Előszó
A fordító nem más, mint egy program. A program vesz egy bemenetet (ami a forráskód – más néven egy bájt- vagy adatfájl), és általában egy teljesen más kinézetű programot állít elő, ami már futtatható; ellentétben a bemenettel.
A legtöbb modern operációs rendszeren a fájlok egydimenziós bájt-táblákba vannak szervezve. A fájl formátumát a tartalma határozza meg, mivel a fájl kizárólag az adatok tárolására szolgál, bár egyes platformokon a formátumot általában a fájlnévkiterjesztés jelzi, megadva a bájtok szervezésének és értelmes értelmezésének szabályait. Például egy egyszerű szövegfájl (
.txta Windowsban) bájtjai vagy ASCII vagy UTF-8 karakterekhez kapcsolódnak, míg a kép-, video- és hangfájlok bájtjai másképp értelmezhetők. (Wikipedia)
(https://en.wikipedia.org/wiki/Computer_file#File_contents)
A fordító fogadja az ember által olvasható forráskódot, elemzi azt, majd számítógép által olvasható kódot, úgynevezett gépi kódot (bináris kódot) állít elő. Egyes fordítók (ahelyett, hogy egyenesen gépi kódba mennének) assemblybe, vagy egy másik ember által olvasható nyelvbe mennek át.
Az ember által olvasható nyelvek AKA magas szintű nyelvek. Az olyan fordítót, amely egy magas szintű nyelvről egy másik magas szintű nyelvre megy át, forrásból forrásba fordítónak, transzkompilátornak vagy transzpilátornak nevezik.
(https://en.wikipedia.org/wiki/Source-to-source_compiler)
int main() {
int a = 5;
a = a * 5;
return 0;
}
A fenti egy ember által írt C program, amely a következőket teszi egy egyszerűbb, még inkább ember által olvasható nyelven, az úgynevezett pszeudokódon:
program 'main' returns an integer
begin
store the number '5' in the variable 'a'
'a' equals 'a' times '5'
return '0'
end
Az álkód egy számítógépes program vagy más algoritmus működési elvének informális, magas szintű leírása. (Wikipedia)
(https://en.wikipedia.org/wiki/Pseudocode)
Ezt a C programot Intel-stílusú assembly kóddá fordítjuk, ahogyan azt a fordító is teszi. Bár egy számítógépnek specifikusnak kell lennie, és algoritmusokat kell követnie annak meghatározásához, hogy mitől lesznek szavak, egész számok és szimbólumok; mi egyszerűen használhatjuk a józan eszünket. Ez viszont sokkal rövidebbé teszi a mi disambiguaciónkat, mint egy fordító esetében.
Ez az elemzés a könnyebb megértés érdekében leegyszerűsítve.
Tokenizáció
Mielőtt a számítógép megfejtene egy programot, először minden szimbólumot saját tokenre kell bontania. A token egy karakter, vagy karakterek csoportosítása a forrásfájlon belül. Ezt a folyamatot tokenizálásnak nevezik, és egy tokenizáló végzi.
Az eredeti forráskódot tokenekre bontanánk, és a számítógép memóriájában tárolnánk. A számítógép memóriáját próbálom érzékeltetni a tokenizátor előállításának alábbi ábráján.
Előtte:
int main() {
int a = 5;
a = a * 5;
return 0;
}
Azután:
A diagramot kézzel formáztam az olvashatóság érdekében. A valóságban nem lenne behúzva vagy soronként tagolva.
Mint láthatod, nagyon szó szerinti formáját hozza létre annak, amit adtak neki. Képesnek kell lennie arra, hogy szinte lemásolja az eredeti forráskódot, ha csak a tokeneket adja meg. A tokeneknek meg kell tartaniuk egy típust, és ha a típusnak több értéke is lehet, akkor a tokeneknek a megfelelő értéket is tartalmazniuk kell.
A tokenek önmagukban nem elegendőek a fordításhoz. Ismernünk kell a kontextust, és azt, hogy ezek a tokenek mit jelentenek együttesen. Ez vezet el bennünket a tagoláshoz, ahol értelmet adhatunk ezeknek a tokeneknek.
