C’est dimanche matin, les rosters sont sur le point de se verrouiller pour le slate du début d’après-midi, et vous êtes en train de décider entre deux WRs de neuvième rang pour ce slot WR3. C’est la semaine 3, ils sont tous les deux des choix désespérés de waiver wire que vous n’avez pas eu le temps de rechercher, et franchement, vous avez d’autres poissons à frire aujourd’hui. Voici : le score projeté par ESPN pour un gars est de 7, pour l’autre gars est de 8. Vous allez avec le 8 et pensez, « ce score projeté doit signifier quelque chose, non ? »
tl;dr Ce score projeté ne signifie essentiellement rien, et nous pouvons le montrer, en utilisant l’API ESPN Fantasy (non documentée) et un peu de Python.
Un peu de contexte
Mike Clay est l’homme derrière le rideau des projections fantaisistes d’ESPN. Il jure qu’il a un « long processus » qui implique « des calculs statistiques et des entrées subjectives. » Je veux dire qu’il est payé et que j’écris des articles de blog, alors je ne peux pas trop détester ce processus statistique mystérieux, quel qu’il soit.
Malgré tout, il y a eu de nombreuses analyses comparant les projections d’ESPN à d’autres sites sur tout le spectre, des articles intenses de reddit aux articles de blog de NYT.
Le consensus semble être, les projections d’ESPN ne sont pas très bonnes, sur la base de métriques comme la « précision » et le R-carré qui tentent de quantifier l’erreur globale avec une seule statistique sommaire.
Mais je remarque aussi qu’il y a très peu d’infos sur la façon de vérifier cela pour soi-même. Ce site de footballanalytics.net renvoie à quelques grands scripts R, mais je n’ai pas vu qu’aucun ne saisissait spécifiquement les projections d’ESPN (bien que je puisse me tromper).
Exploration …
ESPN maintient une saison historique de projections pour le moment, alors saisissons 2018 et voyons ce que nous trouvons.
Nous allons utiliser l’API ESPN Fantasy dont je couvre l’utilisation ici.
Nous allons, en résumé, envoyer à ESPN la même requête GET que son site web envoie à ses propres serveurs lorsque nous naviguons vers une page de ligue historique. Vous pouvez écouter comment ces requêtes sont formées en utilisant les outils Web Developer de Safari ou un service proxy comme Charles ou Fiddler.
Avant d’écrire du code pour récupérer toutes les données dont nous avons besoin, explorons-en un petit morceau :
import requestsswid = 'YOUR_SWID'espn_s2 = 'LONG_ESPN_S2_KEY'league_id = 123456season = 2018week = 5url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn})d = r.json()Ceci est expliqué un peu plus en détail dans mon précédent post, mais l’idée est que nous envoyons une requête à l’API d’ESPN pour une vue spécifique sur une ligue, une semaine et une saison spécifiques qui nous donnera des informations complètes sur les matchs/boxscore, y compris les points projetés. Les cookies ne sont nécessaires que pour les ligues privées, et encore une fois, je le couvre ici.
Si vous naviguez dans la structure JSON, vous constaterez que chaque équipe de fantasy a un roster de ses joueurs, et chaque joueur a une liste de ses stats.
(Encore une fois, une bonne façon de naviguer dans cette structure est avec les outils Web Developer de Safari : allez sur une page d’intérêt dans le clubhouse de votre ligue fantasy, ouvrez les outils Web Developer, allez dans Ressources, puis cherchez sous XHRs un objet avec votre ID de ligue. Ce sera le texte brut du JSON … changez « Response » en « JSON » dans la petite zone d’en-tête pour une interface de style explorateur plus conviviale.)
Atteindre toutes les projections 2018
C’est un peu caché, mais dans cette sous-structure se trouvent les points fantaisie projetés et réels pour chaque joueur sur chaque roster.
J’ai remarqué que la liste stats pour un joueur particulier a 5-6 entrées, dont une est toujours le score projeté et une autre est le réel. Le score projeté est identifié par statSourceId=1, le réel avec statSourceId=0.
Utilisons cette observation pour construire un ensemble de boucles pour envoyer des requêtes GET pour chaque semaine, puis extraire chaque score projeté/réel pour chaque joueur sur chaque roster.
