Det är söndagsmorgon, rosters är på väg att låsa för den tidiga eftermiddagen slate, och du bestämmer mellan två nionde tier WRs för att WR3 plats. Det är vecka 3, båda är desperationsplock från waiver wire som du inte har haft tid att undersöka, och ärligt talat har du andra saker att göra i dag. Se: ESPN:s Projected score för den ena killen är 7, för den andra killen är 8. Du väljer 8 och tänker: ”Det där Projected score måste betyda något, eller hur?”
tl;dr Det där Projected score betyder i princip ingenting, och vi kan visa det med hjälp av det (odokumenterade) ESPN Fantasy API:et och lite Python.
En liten bakgrund
Mike Clay är mannen bakom ridån för ESPN:s fantasyprojektioner. Han svär att han har en ”långvarig process” som innefattar ”statistiska beräkningar och subjektiva indata”. Jag menar att han får betalt och jag skriver blogginlägg, så jag kan inte hata för mycket om vad denna mystiska statistiska process än må vara.
Oavsett detta har det gjorts många analyser där ESPN:s prognoser har jämförts med andra sajter över hela spektrumet från intensiva reddit-inlägg till NYT-blogginlägg.
Konsensus verkar vara att ESPN:s prognoser inte är särskilt bra, baserat på mått som ”noggrannhet” och R-kvadrat som försöker kvantifiera det totala felet med hjälp av en enda sammanfattande statistik.
Men jag märker också att det finns väldigt lite information om hur man kan kontrollera detta själv. Den här webbplatsen från footballanalytics.net länkar till några bra R-skript, men jag såg inte att någon tar tag i ESPN-projektioner specifikt (även om jag kan ha fel).
Exploring …
ESPN upprätthåller en historisk säsong av projektioner för tillfället, så låt oss ta tag i 2018 och se vad vi hittar.
Vi kommer att använda oss av ESPN Fantasy API som jag täcker hur man använder här.
Vi kommer i korthet att skicka ESPN samma GET-förfrågan som dess webbplats skickar till sina egna servrar när vi navigerar till en historisk ligasida. Du kan tjuvlyssna på hur dessa förfrågningar utformas genom att använda Safaris Web Developer-verktyg eller en proxytjänst som Charles eller Fiddler.
Innan vi skriver kod för att hämta all data vi behöver, ska vi utforska en liten del av den:
import requestsswid = 'YOUR_SWID'espn_s2 = 'LONG_ESPN_S2_KEY'league_id = 123456season = 2018week = 5url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn})d = r.json()Detta förklaras lite mer i detalj i mitt tidigare inlägg, men idén är att vi skickar en förfrågan till ESPN:s API för att få en specifik vy över en specifik liga, vecka och säsong som kommer att ge oss fullständig matchup/boxscore-information inklusive prognostiserade poäng. Cookies behövs bara för privata ligor, och återigen täcker jag det här.
Om du navigerar genom JSON-strukturen kommer du att upptäcka att varje fantasilag har en roster av sina spelare, och varje spelare har en lista med sina stats.
(Återigen, ett trevligt sätt att navigera runt i den här strukturen är med Safaris verktyg för webbutvecklare: gå till en intressant sida i din fantasiligas klubbstuga, öppna verktygen för webbutvecklare, gå till Resurser och leta sedan under XHRs efter ett objekt med ditt liga-ID. Detta kommer att vara den råa texten i JSON … ändra ”Response” till ”JSON” i det lilla rubrikområdet för ett mer användarvänligt gränssnitt i explorer-stil.)
Grabbing all 2018 Projections
Det är lite dolt, men inom den här understrukturen finns de prognostiserade och faktiska fantasipoängen för varje spelare på varje roster.
Jag lade märke till att stats-listan för en viss spelare har 5-6 poster, varav en alltid är den projicerade poängen och en annan är den faktiska. Den beräknade poängen identifieras med statSourceId=1, den faktiska med statSourceId=0.
Låt oss använda denna observation för att bygga en uppsättning slingor för att skicka GET-förfrågningar för varje vecka och sedan extrahera varje beräknad/aktuell poäng för varje spelare på varje lista.
