Introduzione
Tutto ciò che un compilatore è, è solo un programma. Il programma prende un input (che è il codice sorgente – alias un file di byte o dati) e generalmente produce un programma dall’aspetto completamente diverso, che ora è eseguibile; diversamente dall’input.
Sulla maggior parte dei sistemi operativi moderni, i file sono organizzati in array unidimensionali di byte. Il formato di un file è definito dal suo contenuto, poiché un file è esclusivamente un contenitore di dati, anche se, su alcune piattaforme il formato è solitamente indicato dall’estensione del nome del file, specificando le regole per come i byte devono essere organizzati e interpretati in modo significativo. Per esempio, i byte di un file di testo semplice (
.txtin Windows) sono associati a caratteri ASCII o UTF-8, mentre i byte dei file immagine, video e audio sono interpretati diversamente. (Wikipedia)
(https://en.wikipedia.org/wiki/Computer_file#File_contents)
Il compilatore prende il vostro codice sorgente leggibile dall’uomo, lo analizza e poi produce un codice leggibile dal computer chiamato codice macchina (binario). Alcuni compilatori (invece di andare direttamente al codice macchina) vanno in assembly, o in un diverso linguaggio leggibile dall’uomo.
I linguaggi leggibili dall’uomo sono AKA linguaggi di alto livello. Un compilatore che va da un linguaggio di alto livello a un diverso linguaggio di alto livello è chiamato compilatore source-to-source, transcompilatore o transpilatore.
(https://en.wikipedia.org/wiki/Source-to-source_compiler)
int main() {
int a = 5;
a = a * 5;
return 0;
}
Quello sopra è un programma C scritto da un umano che fa quanto segue in un linguaggio più semplice, ancora più leggibile dall’uomo, chiamato pseudocodice:
program 'main' returns an integer
begin
store the number '5' in the variable 'a'
'a' equals 'a' times '5'
return '0'
end
Lo pseudocodice è una descrizione informale di alto livello del principio di funzionamento di un programma per computer o altro algoritmo. (Wikipedia)
(https://en.wikipedia.org/wiki/Pseudocode)
Compileremo quel programma C in codice assembly stile Intel proprio come fa un compilatore. Anche se un computer deve essere specifico e seguire algoritmi per determinare cosa rende parole, interi e simboli; noi possiamo semplicemente usare il buon senso. Questo, a sua volta, rende la nostra disambiguazione molto più breve che per un compilatore.
Questa analisi è semplificata per una più facile comprensione.
Tokenization
Prima che un computer possa decifrare un programma, deve prima dividere ogni simbolo nel suo token. Un token è l’idea di un carattere, o un raggruppamento di caratteri, all’interno di un file sorgente. Questo processo è chiamato tokenizzazione, ed è fatto da un tokenizzatore.
Il nostro codice sorgente originale sarebbe suddiviso in token e conservato nella memoria di un computer. Cercherò di trasmettere la memoria del computer nel seguente diagramma della produzione del tokenizer.
Prima:
int main() {
int a = 5;
a = a * 5;
return 0;
}
Dopo:
Il diagramma è formattato a mano per leggibilità. In realtà, non sarebbe indentato o diviso per linee.
Come potete vedere, crea una forma molto letterale di ciò che gli è stato dato. Dovreste essere in grado di replicare quasi il codice sorgente originale dati solo i token. I token dovrebbero mantenere un tipo, e se il tipo può essere di più di un valore, il token dovrebbe contenere anche il valore corrispondente.
I token stessi non sono sufficienti per compilare. Abbiamo bisogno di conoscere il contesto, e cosa significano quei token quando sono messi insieme. Questo ci porta al parsing, dove possiamo dare un senso a quei token.
Parsing
La fase di parsing prende i token e produce un albero sintattico astratto, o AST. Esso descrive essenzialmente la struttura del programma, e può essere usato per determinare come viene eseguito, in un modo molto – come suggerisce il nome – astratto. È molto simile a quando si facevano gli alberi grammaticali nella scuola media inglese.
Il parser generalmente finisce per essere la parte più complessa del compilatore. I parser sono complessi e richiedono molto lavoro e comprensione. Questo è il motivo per cui ci sono molti programmi là fuori che possono generare un intero parser a seconda di come lo si descrive.
Questi ‘strumenti per creare parser’ sono chiamati generatori di parser. I generatori di parser sono specifici per le lingue, poiché generano il parser nel codice di quella lingua. Bison (C/C++) è uno dei generatori di parser più conosciuti al mondo.
Il parser, in breve, cerca di far corrispondere i token a modelli di token già definiti. Per esempio, potremmo dire che l’assegnazione prende la seguente forma di token, usando EBNF:
EBNF (o un suo dialetto) è comunemente usato nei generatori di parser per definire la grammatica.
assignment = identifier, equals, int | identifier ;
I seguenti modelli di token sono considerati un’assegnazione:
a = 5
or
a = a
or
b = 123456789
Ma i seguenti modelli non lo sono, anche se dovrebbero esserlo:
int a = 5
or
a = a * 5
Quelli che non funzionano non sono impossibili, ma piuttosto richiedono ulteriore sviluppo e complessità all’interno del parser prima che possano essere implementati interamente.
Leggi il seguente articolo di Wikipedia se ti interessa di più su come funzionano i parser. https://en.wikipedia.org/wiki/Parsing
Teoricamente, dopo che il nostro parser ha finito di analizzare, dovrebbe generare un albero di sintassi astratto come il seguente:
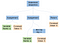
In informatica, un albero sintattico astratto (AST), o semplicemente albero sintattico, è una rappresentazione ad albero della struttura sintattica astratta del codice sorgente scritto in un linguaggio di programmazione. (Wikipedia)
(https://en.wikipedia.org/wiki/Abstract_syntax_tree)
Dopo che l’albero sintattico astratto stabilisce l’ordine di esecuzione di alto livello e le operazioni da eseguire, diventa abbastanza semplice iniziare a generare codice assembly.
