Au cours des 10 dernières années, on a assisté à une explosion de l’intérêt pour le » calcul scientifique » et la » science des données » : c’est-à-dire l’application du calcul pour répondre à des questions et analyser des données dans les sciences naturelles et sociales. Pour répondre à ces besoins, nous avons assisté à une renaissance des langages de programmation, des outils et des techniques qui aident les scientifiques et les chercheurs à explorer et à comprendre les données et les concepts scientifiques, et à communiquer leurs résultats. Mais jusqu’à présent, très peu d’outils se sont attachés à aider les scientifiques à accéder sans filtre à tout le potentiel de communication des navigateurs Web modernes. Aujourd’hui, nous sommes donc ravis de présenter Iodide, un outil expérimental destiné à aider les scientifiques à écrire de beaux documents interactifs à l’aide de technologies Web, le tout dans un flux de travail itératif qui ressemble à d’autres environnements de calcul scientifique.

Iodide en action.
Au delà d’être un simple environnement de programmation pour créer des documents vivants dans le navigateur, Iodide tente de supprimer la friction des flux de travail communicatifs en regroupant toujours l’outil d’édition avec le document lisible propre. Cette approche s’écarte des environnements de type IDE qui produisent des documents de présentation tels que des fichiers .pdf (qui sont ensuite séparés du code original) et des carnets de notes basés sur des cellules qui mélangent code et éléments de présentation. Dans Iodide, vous pouvez obtenir à la fois un document qui ressemble à ce que vous voulez, et un accès facile au code sous-jacent et à l’environnement d’édition.
Iodide est encore beaucoup dans un état alpha, mais suivant l’aphorisme d’Internet « Si vous n’êtes pas embarrassé par la première version de votre produit, vous avez lancé trop tard », nous avons décidé de faire un lancement doux très précoce dans l’espoir d’obtenir des commentaires d’une plus grande communauté. Nous disposons d’une démo que vous pouvez essayer dès maintenant, mais attendez-vous à ce qu’il y ait beaucoup d’aspérités (et s’il vous plaît, n’utilisez pas cette version alpha pour un travail critique !) Nous espérons que, malgré les bords rugueux, si vous louchez, vous serez en mesure de voir la valeur du concept, et que les commentaires que vous nous donnerez nous aideront à déterminer où aller ensuite.
- Comment nous sommes arrivés à Iodide
- Science des données à Mozilla
- Pourquoi y a-t-il si peu de web dans la science ?
- Vers l’iodure
- L’anatomie de Iodide
- Les vues Exploration et Rapport
- Des documents vivants et interactifs avec la puissance de la plateforme Web
- Partage, collaboration et reproductibilité
- Pyodide : La pile scientifique Python dans le navigateur
- JSMD (JavaScript MarkDown)
- Qu’est-ce qui va suivre ?
- Fonctionnalités collaboratives améliorées
- Plus de langages !
- Exporter l’archive du notebook
- Iodide to text editor browser extension
- Réaction et collaboration bienvenues !
- À propos de Brendan Colloran
Comment nous sommes arrivés à Iodide
Science des données à Mozilla
À Mozilla, la grande majorité de notre travail de science des données est axée sur la communication. Bien que nous déployions parfois des modèles destinés à améliorer directement l’expérience d’un utilisateur, comme le moteur de recommandation qui aide les utilisateurs à découvrir des extensions de navigateur, la plupart du temps, nos scientifiques des données analysent nos données afin de trouver et de partager des idées qui éclaireront les décisions des chefs de produit, des ingénieurs et des dirigeants.
Le travail de science des données implique d’écrire beaucoup de code, mais contrairement au développement logiciel traditionnel, notre objectif est de répondre à des questions, et non de produire des logiciels. Il en résulte généralement une sorte de rapport – un document, quelques graphiques, ou peut-être une visualisation interactive des données. Comme de nombreuses organisations de science des données, chez Mozilla, nous explorons nos données à l’aide d’outils fantastiques comme Jupyter et R-Studio. Cependant, quand il est temps de partager nos résultats, nous ne pouvons généralement pas remettre un carnet Jupyter ou un script R à un décideur, donc nous finissons souvent par faire des choses comme copier des chiffres clés et des statistiques récapitulatives dans un Google Doc.
