Esittely
Kääntäjä on vain ohjelma. Ohjelma ottaa syötteen (joka on lähdekoodi eli tavu- tai datatiedosto) ja tuottaa yleensä täysin erilaisen näköisen ohjelman, joka on nyt suoritettavissa; toisin kuin syötteessä.
Nykyaikaisimmissa käyttöjärjestelmissä tiedostot on järjestetty yksiulotteisiksi tavujoukoiksi. Tiedoston muoto määräytyy sen sisällön perusteella, koska tiedosto on pelkästään datan säilytyspaikka, vaikka joillakin alustoilla tiedostomuoto ilmoitetaan yleensä tiedostonimen laajennuksella, joka määrittelee säännöt sille, miten tavut on järjestettävä ja tulkittava mielekkäästi. Esimerkiksi pelkän tekstitiedoston tavut (
.txtWindowsissa) liittyvät joko ASCII- tai UTF-8-merkkeihin, kun taas kuva-, video- ja äänitiedostojen tavut tulkitaan toisin. (Wikipedia)
(https://en.wikipedia.org/wiki/Computer_file#File_contents)
Kääntäjä ottaa ihmisen luettavissa olevan lähdekoodin, analysoi sen ja tuottaa sitten tietokoneen luettavissa olevan koodin, jota kutsutaan konekoodiksi (binääriksi). Jotkut kääntäjät (sen sijaan, että ne siirtyisivät suoraan konekoodiin) siirtyvät assembleriin tai muuhun ihmisen luettavaan kieleen.
Ihmisen luettavissa olevat kielet ovat AKA korkean tason kieliä. Kääntäjää, joka siirtyy yhdestä korkean tason kielestä toiseen korkean tason kieleen, kutsutaan lähdekielestä lähdekieleen kääntäjäksi, transcompileriksi tai transpileriksi.
(https://en.wikipedia.org/wiki/Source-to-source_compiler)
int main() {
int a = 5;
a = a * 5;
return 0;
}
Yllä oleva on ihmisen kirjoittama C-ohjelma, joka tekee seuraavaa yksinkertaisemmalla, vielä ihmiselle luettavalla kielellä, jota kutsutaan pseudokoodiksi:
program 'main' returns an integer
begin
store the number '5' in the variable 'a'
'a' equals 'a' times '5'
return '0'
end
Pseudokoodi on epävirallinen korkean tason kuvaus tietokoneohjelman tai muun algoritmin toimintaperiaatteesta. (Wikipedia)
(https://en.wikipedia.org/wiki/Pseudocode)
Kompiloimme tuon C-ohjelman Intel-tyyliseksi assembly-koodiksi aivan kuten kääntäjä tekee. Vaikka tietokoneen on oltava tarkka ja noudatettava algoritmeja määrittääkseen, mitä ovat sanat, kokonaisluvut ja symbolit; me voimme vain käyttää tervettä järkeä. Tämä puolestaan tekee disambiguoinnistamme paljon lyhyemmän kuin kääntäjällä.
Tämä analyysi on yksinkertaistettu ymmärtämisen helpottamiseksi.
Tokenisointi
Ennen kuin tietokone voi purkaa ohjelman, sen on ensin jaettava jokainen symboli omaksi merkikseen. Token on ajatus merkistä tai merkkiryhmittymästä lähdetiedoston sisällä. Tätä prosessia kutsutaan tokenisoinniksi, ja sen tekee tokenizer.
Alkuperäinen lähdekoodimme pilkotaan tokeniksi ja säilytetään tietokoneen muistin sisällä. Yritän välittää tietokoneen muistin seuraavassa kaaviossa tokenisaattorin tuotannosta.
Before:
int main() {
int a = 5;
a = a * 5;
return 0;
}
After:
Diagrammi on käsin muotoiltu luettavuuden vuoksi. Todellisuudessa sitä ei olisi sisennetty tai jaettu riveittäin.
Kuten näet, se luo hyvin kirjaimellisen muodon siitä, mitä sille annettiin. Sinun pitäisi pystyä lähes kopioimaan alkuperäinen lähdekoodi, kun annat vain merkit. Merkkien pitäisi säilyttää tyyppi, ja jos tyypillä voi olla useampi kuin yksi arvo, merkin pitäisi sisältää myös vastaava arvo.
Merkit itsessään eivät riitä kääntämiseen. Meidän on tiedettävä konteksti ja se, mitä nuo merkit yhdessä tarkoittavat. Siitä pääsemmekin jäsennykseen, jossa voimme saada tolkkua noista tunnisteista.