Tagolás
A tagolási fázis a tokeneket veszi és egy absztrakt szintaxisfát, vagy AST-t állít elő. Ez lényegében leírja a program szerkezetét, és felhasználható a program végrehajtásának meghatározásához, nagyon – ahogy a neve is mutatja – absztrakt módon. Nagyon hasonlít ahhoz, amikor a középiskolai angolban nyelvtani fákat készítettünk.
A parser általában a fordító legösszetettebb része. Az elemzők összetettek, és sok kemény munkát és megértést igényelnek. Ezért rengeteg olyan program létezik, amely képes egy teljes parsert generálni attól függően, hogy hogyan írjuk le.
Ezeket a “parserkészítő eszközöket” parsergenerátoroknak hívják. A parsergenerátorok nyelvspecifikusak, mivel az adott nyelv kódjában generálják a parsert. A Bison (C/C++) az egyik legismertebb parsergenerátor a világon.
A parser, röviden szólva, megkísérli a tokeneket a tokenek már meghatározott mintáihoz illeszteni. Például mondhatjuk, hogy a hozzárendelés a következő formájú tokeneket veszi fel, az EBNF-et használva:
Az EBNF-et (vagy annak valamely dialektusát) általában a nyelvtan definiálására használják a bontógenerátorokban.
assignment = identifier, equals, int | identifier ;
Az alábbi, tokenekből álló mintákat tekintjük hozzárendelésnek:
a = 5
or
a = a
or
b = 123456789
A következő mintákat viszont nem, pedig kellene:
int a = 5
or
a = a * 5
Azok, amelyek nem működnek, nem lehetetlenek, hanem további fejlesztést és komplexitást igényelnek az elemzőn belül, mielőtt teljesen megvalósíthatók lennének.
Az alábbi Wikipédia-szócikket olvasd el, ha jobban érdekel, hogyan működnek az elemzők. https://en.wikipedia.org/wiki/Parsing
elméletileg, miután az elemzőnk befejezte az elemzést, egy olyan absztrakt szintaxisfát generálna, mint a következő:
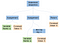
A számítástechnikában az absztrakt szintaxisfa (AST) vagy egyszerűen csak szintaxisfa a programozási nyelven írt forráskód absztrakt szintaktikai szerkezetének fa reprezentációja. (Wikipedia)
(https://en.wikipedia.org/wiki/Abstract_syntax_tree)
Miután az absztrakt szintaxisfa lefekteti a végrehajtás magas szintű sorrendjét és az elvégzendő műveleteket, meglehetősen egyszerűvé válik az assembly kód generálásának megkezdése.
Kódgenerálás
Mivel az AST olyan ágakat tartalmaz, amelyek szinte teljes egészében meghatározzák a programot, ezeken az ágakon keresztül lépkedhetünk, szekvenciálisan generálva az egyenértékű assembly-t. Ezt hívják “fán járásnak”, és ez egy AST-t használó kódgenerálási algoritmus.
A kódgenerálás közvetlenül a tagolás után nem gyakori a bonyolultabb fordítóprogramoknál, mivel ezek több fázison mennek keresztül, mielőtt egy végleges AST-t kapnánk, mint például a köztes, optimalizálás stb. A kódgenerálásra több technika is létezik.
https://en.wikipedia.org/wiki/Code_generation_(compiler)
Azért fordítunk assembly-be, mert egyetlen asszembler képes gépi kódot előállítani akár egy, akár több különböző CPU-architektúrához. Ha például a fordítóprogramunk NASM assembly-t generálna, akkor a programjaink kompatibilisek lennének az Intel x86-os architektúrákkal (16 bites, 32 bites és 64 bites). Az egyenesen gépi kódra történő fordítás nem lenne olyan hatékony, mivel minden egyes célarchitektúrához külön-külön kellene háttértárat írnunk. Bár ez elég időigényes lenne, és kevesebb haszonnal járna, mint egy harmadik féltől származó asszembler használata.