Nous avons constaté que faire l’aller-retour entre l’exploration des données dans le code et la création d’une explication digeste et vice-versa n’est pas toujours facile. Les recherches montrent que de nombreuses personnes partagent cette expérience. Lorsqu’un spécialiste des données lit le rapport final d’un autre et souhaite consulter le code qui le sous-tend, il peut y avoir beaucoup de frictions ; il est parfois facile de retrouver le code, parfois non. S’il veut essayer d’expérimenter et d’étendre le code, les choses deviennent évidemment plus difficiles encore. Un autre data scientist peut avoir votre code, mais ne pas avoir une configuration identique sur sa machine, et mettre cela en place prend du temps.
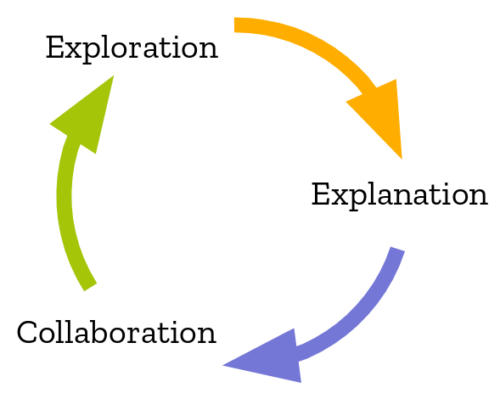
Le cercle vertueux du travail de data science.
Pourquoi y a-t-il si peu de web dans la science ?
Dans le contexte de ces workflows de data science chez Mozilla, fin 2017, j’ai entrepris un projet qui demandait une visualisation interactive des données. Aujourd’hui, vous pouvez créer des visualisations interactives en utilisant d’excellentes bibliothèques pour Python, R et Julia, mais pour ce que je voulais accomplir, j’avais besoin de descendre en Javascript. Cela signifiait s’éloigner de mes environnements de science des données préférés. Les outils de développement web modernes sont incroyablement puissants, mais extrêmement compliqués. Je ne voulais vraiment pas comprendre comment obtenir une chaîne d’outils de construction Javascript à part entière avec un rechargement de module à chaud, mais à part cela, je ne pouvais pas trouver grand-chose visant à créer des documents Web propres et lisibles dans le flux de travail itératif en direct qui m’est familier.
J’ai commencé à me demander pourquoi cet outil n’existait pas – pourquoi il n’y a pas de Jupyter pour la construction de documents Web interactifs – et j’ai rapidement fait un zoom arrière pour réfléchir à la raison pour laquelle presque personne n’utilise Javascript pour le calcul scientifique. Trois grandes raisons ont sauté aux yeux :
- Javascript lui-même a une réputation mitigée parmi les scientifiques pour être lent et maladroit ;
- il n’y a pas beaucoup de bibliothèques de calcul scientifique qui fonctionnent dans le navigateur ou qui fonctionnent avec Javascript ; et,
- comme je l’avais découvert, il y a très peu d’outils de codage scientifique qui permettent une boucle d’itération rapide et qui accordent également un accès non filtré aux capacités de présentation dans le navigateur.
Ce sont de très grands défis. Mais en y réfléchissant davantage, j’ai commencé à penser que travailler dans un navigateur pourrait avoir de réels avantages pour le type de science des données communicative que nous faisons à Mozilla. Le plus grand avantage, bien sûr, est que le navigateur possède sans doute l’ensemble de technologies de présentation le plus avancé et le mieux supporté de la planète, du DOM à WebGL en passant par Canvas et WebVR.
En réfléchissant à la friction du flux de travail mentionnée ci-dessus, un autre avantage potentiel m’est apparu : dans le navigateur, le document final n’a pas besoin d’être séparé de l’outil qui l’a créé. Je voulais un outil conçu pour aider les scientifiques à itérer sur des documents web (essentiellement des applications web à usage unique pour expliquer une idée)… et de nombreux outils que nous utilisions étaient eux-mêmes essentiellement des applications web. Pour le cas d’utilisation de l’écriture de ces petits documents d’application web, pourquoi ne pas regrouper le document avec l’outil utilisé pour l’écrire ?
En faisant cela, les lecteurs non techniques pourraient voir mon beau document, mais les autres scientifiques de données pourraient instantanément revenir au code original. De plus, puisque le noyau de calcul serait le moteur JS du navigateur, ils seraient en mesure de commencer à étendre et à expérimenter avec le code d’analyse immédiatement. Et ils pourraient faire tout cela sans se connecter à des ressources informatiques distantes ou installer un quelconque logiciel.