import requestsimport pandas as pdleague_id = 123456season = 2018slotcodes = { 0 : 'QB', 2 : 'RB', 4 : 'WR', 6 : 'TE', 16: 'Def', 17: 'K', 20: 'Bench', 21: 'IR', 23: 'Flex'}url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'data = print('Week ', end='')for week in range(1, 17): print(week, end=' ') r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn}) d = r.json() for tm in d: tmid = tm for p in tm: name = p slot = p pos = slotcodes # injured status (need try/exc bc of D/ST) inj = 'NA' try: inj = p except: pass # projected/actual points proj, act = None, None for stat in p: if stat != week: continue if stat == 0: act = stat elif stat == 1: proj = stat data.append()print('\nComplete.')data = pd.DataFrame(data, columns=)Week 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Complete.Nous obtenons quelque chose comme ceci :
data.head() Week Team Player Slot Pos Status Proj Actual0 1 1 Leonard Fournette 2 RB QUESTIONABLE 13.891825 5.01 1 1 Christian McCaffrey 2 RB ACTIVE 11.067053 7.02 1 1 Derrick Henry 20 Bench ACTIVE 10.271163 2.03 1 1 Josh Gordon 4 WR OUT 6.153141 7.04 1 1 Philip Rivers 0 QB QUESTIONABLE 26.212294 42.0Oui, oui, il s’agit uniquement des joueurs sur les rosters, donc nous ne capturons aucun agent libre… mais cela devrait au moins nous donner une idée de la précision des projections d’ESPN, pour le moment.
Traçons « Proj » contre « Actual » pour quelques positions différentes et croisons les doigts …
fig, axs = plt.subplots(1,3, sharey=True, figsize=(12, 4))for i, pos in enumerate(): (data .query('Pos == @pos') .pipe((axs.scatter, 'data'), x='Proj', y='Actual', s=50, c='b', alpha=0.5) ) axs.plot(, , 'k--') axs.set(xlim=, ylim=, xlabel='Projected', title=pos)axs.set_ylabel('Actual')plt.tight_layout()plt.show()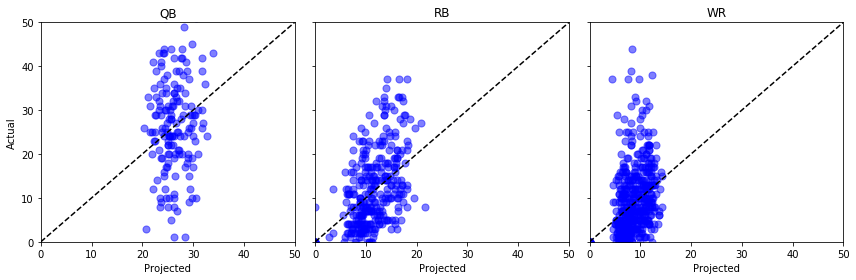
Um, pas génial. On pourrait faire des tests statistiques ici, mais à mon œil non exercé, il semble que ces points projetés pourraient aussi bien provenir d’une distribution uniforme.
Peut-être que c’est mieux certaines semaines ? Plus tard dans la saison, peut-être ? Traçons l’erreur globale, par semaine, par position. Ce code devient un peu hacky 🙁 mais je suis prêt à vivre avec :
fig, axs = plt.subplots(1,3, sharey=True, figsize=(13,4))data = data - datadata = pd.cut(data, bins=4, labels=)cols = sns.color_palette('Blues')# dummy plots for a legendfor k,cat in enumerate(): axs.plot(,, c=cols, label='Wk ' + cat)axs.legend()for i, pos in enumerate(): for cat in range(4): t = data.query('Pos == @pos & Cat == @cat') sns.kdeplot(t, color=cols, ax=axs, legend=False) axs.set(xlabel='Actual - Proj', title=pos) plt.show()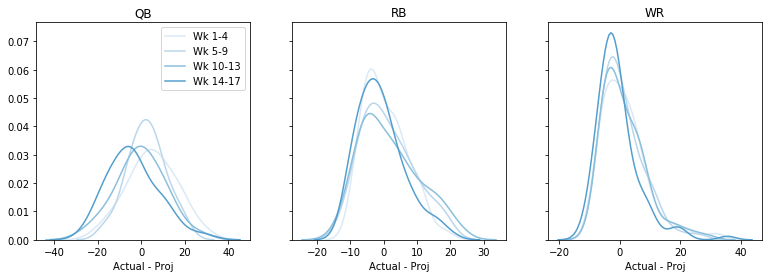
Peut-être y a-t-il une tendance à surprojeter plus tard dans la saison, mais globalement je ne dirais rien ici non plus. (Notez qu’en faisant cela, nous avons perdu certaines informations sur le fait que l’erreur est plus ou moins grande pour les projections élevées par rapport aux projections basses.)
J’aimerais ensuite examiner la série chronologique des points des joueurs. La sagesse du sens commun est que la meilleure façon de deviner ce qu’un joueur va marquer la semaine prochaine est juste de regarder ses 4-5 dernières semaines … quelle est la fiabilité de cette stratégie ?
Dans ce post, j’essaie de vérifier les projections ESPN au niveau du roster – peut-être que les projections individuelles ne sont pas impressionnantes, mais dans l’ensemble, commencent-elles magiquement à aider ? (Spoiler : pas vraiment.)
Écrit le 5 août 2019 par Steven Morse.