przeczytaniu jednego artykułu. Jeśli masz jakieś pytania, sprawdzić, czy ktoś inny już zapytał go przed podjęciem do sekcji komentarzy.