Vers l’iodure
J’ai commencé à discuter des avantages et des inconvénients potentiels du calcul scientifique dans le navigateur avec mes collègues, et au cours de nos conversations, nous avons remarqué d’autres tendances intéressantes.
À l’intérieur de Mozilla, nous voyions beaucoup de démos intéressantes montrant WebAssembly, une nouvelle façon pour les navigateurs d’exécuter du code écrit dans des langages autres que Javascript. WebAssembly permet d’exécuter des programmes à une vitesse incroyable, dans certains cas proche des binaires natifs. Nous avons vu des exemples de processus coûteux en calcul, comme des moteurs de jeu 3D entiers, s’exécuter sans difficulté dans le navigateur. À l’avenir, il sera possible de compiler les meilleures bibliothèques de calcul numérique C et C++ dans WebAssembly et de les intégrer dans des API JS ergonomiques, tout comme le fait le projet SciPy pour Python. En effet, des projets avaient déjà commencé à le faire.
WebAssembly permet d’exécuter du code à une vitesse quasi-native dans le navigateur.
Nous avons également remarqué la volonté de la communauté Javascript d’introduire une nouvelle syntaxe lorsque cela aide les gens à résoudre leur problème plus efficacement. Peut-être serait-il possible d’émuler certains des éléments syntaxiques clés qui rendent la programmation numérique plus compréhensible et plus fluide dans MATLAB, Julia et Python – multiplication de matrices, découpage multidimensionnel, opérations de diffusion de tableaux, etc. Encore une fois, nous avons trouvé d’autres personnes qui pensaient dans le même sens.
Avec la convergence de ces fils, nous avons commencé à nous demander si la plateforme web pourrait être sur le point de devenir un foyer productif pour le calcul scientifique. À tout le moins, il semblait qu’elle pourrait évoluer pour servir certains des flux de travail communicatifs que nous rencontrons à Mozilla (et que tant d’autres rencontrent dans l’industrie et le milieu universitaire). Avec le noyau de Javascript qui s’améliore sans cesse et la possibilité d’ajouter des extensions syntaxiques pour la programmation numérique, peut-être que JS lui-même pourrait être rendu plus attrayant pour les scientifiques. WebAssembly semblait offrir une voie vers de grandes bibliothèques scientifiques. Le troisième pied du tabouret serait un environnement permettant de créer des documents de science des données pour le web. C’est sur ce dernier élément que nous avons décidé de concentrer notre expérimentation initiale, ce qui nous a amené à Iodide.
L’anatomie de Iodide
Iodide est un outil conçu pour donner aux scientifiques un flux de travail familier pour créer de superbes documents interactifs en utilisant toute la puissance de la plateforme web. Pour ce faire, nous vous donnons un « rapport » – essentiellement une page web que vous pouvez remplir avec votre contenu – et quelques outils pour explorer itérativement les données et modifier votre rapport pour créer quelque chose que vous êtes prêt à partager. Une fois que vous êtes prêt, vous pouvez envoyer un lien directement vers votre rapport finalisé. Si vos collègues et collaborateurs souhaitent revoir votre code et en tirer des enseignements, ils peuvent repasser en mode exploration en un clic. S’ils veulent expérimenter avec le code et l’utiliser comme base de leur propre travail, avec un clic de plus, ils peuvent le forker et commencer à travailler sur leur propre version.
Lisez la suite pour en savoir un peu plus sur certaines des idées que nous expérimentons pour tenter de rendre ce flux de travail fluide.
Les vues Exploration et Rapport
Iodide vise à resserrer la boucle entre exploration, explication et collaboration. Au centre de cela, il y a la possibilité de faire des allers-retours entre une belle écriture et un environnement utile pour l’exploration informatique itérative.
Lorsque vous créez pour la première fois un nouveau carnet Iodide, vous démarrez dans la « vue d’exploration ». Cela fournit un ensemble de volets, y compris un éditeur pour écrire du code, une console pour visualiser la sortie du code que vous évaluez, un visualiseur d’espace de travail pour examiner les variables que vous avez créées pendant votre session, et un volet « aperçu du rapport » dans lequel vous pouvez voir un aperçu de votre rapport.

Modification d’un fragment de code Markdown dans la vue d’exploration de Iodide.
