Jest niedzielny poranek, rostry mają się zablokować na wczesne popołudnie, a ty decydujesz pomiędzy dwoma WR z dziewiątego poziomu o slot WR3. To Tydzień 3, obaj są desperackimi pickami z listy rezerwowej, których nie miałeś czasu sprawdzić, a szczerze mówiąc, masz dziś inne ryby do usmażenia. Oto: Prognozowany wynik ESPN dla jednego gościa to 7, dla drugiego 8. Idziesz z 8 i myślisz: „ten prognozowany wynik musi coś znaczyć, prawda?”
tl;dr Ten prognozowany wynik nie znaczy w zasadzie nic, a my możemy to pokazać, używając (nieudokumentowanego) API ESPN Fantasy i odrobiny Pythona.
Trochę tła
Mike Clay jest człowiekiem stojącym za kurtyną projekcji fantasy ESPN. Przysięga, że ma „długi proces”, który obejmuje „obliczenia statystyczne i subiektywne dane wejściowe.” Chodzi mi o to, że on zarabia, a ja piszę posty na blogu, więc nie mogę zbytnio nienawidzić tego tajemniczego procesu statystycznego.
Niezależnie od tego, istnieje wiele analiz porównujących projekcje ESPN z innymi stronami w całym spektrum, od intensywnych postów na reddicie do postów na blogu NYT.
Konsensus wydaje się być taki, że prognozy ESPN nie są zbyt dobre, w oparciu o wskaźniki takie jak „dokładność” i R-squared, które próbują określić ogólny błąd za pomocą pojedynczej statystyki podsumowującej.
Ale zauważyłem również, że jest bardzo mało informacji na temat tego, jak sprawdzić to dla siebie. Ta strona z footballanalytics.net łączy się z kilkoma świetnymi skryptami R, ale nie widziałem, aby jakikolwiek chwytał projekcje ESPN specjalnie (chociaż mogę się mylić).
Eksploracja …
ESPN utrzymuje jeden historyczny sezon projekcji w tej chwili, więc chwyćmy 2018 i zobaczmy, co znajdziemy.
Wykorzystamy ESPN Fantasy API, które opisuję jak używać tutaj.
W skrócie, zamierzamy wysłać ESPN to samo żądanie GET, które jego strona wysyła do własnych serwerów, gdy przechodzimy do strony z ligą historyczną. Możesz podsłuchać, jak te żądania są tworzone, używając narzędzi Web Developer w Safari lub usługi proxy, takiej jak Charles lub Fiddler.
Zanim napiszemy kod do pobrania wszystkich potrzebnych nam danych, zbadajmy mały kawałek tego:
import requestsswid = 'YOUR_SWID'espn_s2 = 'LONG_ESPN_S2_KEY'league_id = 123456season = 2018week = 5url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn})d = r.json()To jest wyjaśnione trochę bardziej szczegółowo w moim poprzednim poście, ale chodzi o to, że wysyłamy żądanie do API ESPN o konkretny widok na konkretną ligę, tydzień i sezon, który da nam pełną informację o matchupie/boxscore, łącznie z przewidywanymi punktami. Ciasteczka są potrzebne tylko dla lig prywatnych i ponownie, opisuję je tutaj.
Jeśli poruszasz się po strukturze JSON, zobaczysz, że każda drużyna fantasy ma roster swoich graczy, a każdy gracz ma listę swoich stats.
(Ponownie, dobrym sposobem na poruszanie się po tej strukturze jest użycie narzędzi Web Developer Safari: przejdź do interesującej strony w klubie Twojej ligi fantasy, otwórz narzędzia Web Developer, przejdź do Zasobów, następnie poszukaj pod XHRs obiektu z ID Twojej ligi. To będzie surowy tekst JSON … zmień „Response” na „JSON” w małym obszarze nagłówka, aby uzyskać bardziej przyjazny dla użytkownika interfejs w stylu eksploratora.)
Grabbing all 2018 Projections
To jest trochę ukryte, ale w tej podstrukturze znajdują się przewidywane i rzeczywiste punkty fantasy dla każdego gracza w każdym rosterze.
Zauważyłem, że lista stats dla danego zawodnika ma 5-6 wpisów, z których jeden jest zawsze wynikiem przewidywanym, a drugi rzeczywistym. Przewidywany wynik jest identyfikowany przez statSourceId=1, rzeczywisty przez statSourceId=0.
