Introduction
Tout ce qu’est un compilateur, c’est juste un programme. Le programme prend une entrée (qui est le code source – aka un fichier d’octets ou de données) et produit généralement un programme d’apparence complètement différente, qui est maintenant exécutable ; contrairement à l’entrée.
Sur la plupart des systèmes d’exploitation modernes, les fichiers sont organisés en tableaux unidimensionnels d’octets. Le format d’un fichier est défini par son contenu puisqu’un fichier est uniquement un conteneur de données, bien que, sur certaines plateformes, le format soit généralement indiqué par son extension de nom de fichier, spécifiant les règles pour la façon dont les octets doivent être organisés et interprétés de manière significative. Par exemple, les octets d’un fichier texte brut (
.txtsous Windows) sont associés aux caractères ASCII ou UTF-8, tandis que les octets des fichiers image, vidéo et audio sont interprétés autrement. (Wikipedia)
(https://en.wikipedia.org/wiki/Computer_file#File_contents)
Le compilateur prend votre code source lisible par l’homme, l’analyse, puis produit un code lisible par l’ordinateur appelé code machine (binaire). Certains compilateurs vont (au lieu de passer directement au code machine) passer à l’assemblage, ou à un autre langage lisible par l’homme.
Les langages lisibles par l’homme sont des langages dits de haut niveau. Un compilateur qui passe d’un langage de haut niveau à un autre langage de haut niveau est appelé compilateur source à source, transcompilateur ou transpilateur.
(https://en.wikipedia.org/wiki/Source-to-source_compiler)
int main() {
int a = 5;
a = a * 5;
return 0;
}
Ce qui précède est un programme C écrit par un humain qui fait ce qui suit dans un langage plus simple, encore plus lisible par l’homme, appelé pseudo-code :
program 'main' returns an integer
begin
store the number '5' in the variable 'a'
'a' equals 'a' times '5'
return '0'
end
Le pseudo-code est une description informelle de haut niveau du principe de fonctionnement d’un programme informatique ou d’un autre algorithme. (Wikipedia)
(https://en.wikipedia.org/wiki/Pseudocode)
Nous allons compiler ce programme C en code assembleur de style Intel, comme le fait un compilateur. Bien qu’un ordinateur doive être spécifique et suivre des algorithmes pour déterminer ce qui fait des mots, des entiers et des symboles ; nous pouvons simplement utiliser le bon sens. Cela à son tour, rend notre désambiguïsation beaucoup plus courte que pour un compilateur.
Cette analyse est simplifiée pour faciliter la compréhension.
Tokénisation
Avant qu’un ordinateur puisse déchiffrer un programme, il doit d’abord diviser chaque symbole en son propre jeton. Un token est l’idée d’un caractère, ou d’un groupement de caractères, à l’intérieur d’un fichier source. Ce processus est appelé tokenisation, et il est effectué par un tokenizer.
Notre code source original serait divisé en tokens et conservé à l’intérieur de la mémoire d’un ordinateur. Je vais essayer de transmettre la mémoire de l’ordinateur dans le diagramme suivant de la production du tokenizer.
Avant:
int main() {
int a = 5;
a = a * 5;
return 0;
}
Après:
Le diagramme est formaté à la main pour la lisibilité. En réalité, il ne serait pas indenté ou divisé par ligne.
Comme vous pouvez le voir, il crée une forme très littérale de ce qui lui a été donné. Vous devriez être en mesure de presque reproduire le code source original en ne donnant que les tokens. Les tokens doivent conserver un type, et si le type peut avoir plus d’une valeur, le token doit également contenir la valeur correspondante.
Les tokens eux-mêmes ne sont pas suffisants pour compiler. Nous devons connaître le contexte, et ce que ces tokens signifient lorsqu’ils sont mis ensemble. Cela nous amène à l’analyse syntaxique, où nous pouvons donner un sens à ces tokens.
