Inledning
Allt en kompilator är, är bara ett program. Programmet tar en inmatning (som är källkoden – även kallad en fil med bytes eller data) och producerar i allmänhet ett helt annorlunda program som nu är körbart, till skillnad från inmatningen.
I de flesta moderna operativsystem är filer organiserade i endimensionella matriser av bytes. Formatet för en fil definieras av dess innehåll eftersom en fil endast är en behållare för data, även om formatet på vissa plattformar vanligtvis anges av filnamnstillägget, vilket specificerar reglerna för hur bytena måste organiseras och tolkas på ett meningsfullt sätt. Bytes i en vanlig textfil (
.txti Windows) är till exempel associerade med antingen ASCII- eller UTF-8-tecken, medan bytes i bild-, video- och ljudfiler tolkas på annat sätt. (Wikipedia)
(https://en.wikipedia.org/wiki/Computer_file#File_contents)
Kompilatorn tar din människoläsbara källkod, analyserar den och producerar sedan en datorläsbar kod som kallas maskinkod (binär). Vissa kompilatorer går (i stället för att gå direkt till maskinkod) till assembler eller ett annat människoläsbart språk.
Människoläsbara språk är så kallade högnivåspråk. En kompilator som går från ett högnivåspråk till ett annat högnivåspråk kallas en kompilator från källa till källa, transkompilator eller transpiler.
(https://en.wikipedia.org/wiki/Source-to-source_compiler)
int main() {
int a = 5;
a = a * 5;
return 0;
}
Ovanstående är ett C-program skrivet av en människa som gör följande på ett enklare, ännu mer människoläsbart språk som kallas pseudokod:
program 'main' returns an integer
begin
store the number '5' in the variable 'a'
'a' equals 'a' times '5'
return '0'
end
Pseudokod är en informell beskrivning på hög nivå av funktionsprincipen för ett datorprogram eller annan algoritm. (Wikipedia)
(https://en.wikipedia.org/wiki/Pseudocode)
Vi kommer att kompilera detta C-program till Intel-stil assemblerkod precis som en kompilator gör. Även om en dator måste vara specifik och följa algoritmer för att avgöra vad som utgör ord, heltal och symboler; kan vi bara använda sunt förnuft. Det i sin tur gör vår disambiguering mycket kortare än för en kompilator.
Denna analys är förenklad för att underlätta förståelsen.
Tokenisering
För att en dator ska kunna tyda ett program måste den först dela upp varje symbol till en egen token. En token är idén om ett tecken, eller en gruppering av tecken, inne i en källfil. Denna process kallas tokenisering och görs av en tokenizer.
Vår ursprungliga källkod skulle delas upp i tokens och förvaras inuti en dators minne. Jag ska försöka förmedla datorns minne i följande diagram över tokenizerns produktion.
För:
int main() {
int a = 5;
a = a * 5;
return 0;
}
Efter:
Diagrammet är handformaterat för läsbarhetens skull. I verkligheten skulle det inte vara indraget eller uppdelat per rad.
Som du kan se skapar det en mycket bokstavlig form av det som gavs till det. Du bör nästan kunna replikera den ursprungliga källkoden med hjälp av endast tokens. Token ska behålla en typ, och om typen kan ha mer än ett värde ska tokenet också innehålla motsvarande värde.
Tokenet i sig är inte tillräckligt för att kompilera. Vi måste känna till sammanhanget och veta vad dessa tokens betyder när de sätts ihop. Det för oss till parsing, där vi kan göra dessa tokens begripliga.
Parsing
Parsingfasen tar tokens och producerar ett abstrakt syntaxträd, eller AST. Det beskriver i huvudsak programmets struktur och kan användas för att bestämma hur det ska exekveras, på ett mycket – som namnet antyder – abstrakt sätt. Det påminner mycket om när man gjorde grammatiska träd i engelska på mellanstadiet.
Den parsern slutar i allmänhet med att vara den mest komplexa delen av kompilatorn. Parsers är komplexa och kräver mycket hårt arbete och förståelse. Det är därför det finns massor av program som kan generera en hel parser beroende på hur du beskriver den.
Dessa ”parser creator tools” kallas parser generators. Parsergeneratorer är specifika för språk, eftersom de genererar parsern i det språkets kod. Bison (C/C++) är en av de mest kända parsergeneratorerna i världen.
Parseraren försöker i korthet matcha tecken till redan definierade mönster av tecken. Vi kan till exempel säga att assignment tar följande form av tokens, med hjälp av EBNF:
EBNF (eller en dialekt därav) används vanligen i parsergeneratorer för att definiera grammatiken.
assignment = identifier, equals, int | identifier ;
Men följande mönster av tokens anses vara en assignment:
a = 5
or
a = a
or
b = 123456789
Men följande mönster är inte det, även om de borde vara det:
int a = 5
or
a = a * 5
De som inte fungerar är inte omöjliga, utan kräver snarare ytterligare utveckling och komplexitet inne i parsern innan de kan implementeras helt.
Läs följande Wikipedia-artikel om du är mer intresserad av hur parsers fungerar. https://en.wikipedia.org/wiki/Parsing
Teoretiskt sett skulle vår parser, när den är klar med parsingen, generera ett abstrakt syntaxträd som följande:
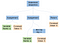
I datavetenskap är ett abstrakt syntaxträd (abstract syntax tree, AST), eller bara syntaxträd, en trädrepresentation av den abstrakta syntaktiska strukturen i källkod skriven i ett programmeringsspråk. (Wikipedia)
(https://en.wikipedia.org/wiki/Abstract_syntax_tree)
När det abstrakta syntaxträdet lägger ut exekveringsordningen på hög nivå och de operationer som ska utföras blir det ganska okomplicerat att börja generera assemblerkod.
