È domenica mattina, i roster stanno per chiudersi per il primo pomeriggio, e tu stai decidendo tra due WR di nona fascia per quello slot WR3. È la settimana 3, sono entrambi waiver wire disperazione picks che non hai avuto il tempo di ricerca, e francamente, hai altri pesci da friggere oggi. Ecco: il punteggio previsto da ESPN per un ragazzo è 7, per l’altro ragazzo è 8. Tu vai con l’8 e pensi, “quel punteggio previsto deve significare qualcosa, giusto?”
tl;dr Quel punteggio previsto non significa essenzialmente nulla, e noi possiamo dimostrarlo, usando la (non documentata) ESPN Fantasy API e un po’ di Python.
Un piccolo background
Mike Clay è l’uomo dietro la tenda delle proiezioni fantasy di ESPN. Giura di avere un “lungo processo” che coinvolge “calcoli statistici e input soggettivi”. Voglio dire che lui viene pagato e io scrivo post sul blog, quindi non posso odiare troppo questo misterioso processo statistico, qualunque esso sia.
Non importa, ci sono state molte analisi che confrontano le proiezioni di ESPN con altri siti in tutto lo spettro, da intensi post su reddit a post sul blog del NYT.
Il consenso sembra essere, le proiezioni di ESPN non sono molto buone, sulla base di metriche come “accuratezza” e R-squared che cercano di quantificare l’errore complessivo con una singola statistica riassuntiva.
Ma ho anche notato che ci sono poche informazioni su come controllare questo per se stessi. Questo sito di footballanalytics.net si collega ad alcuni grandi script R, ma non ho visto che nessuno afferra specificamente le proiezioni di ESPN (anche se potrei sbagliarmi).
Esplorando …
ESPN sta mantenendo una stagione storica di proiezioni al momento, quindi prendiamo il 2018 e vediamo cosa troviamo.
Faremo uso dell’API ESPN Fantasy che copro come usare qui.
In poche parole, invieremo a ESPN la stessa richiesta GET che il suo sito invia ai propri server quando navighiamo verso una pagina storica della lega. È possibile origliare come queste richieste sono formate utilizzando gli strumenti Web Developer di Safari o un servizio proxy come Charles o Fiddler.
Prima di scrivere il codice per prendere tutti i dati di cui abbiamo bisogno, esploriamo un piccolo pezzo di esso:
import requestsswid = 'YOUR_SWID'espn_s2 = 'LONG_ESPN_S2_KEY'league_id = 123456season = 2018week = 5url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn})d = r.json()Questo è spiegato un po’ più in dettaglio nel mio post precedente, ma l’idea è che stiamo inviando una richiesta all’API di ESPN per una vista specifica su una specifica lega, settimana e stagione che ci darà informazioni complete su matchup/boxscore compresi i punti previsti. I cookie sono necessari solo per le leghe private, e di nuovo, li copro qui.
Se navigate attraverso la struttura JSON, troverete che ogni squadra fantasy ha un roster dei suoi giocatori, e ogni giocatore ha un elenco dei suoi stats.
(Ancora una volta, un bel modo per navigare in questa struttura è con gli strumenti Web Developer di Safari: vai a una pagina di interesse nella clubhouse della tua lega fantasy, apri gli strumenti Web Developer, vai a Risorse, poi cerca sotto XHRs un oggetto con il tuo ID di lega. Questo sarà il testo grezzo del JSON … cambia “Response” con “JSON” nella piccola area dell’intestazione per un’interfaccia più user-friendly in stile explorer.)
Raccolta di tutte le proiezioni 2018
È un po’ nascosto, ma all’interno di questa sottostruttura ci sono le proiezioni e i punti fantasy effettivi per ogni giocatore di ogni roster.
Ho notato che la lista stats per un particolare giocatore ha 5-6 voci, una delle quali è sempre il punteggio proiettato e un’altra è quello effettivo. Il punteggio previsto è identificato da statSourceId=1, quello effettivo da statSourceId=0.
Utilizziamo questa osservazione per costruire una serie di cicli per inviare richieste GET per ogni settimana, quindi estrarre ogni punteggio previsto/effettivo per ogni giocatore di ogni roster.