En cliquant sur le bouton « REPORT » dans le coin supérieur droit, le contenu de l’aperçu de votre rapport s’étendra pour remplir toute la fenêtre, ce qui vous permettra de mettre l’histoire que vous voulez raconter en avant et au centre. Les lecteurs qui ne savent pas coder ou qui ne sont pas intéressés par les détails techniques peuvent se concentrer sur ce que vous essayez de transmettre sans avoir à parcourir le code. Lorsqu’un lecteur visite le lien vers la vue du rapport, votre code s’exécute automatiquement. S’il souhaite revoir votre code, il lui suffit de cliquer sur le bouton « EXPLORER » en haut à droite pour revenir à la vue explorée. De là, ils peuvent faire une copie du carnet pour leurs propres explorations.

Passer de la vue explorer à la vue rapport.
Chaque fois que vous partagez un lien vers un carnet Iodide, votre collaborateur peut toujours accéder à ces deux vues. Le document propre et lisible n’est jamais séparé du code exécutable sous-jacent et de l’environnement d’édition en direct.
Des documents vivants et interactifs avec la puissance de la plateforme Web
Les documents Iodide vivent dans le navigateur, ce qui signifie que le moteur de calcul est toujours disponible. Chaque fois que vous partagez votre travail, vous partagez un rapport interactif en direct avec du code en cours d’exécution. De plus, comme le calcul se fait dans le navigateur en même temps que la présentation, il n’est pas nécessaire d’appeler un backend de langage dans un autre processus. Cela signifie que les documents interactifs se mettent à jour en temps réel, ouvrant la possibilité de visualisations 3D transparentes, même avec la faible latence et le débit d’images élevé requis pour la RV.

Le contributeur Devin Bayly explore les données IRM de son cerveau
Partage, collaboration et reproductibilité
Construire Iodide dans le web simplifie un certain nombre d’éléments de friction du flux de travail que nous avons rencontrés dans d’autres outils. Le partage est simplifié parce que l’écriture et le code sont disponibles à la même URL plutôt que, disons, de coller un lien vers un script dans les notes de bas de page d’un Google Doc. La collaboration est simplifiée parce que le noyau de calcul est le navigateur et que les bibliothèques peuvent être chargées via une requête HTTP comme n’importe quelle page web charge un script – aucun langage, bibliothèque ou outil supplémentaire ne doit être installé. Et parce que les navigateurs fournissent une couche de compatibilité, vous n’avez pas à vous soucier de la reproductibilité du comportement des carnets de notes à travers les ordinateurs et les OS.
Pour soutenir les flux de travail collaboratifs, nous avons construit un serveur assez simple pour enregistrer et partager les carnets de notes. Il existe une instance publique à iodide.io où vous pouvez expérimenter avec Iodide et partager votre travail publiquement. Il est également possible de mettre en place votre propre instance derrière un pare-feu (c’est d’ailleurs ce que nous faisons déjà à Mozilla pour certains travaux internes). Mais ce qui est important, c’est que les notebooks eux-mêmes ne sont pas profondément liés à une seule instance du serveur Iodide. Si le besoin s’en fait sentir, il devrait être facile de migrer votre travail vers un autre serveur ou d’exporter votre notebook sous forme de bundle pour le partager sur d’autres services comme Netlify ou Github Pages (plus d’informations sur l’exportation de bundles ci-dessous dans la section « What’s next ? »). Garder le calcul dans le client nous permet de nous concentrer sur la construction d’un environnement vraiment génial pour le partage et la collaboration, sans avoir besoin de construire des ressources de calcul dans le cloud.
Lorsque nous avons commencé à penser à rendre le web meilleur pour les scientifiques, nous nous sommes concentrés sur les moyens de rendre le travail avec Javascript meilleur, comme compiler les bibliothèques scientifiques existantes en WebAssembly et les envelopper dans des API JS faciles à utiliser. Lorsque nous avons proposé cela aux assistants WebAssembly de Mozilla, ils ont offert une idée plus ambitieuse : si de nombreux scientifiques préfèrent Python, rencontrons-les là où ils sont en compilant la pile scientifique Python pour qu’elle s’exécute dans WebAssembly.
Nous pensions que cela semblait décourageant – que ce serait un énorme projet et que cela ne donnerait jamais des performances satisfaisantes… mais deux semaines plus tard, Mike Droettboom avait une implémentation fonctionnelle de Python fonctionnant à l’intérieur d’un notebook Iodide. Au cours des deux mois suivants, nous avons ajouté Numpy, Pandas et Matplotlib, qui sont de loin les modules les plus utilisés dans l’écosystème scientifique Python. Avec l’aide des contributeurs Kirill Smelkov et Roman Yurchak de Nexedi, nous avons obtenu le support de Scipy et scikit-learn. Depuis lors, nous avons continué à ajouter d’autres bibliothèques petit à petit.
