Introducere
Tot ce este un compilator, este doar un program. Programul ia o intrare (care este codul sursă – aka un fișier de octeți sau date) și, în general, produce un program cu aspect complet diferit, care este acum executabil; spre deosebire de intrare.
În majoritatea sistemelor de operare moderne, fișierele sunt organizate în matrici unidimensionale de octeți. Formatul unui fișier este definit de conținutul său, deoarece un fișier este doar un container pentru date, deși, pe unele platforme, formatul este de obicei indicat de extensia numelui de fișier, specificând regulile pentru modul în care trebuie să fie organizați și interpretați în mod semnificativ octeții. De exemplu, octeții unui fișier text simplu (
.txtîn Windows) sunt asociați fie cu caractere ASCII, fie cu caractere UTF-8, în timp ce octeții fișierelor de imagine, video și audio sunt interpretați altfel. (Wikipedia)
(https://en.wikipedia.org/wiki/Computer_file#File_contents)
Compilatorul preia codul sursă lizibil de către om, îl analizează, apoi produce un cod lizibil de către calculator numit cod mașină (binar). Unele compilatoare (în loc să treacă direct la codul mașină) trec la asamblare sau la un alt limbaj lizibil de către om.
Limbajele lizibile de către om sunt AKA limbaje de nivel înalt. Un compilator care trece de la un limbaj de nivel înalt la un alt limbaj de nivel înalt se numește compilator sursă-sursă, transcompilator sau transpiler.(https://en.wikipedia.org/wiki/Source-to-source_compiler)
int main() {
int a = 5;
a = a * 5;
return 0;
}
Cel de mai sus este un program C scris de un om care face următoarele într-un limbaj mai simplu, chiar mai ușor de citit de către om, numit pseudocod:
program 'main' returns an integer
begin
store the number '5' in the variable 'a'
'a' equals 'a' times '5'
return '0'
end
Pseudocod este o descriere informală de nivel înalt a principiului de funcționare a unui program de calculator sau a unui alt algoritm. (Wikipedia)
(https://en.wikipedia.org/wiki/Pseudocode)
Noi vom compila acel program C în cod de asamblare în stil Intel, așa cum face un compilator. Deși un computer trebuie să fie specific și să urmeze algoritmi pentru a determina ce formează cuvinte, numere întregi și simboluri; noi putem folosi doar bunul simț. Acest lucru, la rândul său, face ca dezambiguizarea noastră să fie mult mai scurtă decât în cazul unui compilator.
Această analiză este simplificată pentru a fi mai ușor de înțeles.
Tokenizare
Înainte ca un calculator să poată descifra un program, trebuie mai întâi să împartă fiecare simbol în propriul său token. Un token este ideea de caracter, sau de grupare de caractere, în interiorul unui fișier sursă. Acest proces se numește tokenizare și este realizat de un tokenizer.
Codul nostru sursă original ar fi împărțit în token-uri și păstrat în interiorul memoriei unui calculator. Voi încerca să transmit memoria calculatorului în următoarea diagramă de producție a tokenizatorului.
Înainte:
int main() {
int a = 5;
a = a * 5;
return 0;
}
După:
Diagrama este formatată manual pentru lizibilitate. În realitate, nu ar fi indentată sau despărțită pe rând.
După cum puteți vedea, creează o formă foarte literală a ceea ce i s-a dat. Ar trebui să puteți aproape să reproduceți codul sursă original, având în vedere doar token-urile. Token-urile ar trebui să rețină un tip, iar dacă tipul poate avea mai multe valori, token-ul ar trebui să conțină și valoarea corespunzătoare.
Token-urile în sine nu sunt suficiente pentru a compila. Trebuie să cunoaștem contextul și să știm ce înseamnă acele jetoane atunci când sunt puse împreună. Acest lucru ne aduce la parsare, unde putem da sens acelor token-uri.