Parsing
La phase d’analyse syntaxique prend les tokens et produit un arbre syntaxique abstrait, ou AST. Il décrit essentiellement la structure du programme, et peut être utilisé pour déterminer comment il est exécuté, d’une manière très – comme son nom l’indique – abstraite. C’est très similaire à quand vous faisiez des arbres de grammaire en anglais au collège.
Le parseur finit généralement par être la partie la plus complexe du compilateur. Les analyseurs syntaxiques sont complexes et nécessitent beaucoup de travail et de compréhension. C’est pourquoi il existe de nombreux programmes qui peuvent générer un analyseur complet en fonction de la façon dont vous le décrivez.
Ces » outils de création d’analyseurs » sont appelés générateurs d’analyseurs. Les générateurs de parseurs sont spécifiques aux langues, car ils génèrent le parseur dans le code de cette langue. Bison (C/C++) est l’un des générateurs d’analyseur syntaxique les plus connus au monde.
L’analyseur syntaxique, en bref, tente de faire correspondre les tokens à des modèles de tokens déjà définis. Par exemple, nous pourrions dire que l’affectation prend la forme suivante de tokens, en utilisant EBNF:
EBNF (ou un dialecte, de celui-ci) est couramment utilisé dans les générateurs de parseurs pour définir la grammaire.
assignment = identifier, equals, int | identifier ;
Les modèles de tokens suivants sont considérés comme une affectation:
a = 5
or
a = a
or
b = 123456789
Mais les modèles suivants ne le sont pas, même s’ils devraient l’être:
int a = 5
or
a = a * 5
Ceux qui ne fonctionnent pas ne sont pas impossibles, mais nécessitent plutôt un développement et une complexité supplémentaires à l’intérieur de l’analyseur syntaxique avant de pouvoir être implémentés entièrement.
Lisez l’article suivant de Wikipédia si vous êtes plus intéressé par le fonctionnement des analyseurs syntaxiques. https://en.wikipedia.org/wiki/Parsing
Théoriquement, après que notre analyseur syntaxique ait fini d’analyser, il générerait un arbre syntaxique abstrait comme le suivant :
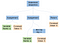
En informatique, un arbre syntaxique abstrait (AST), ou simplement arbre syntaxique, est une représentation arborescente de la structure syntaxique abstraite du code source écrit dans un langage de programmation. (Wikipédia)
(https://en.wikipedia.org/wiki/Abstract_syntax_tree)
Après que l’arbre syntaxique abstrait ait établi l’ordre d’exécution de haut niveau, et les opérations à effectuer, il devient assez simple de commencer à générer du code d’assemblage.
Génération de code
Puisque l’AST contient des branches qui définissent presque entièrement le programme, nous pouvons avancer dans ces branches, en générant séquentiellement l’assemblage équivalent. Ceci est appelé « walking the tree », et c’est un algorithme pour la génération de code en utilisant un AST.
La génération de code immédiatement après le parsing n’est pas commune pour les compilateurs plus complexes, car ils passent par plus de phases avant d’avoir un AST final, comme l’intermédiaire, l’optimisation, etc. Il y a plus de techniques pour la génération de code.
https://en.wikipedia.org/wiki/Code_generation_(compiler)
Nous compilons vers l’assemblage parce qu’un seul assembleur peut produire du code machine pour une, ou quelques architectures de CPU différentes. Par exemple, si notre compilateur générait l’assemblage NASM, nos programmes seraient compatibles avec les architectures Intel x86 (16 bits, 32 bits et 64 bits). La compilation directe en code machine ne serait pas aussi efficace, car nous devrions écrire un backend pour chaque architecture cible indépendamment. Bien que, ce serait assez long, et avec moins de gain que l’utilisation d’un assembleur tiers.