Użyjmy tej obserwacji do zbudowania zestawu pętli wysyłających żądania GET dla każdego tygodnia, a następnie wyodrębniających każdy przewidywany/aktualny wynik dla każdego gracza z każdego spisu.
import requestsimport pandas as pdleague_id = 123456season = 2018slotcodes = { 0 : 'QB', 2 : 'RB', 4 : 'WR', 6 : 'TE', 16: 'Def', 17: 'K', 20: 'Bench', 21: 'IR', 23: 'Flex'}url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'data = print('Week ', end='')for week in range(1, 17): print(week, end=' ') r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn}) d = r.json() for tm in d: tmid = tm for p in tm: name = p slot = p pos = slotcodes # injured status (need try/exc bc of D/ST) inj = 'NA' try: inj = p except: pass # projected/actual points proj, act = None, None for stat in p: if stat != week: continue if stat == 0: act = stat elif stat == 1: proj = stat data.append()print('\nComplete.')data = pd.DataFrame(data, columns=)Week 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Complete.Uzyskamy coś takiego:
data.head() Week Team Player Slot Pos Status Proj Actual0 1 1 Leonard Fournette 2 RB QUESTIONABLE 13.891825 5.01 1 1 Christian McCaffrey 2 RB ACTIVE 11.067053 7.02 1 1 Derrick Henry 20 Bench ACTIVE 10.271163 2.03 1 1 Josh Gordon 4 WR OUT 6.153141 7.04 1 1 Philip Rivers 0 QB QUESTIONABLE 26.212294 42.0Tak, tak, to są tylko gracze w rosterach, więc nie przechwytujemy żadnych wolnych agentów … ale to powinno przynajmniej dać nam poczucie dokładności prognoz ESPN, na razie.
Wykreślmy „Proj” przeciwko „Actual” dla kilku różnych pozycji i skrzyżujmy palce …
fig, axs = plt.subplots(1,3, sharey=True, figsize=(12, 4))for i, pos in enumerate(): (data .query('Pos == @pos') .pipe((axs.scatter, 'data'), x='Proj', y='Actual', s=50, c='b', alpha=0.5) ) axs.plot(, , 'k--') axs.set(xlim=, ylim=, xlabel='Projected', title=pos)axs.set_ylabel('Actual')plt.tight_layout()plt.show()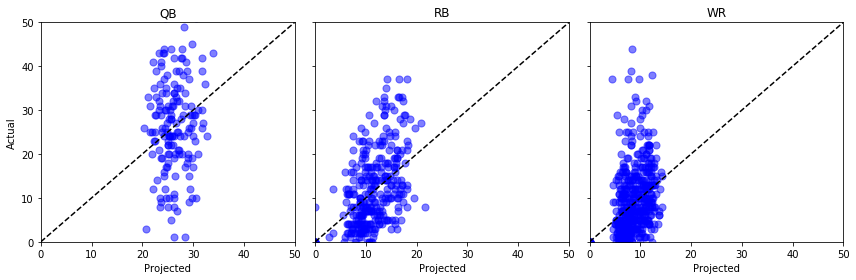
Um, nie za dobrze. Można by tu zrobić jakieś testy statystyczne, ale na moje niewprawne oko wygląda na to, że te przewidywane punkty równie dobrze mogą pochodzić z rozkładu jednostajnego.
Może w niektórych tygodniach jest lepiej? Może w dalszej części sezonu? Wykreślmy ogólny błąd, dla każdego tygodnia, dla każdej pozycji. Ten kod jest trochę skomplikowany 🙁 ale jestem gotów z tym żyć:
fig, axs = plt.subplots(1,3, sharey=True, figsize=(13,4))data = data - datadata = pd.cut(data, bins=4, labels=)cols = sns.color_palette('Blues')# dummy plots for a legendfor k,cat in enumerate(): axs.plot(,, c=cols, label='Wk ' + cat)axs.legend()for i, pos in enumerate(): for cat in range(4): t = data.query('Pos == @pos & Cat == @cat') sns.kdeplot(t, color=cols, ax=axs, legend=False) axs.set(xlabel='Actual - Proj', title=pos) plt.show()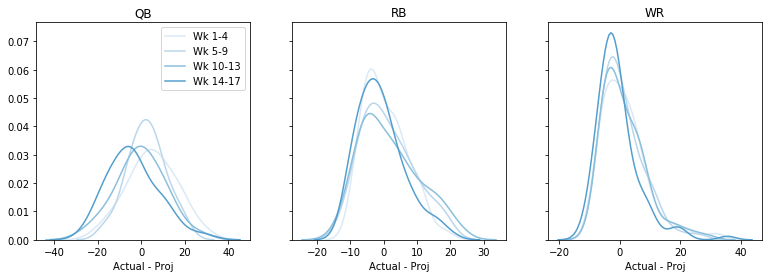
Może jest tendencja do przeprojektowywania w dalszej części sezonu, ale ogólnie rzecz biorąc, nie powiedziałbym, że tutaj też nic nie ma. (Zauważ, że przez to straciliśmy trochę informacji o tym, czy błąd jest większy czy mniejszy dla wysokich vs. niskich prognoz.)
Chciałbym spojrzeć na szeregi czasowe punktów zawodników. Zdrowy rozsądek podpowiada, że najlepszym sposobem na odgadnięcie co zawodnik będzie punktował w następnym tygodniu jest po prostu sprawdzenie jego ostatnich 4-5 tygodni… na ile jest to wiarygodna strategia?
W tym poście próbuję sprawdzić projekcje ESPN na poziomie rosteru – może indywidualne projekcje nie są imponujące, ale czy w sumie magicznie zaczynają pomagać? (Spoiler: nie bardzo.)
Napisane 5 sierpnia 2019 przez Steven Morse