Det er søndag morgen, rosters er ved at blive låst til den tidlige eftermiddag skifer, og du beslutter dig mellem to niende tier WRs for at WR3 slot. Det er uge 3, de er begge waiver wire desperation picks, som du ikke har haft tid til at undersøge, og ærlig talt har du andre fisk at fiske i dag. Se: ESPN Projected score for den ene fyr er 7, for den anden fyr er 8. Du vælger 8 og tænker: “Den forventede score må da betyde noget, ikke?”
tl;dr Den forventede score betyder stort set ingenting, og vi kan vise det ved hjælp af den (udokumenterede) ESPN Fantasy API og lidt Python.
En lille baggrund
Mike Clay er manden bag gardinet for ESPN’s fantasy-projektioner. Han sværger, at han har en “langvarig proces”, der involverer “statistiske beregninger og subjektive input”. Jeg mener, han bliver betalt, og jeg skriver blogindlæg, så jeg kan ikke hade for meget på, hvad denne mystiske statistiske proces end måtte være.
Uanset hvad, så har der været mange analyser, der sammenligner ESPN’s fremskrivninger med andre sites over hele spektret fra intense reddit-indlæg til NYT-blogindlæg.
Konsensus synes at være, at ESPN’s fremskrivninger ikke er særlig gode, baseret på målinger som “accuracy” og R-squared, der forsøger at kvantificere den samlede fejl med en enkelt summarisk statistik.
Men jeg bemærker også, at der er meget lidt info om, hvordan man selv kan tjekke dette. Dette websted fra footballanalytics.net linker til nogle gode R-scripts, men jeg så ikke, at nogen tager fat i ESPN-projektioner specifikt (selvom jeg kan tage fejl).
Udforskning …
ESPN vedligeholder en historisk sæson af projektioner i øjeblikket, så lad os tage fat i 2018 og se, hvad vi finder.
Vi vil gøre brug af ESPN Fantasy API, som jeg dækker hvordan man bruger her.
Vi vil kort fortalt sende ESPN den samme GET-forespørgsel, som deres hjemmeside sender til deres egne servere, når vi navigerer til en historisk ligaside. Du kan aflytte, hvordan disse anmodninger bliver dannet ved at bruge Safari’s Web Developer-værktøjer eller en proxytjeneste som Charles eller Fiddler.
Hvor vi skriver kode til at hente alle de data, vi har brug for, skal vi udforske et lille stykke af det:
import requestsswid = 'YOUR_SWID'espn_s2 = 'LONG_ESPN_S2_KEY'league_id = 123456season = 2018week = 5url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn})d = r.json()Dette er forklaret lidt mere detaljeret i mit tidligere indlæg, men idéen er, at vi sender en anmodning til ESPN’s API for at få en specifik visning af en specifik liga, uge og sæson, der giver os fuld matchup/boxscore-info, herunder forventede point. Cookies er kun nødvendige for private ligaer, og igen, jeg dækker det her.
Hvis du navigerer gennem JSON-strukturen, vil du opdage, at hvert fantasyhold har en roster af sine spillere, og hver spiller har en liste over sine stats.
(Igen er en god måde at navigere rundt i denne struktur på med Safari’s Web Developer-værktøjer: Gå til en side af interesse i din fantasy-ligaens klubhus, åbn Web Developer-værktøjer, gå til Ressourcer, og kig derefter under XHR’er efter et objekt med dit liga-id. Dette vil være råteksten i JSON … skift “Response” til “JSON” i det lille header-område for at få en mere brugervenlig grænseflade i explorer-stil)
Grabbing all 2018 Projections
Det er lidt skjult, men i denne understruktur er de forventede og faktiske fantasypoint for hver spiller på hver roster.
Jeg lagde mærke til, at stats-listen for en bestemt spiller har 5-6 poster, hvoraf den ene altid er den forventede pointscore og den anden er den faktiske. Den forventede score identificeres med statSourceId=1, den faktiske med statSourceId=0.
Lad os bruge denne observation til at opbygge et sæt sløjfer til at sende GET-forespørgsler for hver uge og derefter udtrække hver forventet/aktuel score for hver spiller på hver liste.