Kodgenerering
Då AST innehåller grenar som nästan helt och hållet definierar programmet kan vi gå igenom dessa grenar och sekventiellt generera motsvarande assemblerkod. Detta kallas ”walking the tree” och är en algoritm för kodgenerering med hjälp av en AST.
Kodgenerering omedelbart efter parsing är inte vanligt för mer komplexa kompilatorer, eftersom de går igenom fler faser innan de har en slutgiltig AST, till exempel mellanliggande, optimering osv. Det finns fler tekniker för kodgenerering.
https://en.wikipedia.org/wiki/Code_generation_(compiler)
Vi kompilerar till assembler eftersom en enda assembler kan producera maskinkod för antingen en, eller några olika CPU-arkitekturer. Om vår kompilator till exempel genererade NASM-assembler skulle våra program vara kompatibla med Intel x86-arkitekturer (16-bitar, 32-bitar och 64-bitar). Att kompilera direkt till maskinkod skulle inte vara lika effektivt, eftersom vi skulle behöva skriva en backend för varje målarkitektur oberoende av varandra. Även om det skulle vara ganska tidskrävande, och med mindre vinst än att använda en tredjepartsassembler.
Med LLVM kan man bara kompilera till LLVM IR och den sköter resten. Den kompilerar ner till ett stort antal assemblerspråk och kompilerar därmed till många fler arkitekturer. Om du har hört talas om LLVM tidigare förstår du förmodligen varför det är så omhuldat, nu.
https://en.wikipedia.org/wiki/LLVM
Om vi skulle kliva in i statementsekvensens grenar skulle vi hitta alla statements som körs från vänster till höger. Vi kan kliva ner i dessa grenar från vänster till höger och placera den motsvarande assemblerkoden. Varje gång vi avslutar en gren måste vi gå tillbaka upp och börja arbeta på en ny gren.
Den vänstra grenen i vår statementsekvens innehåller den första tilldelningen till en ny heltalsvariabel, a. Det tilldelade värdet är ett blad som innehåller det konstanta integralvärdet, 5. I likhet med den vänstra grenen är den mellersta grenen en tilldelning. Den tilldelar den binära operationen (bin op) för multiplikation mellan a och 5, till a . För enkelhetens skull hänvisar vi bara till a två gånger från samma nod, i stället för att ha två a-noder.
Den sista grenen är bara en retur och den är för programmets utgångskod. Vi talar om för datorn att det avslutades normalt genom att returnera noll.
Nedan följer produktionen från GNU C Compiler (x86-64 GCC 8.1) givet vår källkod utan optimeringar.
Håll i minnet att kompilatorn inte genererade kommentarerna eller mellanslag.
main:
push rbp
mov rbp, rsp
mov DWORD PTR , 5 ; leftmost branch
mov edx, DWORD PTR ; middle branch
mov eax, edx
sal eax, 2
add eax, edx
mov DWORD PTR , eax
mov eax, 0 ; rightmost branch
pop rbp
ret
Ett fantastiskt verktyg; Compiler Explorer av Matt Godbolt, gör det möjligt att skriva kod och se kompilatorns assemblyproduktioner i realtid. Prova vårt experiment på https://godbolt.org/g/Uo2Z5E.
Kodgeneratorn försöker vanligtvis optimera koden på något sätt. Vi använder tekniskt sett aldrig vår variabel a. Även om vi tilldelar den, läser vi den aldrig igen. En kompilator bör känna igen detta och i slutändan ta bort hela variabeln i den slutliga assemblerproduktionen. Vår variabel stannade kvar eftersom vi inte kompilerade med optimeringar.
Du kan lägga till argument till kompilatorn i Compiler Explorer.
-O3är en flagga för GCC som betyder maximal optimering. Prova att lägga till den och se vad som händer med den genererade koden.
När assemblerkoden har genererats kan vi kompilera assemblern ner till maskinkod med hjälp av en assembler. Maskinkoden fungerar endast för den enda mål-CPU-arkitekturen. Om vi vill rikta in oss på en ny arkitektur måste vi lägga till den arkitekturen för assemblermålet så att den kan produceras av vår kodgenerator.
Ansamlingsverktyget som du använder för att kompilera assemblern ner till maskinkod är också skrivet i ett programmeringsspråk. Den kan till och med vara skriven i ett eget assemblerspråk. Att skriva en kompilator i det språk som den kompilerar kallas bootstrapping.
https://en.wikipedia.org/wiki/Bootstrapping_(compilers)
Slutsats
Kompilatorer tar text, analyserar och bearbetar den och förvandlar den sedan till binär kod som din dator kan läsa. Detta gör att du slipper skriva binärfiler manuellt till din dator och dessutom kan du lättare skriva komplexa program.
Backmatter
Och det var allt! Vi tokeniserade, parsade och genererade vår källkod. Jag hoppas att du har en större förståelse för datorer och programvara efter att ha läst detta. Om du fortfarande är förvirrad är det bara att kolla in några av de lärresurser som jag har listat längst ner. Jag hade aldrig förstått allt detta efter att ha läst en enda artikel. Om du har några frågor, titta för att se om någon annan redan har ställt den innan du tar till kommentarsfältet.