Parsare
Faza de parsare ia token-uri și produce un arbore sintactic abstract, sau AST. Acesta descrie, în esență, structura programului și poate fi utilizat pentru a determina modul în care acesta este executat, într-un mod foarte – după cum sugerează și numele – abstract. Este foarte asemănător cu momentul în care făceați arbori gramaticali în engleza din gimnaziu.
În general, parserul sfârșește prin a fi cea mai complexă parte a compilatorului. Parserele sunt complexe și necesită multă muncă și înțelegere. Acesta este motivul pentru care există o mulțime de programe care pot genera un întreg parser în funcție de modul în care îl descrieți.
Aceste „instrumente de creare a parserului” se numesc generatoare de parser. Generatoarele de parser sunt specifice limbilor, deoarece ele generează parserul în codul limbii respective. Bison (C/C++) este unul dintre cele mai cunoscute generatoare de parser din lume.
Perserul, pe scurt, încearcă să potrivească semnele cu modele de semne deja definite. De exemplu, am putea spune că atribuirea ia următoarea formă de jetoane, folosind EBNF:
EBNF (sau un dialect, al acestuia) este utilizat în mod obișnuit în generatoarele de parser pentru a defini gramatica.
assignment = identifier, equals, int | identifier ;
Înseamnă că următoarele modele de token-uri sunt considerate a fi o atribuire:
a = 5
or
a = a
or
b = 123456789
Dar următoarele modele nu sunt, chiar dacă ar trebui să fie:
int a = 5
or
a = a * 5
Cele care nu funcționează nu sunt imposibile, ci mai degrabă necesită o dezvoltare și o complexitate suplimentară în interiorul parserului înainte de a putea fi implementate în întregime.
Citește următorul articol din Wikipedia dacă te interesează mai mult cum funcționează parserii. https://en.wikipedia.org/wiki/Parsing
Teoretic, după ce parserul nostru a terminat de analizat, el ar genera un arbore sintactic abstract ca următorul:
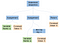
În informatică, un arbore sintactic abstract (AST), sau pur și simplu arbore sintactic, este o reprezentare arborescentă a structurii sintactice abstracte a codului sursă scris într-un limbaj de programare. (Wikipedia)
(https://en.wikipedia.org/wiki/Abstract_syntax_tree)
După ce arborele sintactic abstract stabilește ordinea de execuție la nivel înalt și operațiile care trebuie efectuate, devine destul de simplu să începem să generăm codul de asamblare.
Generarea codului
Din moment ce AST conține ramuri care definesc aproape în întregime programul, putem trece prin aceste ramuri, generând secvențial asamblarea echivalentă. Acest lucru se numește „walking the tree” (parcurgerea arborelui) și este un algoritm de generare a codului folosind un AST.
Generarea codului imediat după parsare nu este obișnuită în cazul compilatoarelor mai complexe, deoarece acestea trec prin mai multe faze înainte de a avea un AST final, cum ar fi cele intermediare, de optimizare, etc. Există mai multe tehnici de generare a codului.
https://en.wikipedia.org/wiki/Code_generation_(compiler)
Compilăm în asamblare deoarece un singur asamblor poate produce cod mașină pentru una sau câteva arhitecturi CPU diferite. De exemplu, dacă compilatorul nostru ar genera asamblare NASM, programele noastre ar fi compatibile cu arhitecturile Intel x86 (16, 32 și 64 de biți). Compilarea directă în cod mașină nu ar fi la fel de eficientă, deoarece ar trebui să scriem un backend pentru fiecare arhitectură țintă în parte. Deși, ar fi destul de consumator de timp și cu un câștig mai mic decât utilizarea unui asamblor de la o terță parte.
Cu LLVM, puteți doar să compilați în LLVM IR și acesta se ocupă de restul. Compilează până la o gamă largă de limbaje de asamblare și, prin urmare, compilează pe mult mai multe arhitecturi. Dacă ați auzit de LLVM înainte, probabil că înțelegeți de ce este atât de apreciat, acum.
https://en.wikipedia.org/wiki/LLVM
Dacă ar fi să intrăm în ramurile secvenței de instrucțiuni, am găsi toate instrucțiunile care sunt executate de la stânga la dreapta. Putem coborî aceste ramuri de la stânga la dreapta, plasând codul de asamblare echivalent. De fiecare dată când terminăm o ramură, trebuie să ne întoarcem în sus și să începem să lucrăm la o nouă ramură.
