Indledning
Alt en compiler er bare et program. Programmet tager et input (som er kildekoden – også kaldet en fil med bytes eller data) og producerer som regel et helt anderledes udseende program, som nu er eksekverbart; i modsætning til input.
På de fleste moderne styresystemer er filer organiseret i endimensionale arrays af bytes. Formatet af en fil er defineret af dens indhold, da en fil udelukkende er en beholder for data, selv om formatet på nogle platforme normalt angives af filnavnets udvidelse, der angiver reglerne for, hvordan bytes skal organiseres og fortolkes meningsfuldt. F.eks. er bytes i en almindelig tekstfil (
.txti Windows) forbundet med enten ASCII- eller UTF-8-tegn, mens bytes i billed-, video- og lydfiler fortolkes på anden måde. (Wikipedia)
(https://en.wikipedia.org/wiki/Computer_file#File_contents)
Compileren tager din menneskeligt læsbare kildekode, analyserer den og producerer derefter en computerlæsbar kode kaldet maskinkode (binær kode). Nogle compilere vil (i stedet for at gå direkte til maskinkode) gå til assembler eller et andet menneskeligt læsbart sprog.
Menneskeligt læsbare sprog er AKA højniveausprog. En compiler, der går fra et højniveausprog til et andet højniveausprog, kaldes en source-to-source-compiler, transcompiler eller transpiler.
(https://en.wikipedia.org/wiki/Source-to-source_compiler)
int main() {
int a = 5;
a = a * 5;
return 0;
}
Overstående er et C-program skrevet af et menneske, der gør følgende i et enklere, endnu mere menneskeligt læsbart sprog kaldet pseudokode:
program 'main' returns an integer
begin
store the number '5' in the variable 'a'
'a' equals 'a' times '5'
return '0'
end
Pseudokode er en uformel beskrivelse på højt niveau af driftsprincippet for et computerprogram eller en anden algoritme. (Wikipedia)
(https://en.wikipedia.org/wiki/Pseudocode)
Vi vil kompilere dette C-program til assemblerkode i Intel-stil, ligesom en compiler gør det. Selv om en computer skal være specifik og følge algoritmer for at bestemme, hvad der udgør ord, hele tal og symboler; kan vi bare bruge vores sunde fornuft. Det gør til gengæld vores disambiguering meget kortere end for en compiler.
Denne analyse er forenklet for at lette forståelsen.
Tokenisering
Hvor en computer kan dechifrere et program, skal den først splitte hvert symbol op i sit eget token. Et token er ideen om et tegn, eller en gruppering af tegn, inde i en kildefil. Denne proces kaldes tokenisering, og den udføres af en tokenizer.
Vores oprindelige kildekode ville blive delt op i tokens og opbevaret inde i en computers hukommelse. Jeg vil forsøge at formidle computerens hukommelse i det følgende diagram over tokenizerens produktion.
For:
int main() {
int a = 5;
a = a * 5;
return 0;
}
Efter:
Diagrammet er håndformateret for at gøre det lettere at læse. I virkeligheden ville det ikke være indrykket eller opdelt efter linje.
Som du kan se, skaber det en meget bogstavelig form af det, der blev givet til det. Du burde være i stand til næsten at replikere den originale kildekode, hvis du kun får tokens. Tokens bør bevare en type, og hvis typen kan have mere end én værdi, bør tokenet også indeholde den tilsvarende værdi.
Tokensene i sig selv er ikke nok til at kompilere. Vi skal kende konteksten, og hvad disse tokens betyder, når de sættes sammen. Det bringer os til parsing, hvor vi kan give mening til disse tokens.
Parsing
Parsing-fasen tager tokens og producerer et abstrakt syntaksetræ, eller AST. Det beskriver i bund og grund programmets struktur og kan bruges til at bestemme, hvordan det udføres, på en meget – som navnet antyder – abstrakt måde. Det svarer meget til dengang man lavede grammatiske træer i engelsk på mellemtrinnet.
Den parser ender som regel med at være den mest komplekse del af compileren. Parsere er komplekse og kræver meget hårdt arbejde og forståelse. Derfor findes der masser af programmer, der kan generere en hel parser, afhængigt af hvordan du beskriver den.
Disse “parser-skaberværktøjer” kaldes parsergeneratorer. Parsergeneratorer er specifikke for sprog, da de genererer parseren i det pågældende sprogs kode. Bison (C/C++) er en af de mest kendte parsergeneratorer i verden.
Parserne forsøger kort sagt at matche tokens med allerede definerede mønstre af tokens. Vi kan f.eks. sige, at assignment tager følgende form af tokens ved hjælp af EBNF:
EBNF (eller en dialekt heraf) er almindeligt anvendt i parsergeneratorer til at definere grammatikken.
assignment = identifier, equals, int | identifier ;
Men følgende mønstre af tokens betragtes som en tildeling:
a = 5
or
a = a
or
b = 123456789
Men følgende mønstre er det ikke, selv om de burde være det:
int a = 5
or
a = a * 5
De, der ikke fungerer, er ikke umulige, men kræver snarere yderligere udvikling og kompleksitet inde i parseren, før de kan implementeres helt.
Læs følgende Wikipedia-artikel, hvis du er interesseret i mere om, hvordan parsere fungerer. https://en.wikipedia.org/wiki/Parsing
Theoretisk set ville vores parser, når den er færdig med at parsere, generere et abstrakt syntaksetræ som følgende:
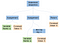
I datalogi er et abstrakt syntaksetræ (AST), eller blot syntaksetræ, en trærepræsentation af den abstrakte syntaktiske struktur af kildekode skrevet i et programmeringssprog. (Wikipedia)
(https://en.wikipedia.org/wiki/Abstract_syntax_tree)
Når det abstrakte syntaksetræ udstikker eksekveringsrækkefølgen på højt niveau og de operationer, der skal udføres, bliver det ret ligetil at begynde at generere assemblerkode.