Parsing
Parsing-vaiheessa otetaan tunnisteet ja tuotetaan abstrakti syntaksipuu eli AST. Se kuvaa lähinnä ohjelman rakennetta, ja sitä voidaan käyttää ohjelman suoritustavan määrittämiseen hyvin – kuten nimikin kertoo – abstraktilla tavalla. Se on hyvin samankaltainen kuin kielioppipuiden tekeminen yläasteen englannissa.
Parseri on yleensä kääntäjän monimutkaisin osa. Parserit ovat monimutkaisia ja vaativat paljon kovaa työtä ja ymmärrystä. Siksi on olemassa paljon ohjelmia, jotka voivat luoda kokonaisen jäsentimen riippuen siitä, miten kuvaat sen.
Näitä ’jäsentimen luontityökaluja’ kutsutaan jäsentimen generaattoreiksi. Parserigeneraattorit ovat kielikohtaisia, koska ne luovat parserin kyseisen kielen koodissa. Bison (C/C++) on yksi maailman tunnetuimmista jäsennysgeneraattoreista.
Lyhyesti sanottuna jäsennin yrittää sovittaa merkkejä jo määriteltyihin merkkikuvioihin. Voisimme esimerkiksi sanoa, että assignment ottaa seuraavan merkkien muodon käyttäen EBNF:ää:
EBNF:ää (tai sen murretta) käytetään yleisesti jäsentäjägeneraattoreissa kieliopin määrittelyyn.
assignment = identifier, equals, int | identifier ;
Seuraavat merkkikuviot katsotaan osoitukseksi:
a = 5
or
a = a
or
b = 123456789
Mutta seuraavat kuviot eivät ole, vaikka niiden pitäisikin olla:
int a = 5
or
a = a * 5
Ne, jotka eivät toimi, eivät ole mahdottomia, vaan vaativat pikemminkin lisäkehittelyä ja monimutkaisuutta jäsentäjän sisällä, ennen kuin ne voidaan toteuttaa kokonaan.
Lue seuraava Wikipedian artikkeli, jos olet kiinnostunut enemmän siitä, miten jäsentimet toimivat. https://en.wikipedia.org/wiki/Parsing
Teoreettisesti, kun jäsentäjämme on valmis jäsentämään, se tuottaisi seuraavan kaltaisen abstraktin syntaksipuun:
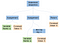
Informaatiotieteessä abstrakti syntaksipuu (AST, abstract syntax tree) tai vain syntaksipuu on puumainen esitys ohjelmointikielellä kirjoitetun lähdekoodin abstraktista syntaktisesta rakenteesta. (Wikipedia)
(https://en.wikipedia.org/wiki/Abstract_syntax_tree)
Kun abstrakti syntaksipuu esittää korkean tason suoritusjärjestyksen ja suoritettavat operaatiot, on melko suoraviivaista aloittaa assembler-koodin tuottaminen.
Koodin tuottaminen
Koska AST sisältää haaroja, jotka määrittelevät melkeinpä kokonaan ohjelman, voimme asteittain edetä näiden haarojen läpi ja tuottaa vastaavan assembler-koodin peräkkäin. Tätä kutsutaan ”puun kävelemiseksi”, ja se on algoritmi koodin generointiin AST:n avulla.
Koodin generointi heti jäsennyksen jälkeen ei ole yleistä monimutkaisemmissa kääntäjissä, koska ne käyvät läpi useampia vaiheita ennen lopullisen AST:n saamista, kuten välivaihe, optimointi jne. Koodin generointiin on useampia tekniikoita.
https://en.wikipedia.org/wiki/Code_generation_(compiler)
Kompiloimme assembleriin, koska yksi assembleri voi tuottaa konekoodia joko yhdelle tai muutamalle eri prosessoriarkkitehtuurille. Jos esimerkiksi kääntäjämme tuottaisi NASM-kokoonpanon, ohjelmamme olisivat yhteensopivia Intelin x86-arkkitehtuurien (16-bittinen, 32-bittinen ja 64-bittinen) kanssa. Suoraan konekoodiksi kääntäminen ei olisi yhtä tehokasta, koska meidän täytyisi kirjoittaa backend jokaiselle kohdearkkitehtuurille erikseen. Tosin se olisi melko aikaa vievää ja vähemmällä hyödyllä kuin kolmannen osapuolen assemblerin käyttäminen.