Exécuter l’interpréteur Python à l’intérieur d’une machine virtuelle Javascript ajoute une pénalité de performance, mais cette pénalité s’avère être étonnamment faible – dans nos benchmarks, environ 1x-12x plus lent que natif sur Firefox et 1x-16x plus lent sur Chrome. L’expérience montre que cela est très utilisable pour l’exploration interactive.

Exécuter Matplotlib dans le navigateur permet ses fonctionnalités interactives, qui ne sont pas disponibles dans les environnements statiques
Amener Python dans le navigateur crée quelques flux de travail magiques. Par exemple, vous pouvez importer et nettoyer vos données en Python, puis accéder aux objets Python résultants depuis Javascript (dans la plupart des cas, la conversion se fait automatiquement) afin de pouvoir les afficher à l’aide de bibliothèques JS comme d3. Encore plus magiquement, vous pouvez accéder aux API du navigateur à partir du code Python, ce qui vous permet de faire des choses comme manipuler le DOM sans toucher à Javascript.
Bien sûr, il y a beaucoup plus à dire sur Pyodide, et il mérite un article à part entière – nous entrerons dans les détails dans un post de suivi le mois prochain.
JSMD (JavaScript MarkDown)
Comme dans Jupyter et le mode R-Markdown de R, dans Iodide vous pouvez entrelacer le code et l’écriture comme vous le souhaitez, en divisant votre code en « morceaux de code » que vous pouvez modifier et exécuter comme des unités distinctes. Notre mise en œuvre de cette idée est parallèle au « mode cellule » de R Markdown et MATLAB : plutôt que d’utiliser une interface explicitement basée sur les cellules, le contenu d’un carnet Iodide est simplement un document texte qui utilise une syntaxe spéciale pour délimiter des types spécifiques de cellules. Nous appelons ce format de texte « JSMD ».
Suivant MATLAB, les chunks de code sont définis par des lignes commençant par %% suivies d’une chaîne indiquant la langue du chunk situé en dessous. Nous supportons actuellement les chunks contenant du Javascript, du CSS, du Markdown (et du HTML), du Python, un chunk spécial « fetch » qui simplifie le chargement des ressources, et un chunk plugin qui vous permet d’étendre les fonctionnalités de Iodide en ajoutant de nouveaux types de cellules.
Nous avons trouvé ce format assez pratique. Il facilite l’utilisation d’outils orientés texte comme les visualiseurs diff et votre propre éditeur de texte préféré, et vous pouvez effectuer des opérations de texte standard comme couper/copier/coller sans avoir à apprendre des raccourcis pour la gestion des cellules. Pour plus de détails, vous pouvez lire sur JSMD dans nos docs.
Qu’est-ce qui va suivre ?
Il est utile de répéter que nous sommes toujours en alpha, donc nous allons continuer à améliorer la polish globale et écraser les bugs. Mais en plus de cela, nous avons un certain nombre de fonctionnalités en tête pour notre prochaine série d’expérimentations. Si l’une de ces idées vous semble particulièrement utile, faites-le nous savoir ! Encore mieux, faites-nous savoir si vous aimeriez nous aider à les construire !
Fonctionnalités collaboratives améliorées
Comme mentionné ci-dessus, jusqu’à présent nous avons construit un backend très simple qui vous permet de sauvegarder votre travail en ligne, de regarder le travail effectué par d’autres personnes, et de forker et étendre rapidement les carnets existants faits par d’autres utilisateurs, mais ce ne sont que les étapes initiales d’un flux de travail collaboratif utile.
Les trois prochaines grandes fonctionnalités de collaboration que nous envisageons d’ajouter sont :
- Les fils de commentaires de style Google Docs
- La possibilité de suggérer des modifications au carnet d’un autre utilisateur via un flux de travail fork/merge similaire aux pull requests de Github
- L’édition simultanée de carnets comme Google Docs.
À ce stade, nous leur donnons la priorité à peu près dans cet ordre, mais si vous les abordez dans un ordre différent ou si vous avez d’autres suggestions, faites-le nous savoir !
Plus de langages !