Cea mai din stânga ramură a secvenței noastre de instrucțiuni conține prima atribuire la o nouă variabilă întreagă, a. Valoarea atribuită este o frunză care conține valoarea integrală constantă, 5. Similar cu ramura cea mai din stânga, ramura din mijloc este o atribuire. Aceasta atribuie operația binară (bin op) de înmulțire între a și 5, la a . Pentru simplitate, facem doar o referință la a de două ori din același nod, în loc să avem două noduri a.
Ramificația finală este doar o întoarcere și este pentru codul de ieșire al programului. Îi spunem calculatorului că a ieșit în mod normal prin returnarea lui zero.
Cel ce urmează este producția compilatorului GNU C (x86-64 GCC 8.1) având în vedere codul nostru sursă, fără a folosi optimizări.
Rețineți, compilatorul nu a generat comentariile sau spațiile.
main:
push rbp
mov rbp, rsp
mov DWORD PTR , 5 ; leftmost branch
mov edx, DWORD PTR ; middle branch
mov eax, edx
sal eax, 2
add eax, edx
mov DWORD PTR , eax
mov eax, 0 ; rightmost branch
pop rbp
ret
Un instrument minunat; Compiler Explorer de Matt Godbolt, vă permite să scrieți cod și să vedeți producțiile de asamblare ale compilatorului în timp real. Încercați experimentul nostru la https://godbolt.org/g/Uo2Z5E.
Generatorul de cod încearcă, de obicei, să optimizeze codul într-un fel sau altul. Din punct de vedere tehnic, nu folosim niciodată variabila noastră a. Chiar dacă o atribuim, nu o mai citim niciodată. Un compilator ar trebui să recunoască acest lucru și, în cele din urmă, să elimine întreaga variabilă în producția finală de asamblare. Variabila noastră a rămas pentru că nu am compilat cu optimizări.
Puteți adăuga argumente compilatorului în Compiler Explorer.
-O3este un indicator pentru GCC care înseamnă optimizare maximă. Încercați să-l adăugați și vedeți ce se întâmplă cu codul generat.
După ce codul de asamblare a fost generat, putem compila asamblarea până la codul mașină, folosind un asamblor. Codul mașină funcționează numai pentru arhitectura CPU țintă unică. Pentru a viza o nouă arhitectură, trebuie să adăugăm acea arhitectură țintă a ansamblului pentru a putea fi produsă de generatorul nostru de cod.
Asamblatorul pe care îl folosiți pentru a compila ansamblul în cod mașină este, de asemenea, scris într-un limbaj de programare. Ar putea fi scris chiar în propriul său limbaj de asamblare. Scrierea unui compilator în limbajul pe care îl compilează se numește bootstrap.
https://en.wikipedia.org/wiki/Bootstrapping_(compilers)
Concluzie
Compilatoarele preiau text, îl analizează și îl procesează, apoi îl transformă în binar pentru a fi citit de computerul dumneavoastră. Acest lucru vă scutește de a fi nevoit să scrieți manual binar pentru computerul dumneavoastră și, în plus, vă permite să scrieți mai ușor programe complexe.
Backmatter
Și asta e tot! Am tokenizat, analizat și generat codul nostru sursă. Sper că aveți o mai bună înțelegere a computerelor și a software-ului după ce ați citit acest lucru. Dacă sunteți încă confuzi, consultați câteva dintre resursele de învățare pe care le-am enumerat în partea de jos. Niciodată nu am înțeles toate acestea după ce am citit un singur articol. Dacă aveți întrebări, uitați-vă să vedeți dacă altcineva le-a pus deja înainte de a le adresa în secțiunea de comentarii.
.