LLVM:n avulla voit vain kääntää LLVM IR:lle ja se hoitaa loput. Se kääntää alas laajan valikoiman assembler-kieliä, ja siten kääntää paljon useammalle arkkitehtuurille. Jos olet kuullut LLVM:stä aiemmin, ymmärrät varmaan nyt, miksi sitä niin arvostetaan.
https://en.wikipedia.org/wiki/LLVM
Jos astuisimme lausekesekvenssin haaroihin, löytäisimme kaikki lausekkeet, jotka ajetaan vasemmalta oikealle. Voimme astua näitä haaroja alaspäin vasemmalta oikealle ja sijoittaa vastaavan assembly-koodin. Aina kun lopetamme haaran, meidän on palattava takaisin ylös ja aloitettava uuden haaran työstäminen.
LAusejaksomme vasemmanpuoleisin haara sisältää ensimmäisen osoituksen uudelle kokonaislukumuuttujalle a. Annettu arvo on lehti, joka sisältää vakiointegraaliarvon 5. Samoin kuin vasemmanpuoleisin haara, myös keskimmäinen haara on osoitus. Se osoittaa a:n ja 5:n välisen kertolaskun binäärioperaation (bin op) a:lle. Yksinkertaisuuden vuoksi viittaamme vain a kahdesti samasta solmusta sen sijaan, että meillä olisi kaksi a-solmua.
Viimeinen haara on vain paluu ja se on ohjelman poistumiskoodia varten. Kerromme tietokoneelle, että se poistui normaalisti palauttaen nollan.
Seuraava on GNU C-kääntäjän (x86-64 GCC 8.1) tuottama tuotanto käyttäen lähdekoodiamme ilman optimointeja.
Muista, että kääntäjä ei tuottanut kommentteja tai välilyöntejä.
main:
push rbp
mov rbp, rsp
mov DWORD PTR , 5 ; leftmost branch
mov edx, DWORD PTR ; middle branch
mov eax, edx
sal eax, 2
add eax, edx
mov DWORD PTR , eax
mov eax, 0 ; rightmost branch
pop rbp
ret
Viisaana apuvälineenä; Matt Godboltin laatimassa Compiler Exploreri -ohjelmassa, voit kirjoittaa koodia ja nähdä kääntäjä-kokoonpanon tuotokset reaaliajassa. Kokeile kokeiluamme osoitteessa https://godbolt.org/g/Uo2Z5E.
Koodigeneraattori yrittää yleensä optimoida koodia jollain tavalla. Emme teknisesti koskaan käytä muuttujaamme a. Vaikka osoitamme sille, emme koskaan enää lue sitä. Kääntäjän pitäisi tunnistaa tämä ja lopulta poistaa koko muuttuja lopullisessa assembly-tuotannossa. Muuttujamme jäi sisään, koska emme kääntäneet optimointeja.
Kääntäjälle voi lisätä argumentteja Compiler Explorerissa.
-O3on GCC:n lippu, joka tarkoittaa maksimaalista optimointia. Kokeile lisätä se ja katso, mitä generoidulle koodille tapahtuu.
Kun assemblerikoodi on generoitu, voimme kääntää assemblerin avulla assemblerin konekoodiksi. Konekoodi toimii vain yhden kohdesuorittimen arkkitehtuurille. Jos haluamme kohdistaa uuden arkkitehtuurin, meidän on lisättävä kyseinen assembly-kohdearkkitehtuuri tuotettavaksi koodigeneraattorillamme.
Assembleri, jota käytät assemblerin kääntämiseen alas konekoodiksi, on myös kirjoitettu ohjelmointikielellä. Se voi olla jopa kirjoitettu omalla assemblerointikielellään. Kääntäjän kirjoittamista kielellä, jolla se kääntää, kutsutaan bootstrappingiksi.
https://en.wikipedia.org/wiki/Bootstrapping_(compilers)
Johtopäätös
Kääntäjät ottavat tekstin, jäsentävät ja käsittelevät sen ja muuttavat sen sitten tietokoneen luettavaksi binääriksi. Näin sinun ei tarvitse kirjoittaa manuaalisesti binääriä tietokoneellesi, ja lisäksi voit kirjoittaa monimutkaisempia ohjelmia helpommin.
Backmatter
Ja siinä kaikki! Me tokenisoimme, parsimme ja generoimme lähdekoodimme. Toivottavasti ymmärrät tietokoneita ja ohjelmistoja paremmin luettuasi tämän. Jos olet vielä hämmentynyt, tutustu alareunassa lueteltuihin oppimislähteisiin. En koskaan ymmärtänyt kaikkea tätä yhden artikkelin lukemisen jälkeen. Jos sinulla on kysyttävää, katso, onko joku muu jo kysynyt sen, ennen kuin otat kommenttiosioon.