Nous avons parlé aux gens des communautés R et Julia de la compilation de ces langages en WebAssembly, ce qui permettrait leur utilisation dans Iodide et d’autres projets basés sur un navigateur. Notre enquête initiale indique que cela devrait être faisable, mais que la mise en œuvre de ces langages pourrait être un peu plus difficile que Python. Comme avec Python, des flux de travail intéressants s’ouvrent si vous pouvez, par exemple, ajuster des modèles statistiques en R ou résoudre des équations différentielles en Julia, puis afficher vos résultats à l’aide d’API de navigateur. Si apporter ces langages sur le web vous intéresse, n’hésitez pas à nous contacter – en particulier, nous aimerions avoir l’aide d’experts en FORTRAN et LLVM.
Exporter l’archive du notebook
Les premières versions de Iodide étaient des fichiers HTML exécutables autonomes, qui comprenaient à la fois le code JSMD utilisé dans l’analyse et le code JS utilisé pour exécuter Iodide lui-même, mais nous nous sommes éloignés de cette architecture. Des expériences ultérieures nous ont convaincus que les avantages de la collaboration avec un serveur Iodide l’emportent sur les avantages de la gestion des fichiers sur votre système local. Néanmoins, ces expériences nous ont montré qu’il est possible de prendre un instantané exécutable d’un notebook Iodide en insérant le code Iodide ainsi que toutes les données et bibliothèques utilisées par un notebook dans un grand fichier HTML. Cela pourrait finir par être un fichier plus gros que ce que vous voudriez servir aux utilisateurs réguliers, mais il pourrait s’avérer utile comme un instantané parfaitement reproductible et archivable d’une analyse.
Iodide to text editor browser extension
Bien que de nombreux scientifiques soient assez habitués à travailler dans des environnements de programmation basés sur un navigateur, nous savons que certaines personnes ne modifieront jamais le code dans autre chose que leur éditeur de texte préféré. Nous voulons vraiment que Iodide rencontre les gens là où ils sont déjà, y compris ceux qui préfèrent taper leur code dans un autre éditeur mais qui veulent avoir accès aux fonctionnalités interactives et itératives qu’offre Iodide. Pour répondre à ce besoin, nous avons commencé à réfléchir à la création d’une extension légère pour navigateur et de quelques API simples pour permettre à Iodide de parler aux éditeurs côté client.
Réaction et collaboration bienvenues !
Nous n’essayons pas de résoudre tous les problèmes de la science des données et du calcul scientifique, et nous savons que Iodide ne sera pas la tasse de thé de tout le monde. Si vous avez besoin de traiter des téraoctets de données sur des clusters GPU, Iodide n’a probablement pas grand-chose à vous offrir. Si vous publiez des articles de journaux et que vous avez juste besoin de rédiger un document LaTeX, il existe de meilleurs outils pour répondre à vos besoins. Si l’idée d’amener les choses dans le navigateur vous fait un peu peur, pas de problème – il existe une foule d’outils vraiment étonnants que vous pouvez utiliser pour faire de la science, et nous en sommes reconnaissants ! Nous ne voulons pas changer la façon dont les gens travaillent, et pour de nombreux scientifiques, la communication sur le web n’est pas un problème. Rad ! Vivez votre meilleure vie !
Mais pour les scientifiques qui produisent du contenu pour le web, et pour ceux qui pourraient aimer le faire si vous aviez des outils conçus pour soutenir votre façon de travailler : nous aimerions vraiment avoir de vos nouvelles !
Venez visiter iodide.io, essayez-le, et donnez-nous vos commentaires (mais encore une fois : gardez à l’esprit que ce projet est en phase alpha – s’il vous plaît ne l’utilisez pas pour tout travail critique, et soyez conscient que pendant que nous sommes en alpha tout est sujet à changement). Vous pouvez répondre à notre sondage rapide, et les problèmes et rapports de bogue sur Github sont les bienvenus. Les demandes de fonctionnalités et les réflexions sur la direction générale peuvent être partagées via notre groupe Google ou Gitter.
Si vous souhaitez vous impliquer pour nous aider à construire Iodide, nous sommes open source sur Github. Iodide touche une grande variété de disciplines logicielles, du développement frontal moderne au calcul scientifique en passant par la compilation et la transpilation, donc il y a beaucoup de choses intéressantes à faire ! N’hésitez pas à nous contacter si cela vous intéresse !
Enormes remerciements à Hamilton Ulmer, William Lachance et Mike Droettboom pour leur excellent travail sur Iodide et pour avoir revu cet article.
À propos de Brendan Colloran
Plus d’articles par Brendan Colloran…