import requestsimport pandas as pdleague_id = 123456season = 2018slotcodes = { 0 : 'QB', 2 : 'RB', 4 : 'WR', 6 : 'TE', 16: 'Def', 17: 'K', 20: 'Bench', 21: 'IR', 23: 'Flex'}url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'data = print('Week ', end='')for week in range(1, 17): print(week, end=' ') r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn}) d = r.json() for tm in d: tmid = tm for p in tm: name = p slot = p pos = slotcodes # injured status (need try/exc bc of D/ST) inj = 'NA' try: inj = p except: pass # projected/actual points proj, act = None, None for stat in p: if stat != week: continue if stat == 0: act = stat elif stat == 1: proj = stat data.append()print('\nComplete.')data = pd.DataFrame(data, columns=)Week 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Complete.Vi får noget i denne retning:
data.head() Week Team Player Slot Pos Status Proj Actual0 1 1 Leonard Fournette 2 RB QUESTIONABLE 13.891825 5.01 1 1 Christian McCaffrey 2 RB ACTIVE 11.067053 7.02 1 1 Derrick Henry 20 Bench ACTIVE 10.271163 2.03 1 1 Josh Gordon 4 WR OUT 6.153141 7.04 1 1 Philip Rivers 0 QB QUESTIONABLE 26.212294 42.0Ja, ja, det er kun spillere på rosters, så vi fanger ikke nogen free agents … men det burde i det mindste give os en fornemmelse af nøjagtigheden af ESPN’s fremskrivninger, for nu.
Lad os plotte “Proj” mod “Actual” for et par forskellige positioner og krydse fingre …
fig, axs = plt.subplots(1,3, sharey=True, figsize=(12, 4))for i, pos in enumerate(): (data .query('Pos == @pos') .pipe((axs.scatter, 'data'), x='Proj', y='Actual', s=50, c='b', alpha=0.5) ) axs.plot(, , 'k--') axs.set(xlim=, ylim=, xlabel='Projected', title=pos)axs.set_ylabel('Actual')plt.tight_layout()plt.show()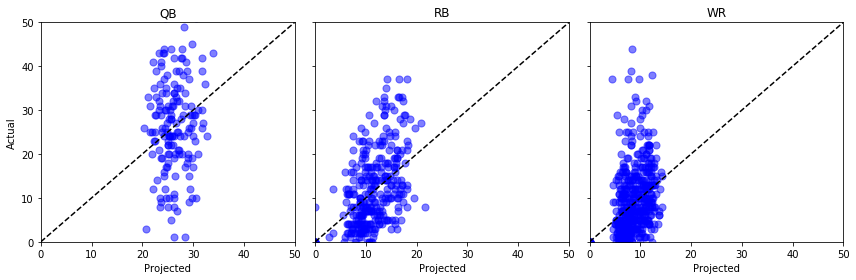
Um, ikke fantastisk. Vi kunne lave nogle statistiske tests her, men for mit utrænede øje ser det ud til, at de fremskrevne point lige så godt kunne komme fra en ensartet fordeling.
Måske er det bedre på visse uger? Senere på sæsonen måske? Lad os plotte den samlede fejl, pr. uge, pr. position. Denne kode bliver lidt hacky 🙁 men jeg er parat til at leve med det:
fig, axs = plt.subplots(1,3, sharey=True, figsize=(13,4))data = data - datadata = pd.cut(data, bins=4, labels=)cols = sns.color_palette('Blues')# dummy plots for a legendfor k,cat in enumerate(): axs.plot(,, c=cols, label='Wk ' + cat)axs.legend()for i, pos in enumerate(): for cat in range(4): t = data.query('Pos == @pos & Cat == @cat') sns.kdeplot(t, color=cols, ax=axs, legend=False) axs.set(xlabel='Actual - Proj', title=pos) plt.show()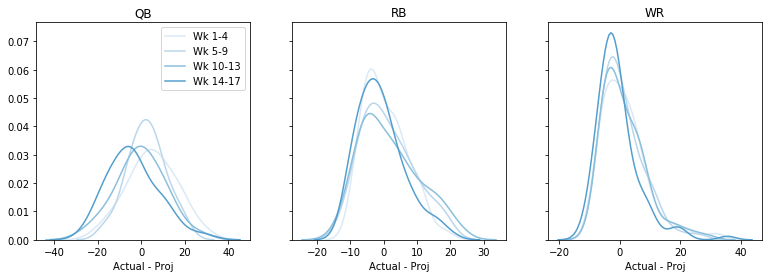
Måske er der en tendens til at overprojektere senere på sæsonen, men overordnet set vil jeg heller ikke sige noget her. (Bemærk ved at gøre dette mistede vi noget information om, hvorvidt fejlen er større eller mindre for høje vs. lave fremskrivninger.)
Jeg vil gerne se på tidsserier af spillernes point som det næste. Den sunde fornuft siger, at den bedste måde at gætte på, hvad en spiller vil score i næste uge, er ved bare at øjenhøjde hans sidste 4-5 uger … hvor pålidelig en strategi er det?
I dette indlæg prøver jeg at tjekke ESPN-projektioner på roster-niveau – måske er de individuelle projektioner ikke imponerende, men samlet set begynder de så på magisk vis at hjælpe? (Spoiler: ikke rigtig.)
Skrevet d. 5. august 2019 af Steven Morse