A LLVM-mel egyszerűen lefordíthatjuk LLVM IR-be, és az elintézi a többit. Az assembler nyelvek széles skálájára fordít le, és így sokkal több architektúrára fordít. Ha már hallottál az LLVM-ről, akkor most már valószínűleg érted, hogy miért olyan nagy becsben tartják.
https://en.wikipedia.org/wiki/LLVM
Ha belelépnénk az utasítássorozat elágazásaiba, akkor megtalálnánk az összes utasítást, amely balról jobbra haladva fut. Ezeket az ágakat balról jobbra haladva lépegethetjük lefelé, elhelyezve az ezzel egyenértékű assembly kódot. Minden alkalommal, amikor befejezünk egy ágat, vissza kell mennünk felfelé, és egy új ágon kell elkezdenünk dolgozni.
Az utasítássorozatunk legbaloldali ága tartalmazza az első hozzárendelést egy új egész szám változóhoz, a a-hoz. A hozzárendelt érték egy levél, amely a konstans integrálértéket, az 5-öt tartalmazza. A bal szélső ághoz hasonlóan a középső ág is egy hozzárendelés. A a és 5 közötti szorzás bináris műveletét (bin op) rendeli a a-hoz. Az egyszerűség kedvéért csak kétszer hivatkozunk a a-ra ugyanabból a csomópontból, ahelyett, hogy két a csomópontunk lenne.
Az utolsó ág csak egy visszatérés, és a program kilépési kódjára szolgál. A nullás visszatéréssel közöljük a számítógéppel, hogy normálisan kilépett.
A következő a GNU C Compiler (x86-64 GCC 8.1) produkciója a forráskódunk alapján, optimalizálás nélkül.
Ne feledjük, a fordító nem generálta a megjegyzéseket és a szóközöket.
main:
push rbp
mov rbp, rsp
mov DWORD PTR , 5 ; leftmost branch
mov edx, DWORD PTR ; middle branch
mov eax, edx
sal eax, 2
add eax, edx
mov DWORD PTR , eax
mov eax, 0 ; rightmost branch
pop rbp
ret
Egy fantasztikus eszköz; a Matt Godbolt által készített Compiler Explorer lehetővé teszi, hogy kódot írjunk és valós időben lássuk a fordító assembly produkcióit. Próbálja ki a kísérletünket a https://godbolt.org/g/Uo2Z5E címen.
A kódgenerátor általában megpróbálja valamilyen módon optimalizálni a kódot. Technikailag soha nem használjuk a a változónkat. Hiába rendeljük hozzá, soha többé nem olvassuk ki. A fordítónak ezt fel kellene ismernie, és végül a végső assembly előállításban az egész változót el kellene távolítania. A mi változónk azért maradt benne, mert nem optimalizálással fordítottunk.
A Compiler Explorerben érveket adhatunk a fordítónak.
-O3A GCC egy flag, amely a maximális optimalizálást jelenti. Próbálja meg hozzáadni, és nézze meg, mi történik a generált kóddal.
Az assembly kód generálása után lefordíthatjuk az assembly-t gépi kódra, egy assembler segítségével. A gépi kód csak az egyetlen cél CPU-architektúra esetén működik. Egy új architektúra megcélzásához hozzá kell adnunk azt az assembly célarchitektúrát, amelyet a kódgenerátorunk előállíthat.
Az assembly gépi kódra való lefordításához használt assembler is egy programozási nyelven íródott. Akár saját assembly nyelven is megírható. A fordító megírását azon a nyelven, amelyen fordít, bootstrappingnek nevezzük.
https://en.wikipedia.org/wiki/Bootstrapping_(compilers)
Következtetés
A fordítók szöveget vesznek, elemzik és feldolgozzák, majd a számítógép számára olvasható binárissá alakítják. Ezáltal nem kell kézzel bináris állományt írnod a számítógéped számára, ráadásul könnyebben írhatsz összetett programokat.
Háttéranyag
És ennyi! Tokenizáltuk, elemeztük és generáltuk a forráskódunkat. Remélem, ennek elolvasása után jobban megérted a számítógépeket és a szoftvereket. Ha még mindig össze vagy zavarodva, csak nézz meg néhányat a tanulási források közül, amelyeket az alján felsoroltam. Egyetlen cikk elolvasása után még sosem voltam mindezzel tisztában. Ha bármilyen kérdésed van, nézd meg, hogy más is feltette-e már, mielőtt a kommentszekcióba lépsz.