import requestsimport pandas as pdleague_id = 123456season = 2018slotcodes = { 0 : 'QB', 2 : 'RB', 4 : 'WR', 6 : 'TE', 16: 'Def', 17: 'K', 20: 'Bench', 21: 'IR', 23: 'Flex'}url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'data = print('Week ', end='')for week in range(1, 17): print(week, end=' ') r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn}) d = r.json() for tm in d: tmid = tm for p in tm: name = p slot = p pos = slotcodes # injured status (need try/exc bc of D/ST) inj = 'NA' try: inj = p except: pass # projected/actual points proj, act = None, None for stat in p: if stat != week: continue if stat == 0: act = stat elif stat == 1: proj = stat data.append()print('\nComplete.')data = pd.DataFrame(data, columns=)Week 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Complete.Abbiamo qualcosa del genere:
data.head() Week Team Player Slot Pos Status Proj Actual0 1 1 Leonard Fournette 2 RB QUESTIONABLE 13.891825 5.01 1 1 Christian McCaffrey 2 RB ACTIVE 11.067053 7.02 1 1 Derrick Henry 20 Bench ACTIVE 10.271163 2.03 1 1 Josh Gordon 4 WR OUT 6.153141 7.04 1 1 Philip Rivers 0 QB QUESTIONABLE 26.212294 42.0Sì, sì, si tratta solo di giocatori a roster, quindi non stiamo catturando nessun free agent … ma dovrebbe almeno darci un senso della precisione delle proiezioni di ESPN, per ora.
Tracciamo “Proj” contro “Actual” per alcune posizioni diverse e incrociamo le dita …
fig, axs = plt.subplots(1,3, sharey=True, figsize=(12, 4))for i, pos in enumerate(): (data .query('Pos == @pos') .pipe((axs.scatter, 'data'), x='Proj', y='Actual', s=50, c='b', alpha=0.5) ) axs.plot(, , 'k--') axs.set(xlim=, ylim=, xlabel='Projected', title=pos)axs.set_ylabel('Actual')plt.tight_layout()plt.show()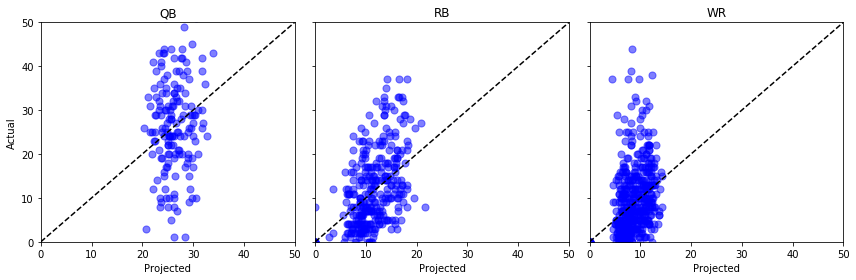
Um, non benissimo. Potremmo fare dei test statistici qui, ma al mio occhio inesperto sembra che quei punti proiettati potrebbero anche uscire da una distribuzione uniforme.
Forse è meglio in certe settimane? Più avanti nella stagione, forse? Tracciamo l’errore complessivo, per settimana, per posizione. Questo codice diventa un po’ macchinoso 🙁 ma sono pronto a conviverci:
fig, axs = plt.subplots(1,3, sharey=True, figsize=(13,4))data = data - datadata = pd.cut(data, bins=4, labels=)cols = sns.color_palette('Blues')# dummy plots for a legendfor k,cat in enumerate(): axs.plot(,, c=cols, label='Wk ' + cat)axs.legend()for i, pos in enumerate(): for cat in range(4): t = data.query('Pos == @pos & Cat == @cat') sns.kdeplot(t, color=cols, ax=axs, legend=False) axs.set(xlabel='Actual - Proj', title=pos) plt.show()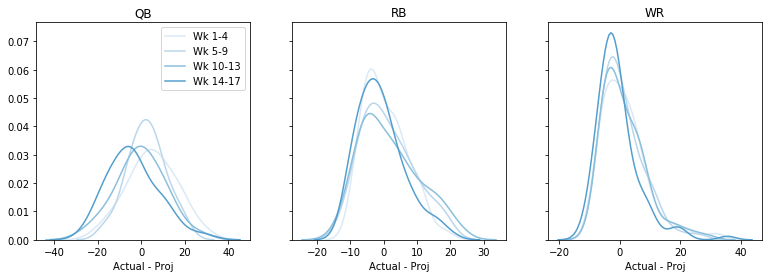
Forse c’è una tendenza a sovraprogettare più tardi nella stagione, ma nel complesso non direi nulla neanche qui. (Notate che facendo questo abbiamo perso alcune informazioni sul fatto che l’errore è maggiore o minore per le proiezioni alte o basse.)
Vorrei guardare le serie temporali dei punti dei giocatori dopo. La saggezza del senso comune è che il modo migliore per indovinare quale sarà il punteggio di un giocatore la prossima settimana è quello di guardare le sue ultime 4-5 settimane … quanto è affidabile questa strategia?
In questo post, provo a controllare le proiezioni ESPN a livello di roster – forse le proiezioni individuali non sono impressionanti, ma in aggregato cominciano magicamente ad aiutare? (Spoiler: non proprio.)
Scritto il 5 agosto 2019 da Steven Morse