import requestsimport pandas as pdleague_id = 123456season = 2018slotcodes = { 0 : 'QB', 2 : 'RB', 4 : 'WR', 6 : 'TE', 16: 'Def', 17: 'K', 20: 'Bench', 21: 'IR', 23: 'Flex'}url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'data = print('Week ', end='')for week in range(1, 17): print(week, end=' ') r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn}) d = r.json() for tm in d: tmid = tm for p in tm: name = p slot = p pos = slotcodes # injured status (need try/exc bc of D/ST) inj = 'NA' try: inj = p except: pass # projected/actual points proj, act = None, None for stat in p: if stat != week: continue if stat == 0: act = stat elif stat == 1: proj = stat data.append()print('\nComplete.')data = pd.DataFrame(data, columns=)Week 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Complete.Vi får något liknande:
data.head() Week Team Player Slot Pos Status Proj Actual0 1 1 Leonard Fournette 2 RB QUESTIONABLE 13.891825 5.01 1 1 Christian McCaffrey 2 RB ACTIVE 11.067053 7.02 1 1 Derrick Henry 20 Bench ACTIVE 10.271163 2.03 1 1 Josh Gordon 4 WR OUT 6.153141 7.04 1 1 Philip Rivers 0 QB QUESTIONABLE 26.212294 42.0Ja, ja, det här är bara spelare på rosters, så vi fångar inga fria agenter … men det borde åtminstone ge oss en känsla av noggrannheten i ESPN:s prognoser, för tillfället.
Låt oss ställa ”Proj” mot ”Actual” för några olika positioner och hålla tummarna …
fig, axs = plt.subplots(1,3, sharey=True, figsize=(12, 4))for i, pos in enumerate(): (data .query('Pos == @pos') .pipe((axs.scatter, 'data'), x='Proj', y='Actual', s=50, c='b', alpha=0.5) ) axs.plot(, , 'k--') axs.set(xlim=, ylim=, xlabel='Projected', title=pos)axs.set_ylabel('Actual')plt.tight_layout()plt.show()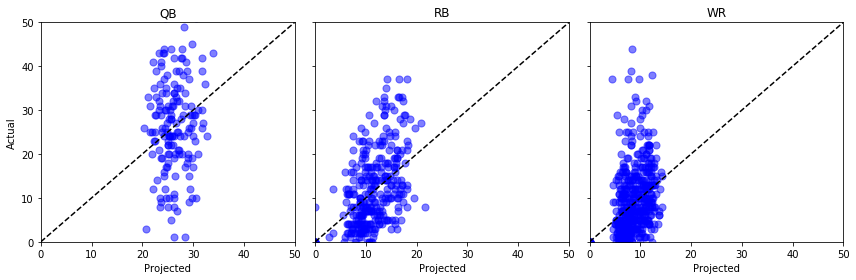
Um, inte bra. Vi skulle kunna göra några statistiska tester här, men för mitt otränade öga ser det ut som om dessa beräknade poäng lika gärna skulle kunna komma från en jämn fördelning.
Kanske är det bättre på vissa veckor? Senare på säsongen kanske? Låt oss rita upp det totala felet, per vecka, per position. Den här koden blir lite hackig 🙁 men jag är beredd att leva med den:
fig, axs = plt.subplots(1,3, sharey=True, figsize=(13,4))data = data - datadata = pd.cut(data, bins=4, labels=)cols = sns.color_palette('Blues')# dummy plots for a legendfor k,cat in enumerate(): axs.plot(,, c=cols, label='Wk ' + cat)axs.legend()for i, pos in enumerate(): for cat in range(4): t = data.query('Pos == @pos & Cat == @cat') sns.kdeplot(t, color=cols, ax=axs, legend=False) axs.set(xlabel='Actual - Proj', title=pos) plt.show()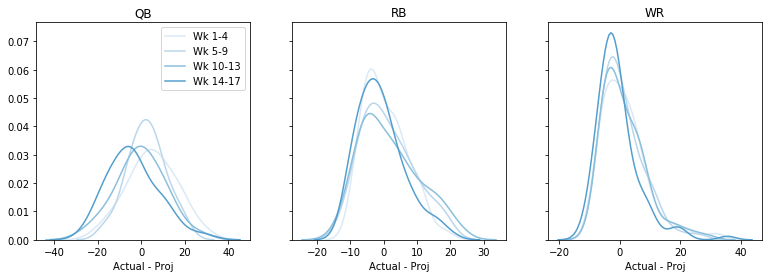
Kanske finns det en tendens att överprojektera senare på säsongen, men överlag skulle jag inte säga något här heller. (Observera att vi genom att göra detta förlorade en del information om huruvida felet är större eller mindre för höga respektive låga prognoser.)
Jag skulle vilja titta på tidsserier av spelarnas poäng härnäst. Det sunda förnuftet säger att det bästa sättet att gissa vad en spelare kommer att göra för poäng nästa vecka är att bara öga på hans senaste 4-5 veckor … hur pålitlig strategi är detta?
I det här inlägget försöker jag kontrollera ESPN:s projektioner på en rosternivå – kanske är de individuella projektionerna inte imponerande, men i sin helhet börjar de magiskt sett hjälpa till? (Spoiler: inte riktigt.)
Skrivet den 5 augusti 2019 av Steven Morse