Kodegenerering
Da AST’et indeholder grene, der næsten udelukkende definerer programmet, kan vi træde gennem disse grene og sekventielt generere den tilsvarende assemblerkode. Dette kaldes “walking the tree”, og det er en algoritme til kodegenerering ved hjælp af en AST.
Kodegenerering umiddelbart efter parsing er ikke almindeligt for mere komplekse compilere, da de går gennem flere faser, før de har en endelig AST, såsom mellemliggende, optimering osv. Der findes flere teknikker til kodegenerering.
https://en.wikipedia.org/wiki/Code_generation_(compiler)
Vi kompilerer til assembler, fordi en enkelt assembler kan producere maskinkode til enten en, eller et par forskellige CPU-arkitekturer. Hvis vores compiler f.eks. genererede NASM-assembler, ville vores programmer være kompatible med Intel x86-arkitekturer (16-bit, 32-bit og 64-bit). Kompilering direkte til maskinkode ville ikke være lige så effektiv, fordi vi ville være nødt til at skrive en backend til hver målarkitektur uafhængigt af hinanden. Selv om det ville være ret tidskrævende og med mindre gevinst end at bruge en assembler fra en tredjepart.
Med LLVM kan man bare kompilere til LLVM IR, og så klarer den resten. Den kompilerer ned til en lang række assembler-sprog, og kompilerer dermed til mange flere arkitekturer. Hvis du har hørt om LLVM før, kan du sikkert se, hvorfor det er så værdsat, nu.
https://en.wikipedia.org/wiki/LLVM
Hvis vi skulle træde ind i statementsekvensens grene, ville vi finde alle de statements, der køres fra venstre mod højre. Vi kan træde ned i disse grene fra venstre til højre og placere den tilsvarende assemblerkode. Hver gang vi afslutter en gren, skal vi gå tilbage op og begynde at arbejde på en ny gren.
Den yderste venstre gren i vores statement-sekvens indeholder den første tildeling til en ny heltalsvariabel, a. Den tildelte værdi er et blad, der indeholder den konstante integralværdi, 5. I lighed med den yderste venstre gren er den midterste gren en tildeling. Den tildeler den binære operation (bin op) for multiplikation mellem a og 5, til a . For enkelhedens skyld refererer vi blot a to gange fra samme knudepunkt, i stedet for at have to a-knuder.
Den sidste gren er blot en retur, og den er til programmets udgangskode. Vi fortæller computeren, at den er afsluttet normalt ved at returnere nul.
Det følgende er produktionen fra GNU C Compiler (x86-64 GCC 8.1) givet vores kildekode uden optimeringer.
Husk, compileren har ikke genereret kommentarerne eller mellemrummene.
main:
push rbp
mov rbp, rsp
mov DWORD PTR , 5 ; leftmost branch
mov edx, DWORD PTR ; middle branch
mov eax, edx
sal eax, 2
add eax, edx
mov DWORD PTR , eax
mov eax, 0 ; rightmost branch
pop rbp
ret
Et fantastisk værktøj; Compiler Explorer af Matt Godbolt, giver dig mulighed for at skrive kode og se compilerens assembly-produktioner i realtid. Prøv vores eksperiment på https://godbolt.org/g/Uo2Z5E.
Den kodegenerator forsøger normalt at optimere koden på en eller anden måde. Vi bruger teknisk set aldrig vores variabel a. Selv om vi tildeler den, læser vi den aldrig igen. En compiler bør erkende dette og i sidste ende fjerne hele variablen i den endelige assemblerproduktion. Vores variabel blev i, fordi vi ikke kompilerede med optimeringer.
Du kan tilføje argumenter til compileren på Compiler Explorer.
-O3er et flag for GCC, der betyder maksimal optimering. Prøv at tilføje det, og se, hvad der sker med den genererede kode.
Når assemblerkoden er blevet genereret, kan vi kompilere assemblerkoden ned til maskinkode ved hjælp af en assembler. Maskinkoden fungerer kun for den enkelte mål-CPU-arkitektur. Hvis vi vil målrette en ny arkitektur, skal vi tilføje denne assembler-målarkitektur til at kunne produceres af vores kodegenerator.
Den assembler, du bruger til at kompilere assembleren ned til maskinkode, er også skrevet i et programmeringssprog. Den kunne endda være skrevet i sit eget assembler-sprog. At skrive en compiler i det sprog, den kompilerer, kaldes bootstrapping.
https://en.wikipedia.org/wiki/Bootstrapping_(compilers)
Konklusion
Compilere tager tekst, analyserer og behandler den og omdanner den derefter til binær kode, som din computer kan læse. Dette forhindrer dig i at skulle skrive binære filer manuelt til din computer og gør det desuden nemmere for dig at skrive komplekse programmer.
Backmatter
Og det var det! Vi tokeniserede, parsede og genererede vores kildekode. Jeg håber, at du har fået en større forståelse for computere og software efter at have læst dette. Hvis du stadig er forvirret, skal du bare tjekke nogle af de læringsressourcer, som jeg har listet nederst på siden. Jeg havde aldrig forstået alt dette efter at have læst én artikel. Hvis du har spørgsmål, så se efter, om andre allerede har stillet det, før du tager til kommentarfeltet.