Generazione di codice
Siccome l’AST contiene rami che definiscono quasi interamente il programma, possiamo passare attraverso questi rami, generando in sequenza l’assembly equivalente. Questo è chiamato “camminare sull’albero”, ed è un algoritmo per la generazione di codice usando un AST.
La generazione di codice immediatamente dopo il parsing non è comune per i compilatori più complessi, poiché essi passano attraverso più fasi prima di avere un AST finale, come l’intermedio, l’ottimizzazione, ecc. Ci sono più tecniche per la generazione di codice.
https://en.wikipedia.org/wiki/Code_generation_(compiler)
Compiliamo in assembly perché un singolo assemblatore può produrre codice macchina per una o più architetture di CPU diverse. Per esempio, se il nostro compilatore generasse l’assembly NASM, i nostri programmi sarebbero compatibili con le architetture Intel x86 (16-bit, 32-bit e 64-bit). Compilare direttamente in codice macchina non sarebbe così efficace, perché avremmo bisogno di scrivere un backend per ogni architettura di destinazione in modo indipendente. Anche se sarebbe piuttosto dispendioso in termini di tempo, e con meno guadagno rispetto all’utilizzo di un assemblatore di terze parti.
Con LLVM, si può semplicemente compilare in LLVM IR ed esso gestisce il resto. Compila su un’ampia gamma di linguaggi assembler, e quindi compila su molte più architetture. Se avete già sentito parlare di LLVM, probabilmente capirete perché è così apprezzato, ora.
https://en.wikipedia.org/wiki/LLVM
Se dovessimo entrare nei rami della sequenza di istruzioni, troveremmo tutte le istruzioni che vengono eseguite da sinistra a destra. Possiamo scendere lungo questi rami da sinistra a destra, mettendo il codice assembly equivalente. Ogni volta che finiamo un ramo, dobbiamo risalire e iniziare a lavorare su un nuovo ramo.
Il ramo più a sinistra della nostra sequenza di istruzioni contiene la prima assegnazione a una nuova variabile intera, a. Il valore assegnato è una foglia che contiene il valore integrale costante, 5. Simile al ramo più a sinistra, il ramo centrale è un’assegnazione. Esso assegna l’operazione binaria (bin op) di moltiplicazione tra a e 5, a a . Per semplicità facciamo semplicemente riferimento a a due volte dallo stesso nodo, piuttosto che avere due nodi a.
Il ramo finale è solo un ritorno ed è per il codice di uscita del programma. Diciamo al computer che è uscito normalmente restituendo zero.
Quella che segue è la produzione del compilatore GNU C (x86-64 GCC 8.1) dato il nostro codice sorgente senza ottimizzazioni.
Tenete a mente, il compilatore non ha generato i commenti o le spaziature.
main:
push rbp
mov rbp, rsp
mov DWORD PTR , 5 ; leftmost branch
mov edx, DWORD PTR ; middle branch
mov eax, edx
sal eax, 2
add eax, edx
mov DWORD PTR , eax
mov eax, 0 ; rightmost branch
pop rbp
ret
Un fantastico strumento; il Compiler Explorer di Matt Godbolt, ti permette di scrivere codice e vedere le produzioni assembly del compilatore in tempo reale. Prova il nostro esperimento a https://godbolt.org/g/Uo2Z5E.
Il generatore di codice di solito cerca di ottimizzare il codice in qualche modo. Tecnicamente non usiamo mai la nostra variabile a. Anche se la assegniamo, non la leggiamo mai più. Un compilatore dovrebbe riconoscere questo e alla fine rimuovere l’intera variabile nella produzione finale dell’assembly. La nostra variabile è rimasta dentro perché non abbiamo compilato con le ottimizzazioni.
Puoi aggiungere argomenti al compilatore su Compiler Explorer.
-O3è un flag per GCC che significa massima ottimizzazione. Prova ad aggiungerlo e vedi cosa succede al codice generato.
Dopo che il codice assembly è stato generato, possiamo compilare l’assembly in codice macchina, usando un assemblatore. Il codice macchina funziona solo per la singola architettura CPU di destinazione. Per indirizzare una nuova architettura, abbiamo bisogno di aggiungere quell’architettura di destinazione dell’assembly per essere producibile dal nostro generatore di codice.
L’assemblatore che usate per compilare l’assembly in codice macchina è anche scritto in un linguaggio di programmazione. Potrebbe anche essere scritto in un proprio linguaggio assembly. Scrivere un compilatore nel linguaggio che compila è chiamato bootstrapping.
https://en.wikipedia.org/wiki/Bootstrapping_(compilers)
Conclusione
I compilatori prendono il testo, lo analizzano e lo processano, poi lo trasformano in binario per essere letto dal tuo computer. Questo ti evita di dover scrivere manualmente il binario per il tuo computer, e inoltre, ti permette di scrivere programmi complessi più facilmente.
Backmatter
E questo è tutto! Abbiamo tokenizzato, analizzato e generato il nostro codice sorgente. Spero che tu abbia una maggiore comprensione dei computer e del software dopo aver letto questo. Se siete ancora confusi, date un’occhiata ad alcune delle risorse di apprendimento che ho elencato in fondo. Non ho mai capito tutto questo dopo aver letto un solo articolo. Se avete delle domande, guardate se qualcun altro le ha già fatte prima di passare alla sezione dei commenti.