Avec LLVM, vous pouvez juste compiler vers LLVM IR et il gère le reste. Il compile jusqu’à un large éventail de langages assembleurs, et compile donc sur beaucoup plus d’architectures. Si vous avez déjà entendu parler de LLVM, vous voyez probablement pourquoi elle est si chérie, maintenant.
https://en.wikipedia.org/wiki/LLVM
Si nous devions descendre dans les branches de la séquence d’instructions, nous trouverions toutes les instructions qui sont exécutées de gauche à droite. Nous pouvons descendre ces branches de gauche à droite, en plaçant le code d’assemblage équivalent. Chaque fois que nous terminons une branche, nous devons remonter et commencer à travailler sur une nouvelle branche.
La branche la plus à gauche de notre séquence d’instructions contient la première affectation à une nouvelle variable entière, a. La valeur assignée est une feuille qui contient la valeur intégrale constante, 5. Semblable à la branche la plus à gauche, la branche du milieu est une affectation. Elle assigne l’opération binaire (bin op) de multiplication entre a et 5, à a . Pour simplifier, nous référençons simplement a deux fois à partir du même nœud, plutôt que d’avoir deux nœuds a.
La dernière branche est juste un retour et elle est destinée au code de sortie du programme. Nous disons à l’ordinateur qu’il est sorti normalement en retournant zéro.
Ce qui suit est la production du compilateur GNU C (x86-64 GCC 8.1) étant donné notre code source n’utilisant aucune optimisation.
N’oubliez pas que le compilateur n’a pas généré les commentaires ou les espacements.
main:
push rbp
mov rbp, rsp
mov DWORD PTR , 5 ; leftmost branch
mov edx, DWORD PTR ; middle branch
mov eax, edx
sal eax, 2
add eax, edx
mov DWORD PTR , eax
mov eax, 0 ; rightmost branch
pop rbp
ret
Un outil génial ; le Compiler Explorer de Matt Godbolt, vous permet d’écrire du code et de voir les productions d’assemblage du compilateur en temps réel. Essayez notre expérience à https://godbolt.org/g/Uo2Z5E.
Le générateur de code tente généralement d’optimiser le code d’une certaine manière. Nous n’utilisons techniquement jamais notre variable a. Même si nous l’assignons, nous ne la relisons jamais. Un compilateur devrait reconnaître cela et finalement supprimer la variable entière dans la production finale de l’assemblage. Notre variable est restée parce que nous n’avons pas compilé avec des optimisations.
Vous pouvez ajouter des arguments au compilateur sur l’explorateur de compilateur.
-O3est un drapeau pour GCC qui signifie une optimisation maximale. Essayez de l’ajouter, et voyez ce qui arrive au code généré.
Après que le code d’assemblage ait été généré, nous pouvons compiler l’assemblage vers le code machine, en utilisant un assembleur. Le code machine ne fonctionne que pour l’architecture unique du processeur cible. Pour cibler une nouvelle architecture, nous devons ajouter cette architecture cible d’assemblage pour qu’elle puisse être produite par notre générateur de code.
L’assembleur que vous utilisez pour compiler l’assemblage en code machine est également écrit dans un langage de programmation. Il pourrait même être écrit dans son propre langage d’assemblage. Écrire un compilateur dans le langage qu’il compile est appelé amorçage.
https://en.wikipedia.org/wiki/Bootstrapping_(compilers)
Conclusion
Les compilateurs prennent du texte, l’analysent et le traitent, puis le transforment en binaire pour que votre ordinateur puisse le lire. Cela vous évite d’avoir à écrire manuellement du binaire pour votre ordinateur, et de plus, vous permet d’écrire des programmes complexes plus facilement.
Matière de fond
Et c’est tout ! Nous avons tokenisé, analysé et généré notre code source. J’espère que vous avez une meilleure compréhension des ordinateurs et des logiciels après avoir lu ceci. Si vous ne comprenez toujours pas, consultez les ressources d’apprentissage que j’ai listées en bas de page. Je n’ai jamais compris tout cela après avoir lu un seul article. Si vous avez des questions, regardez si quelqu’un d’autre les a déjà posées avant d’aller dans la section des commentaires.