
>
>
>
>
Overvisão :
Média /Média /Modo/ Desvio /Desvio Padrão são todos conceitos muito básicos mas muito importantes de estatísticas usadas na ciência dos dados. Quase todo o algoritmo de aprendizagem da máquina utiliza estes conceitos em etapas de pré-processamento de dados. Estes conceitos são parte da estatística descritiva onde nós basicamente usamos para descrever e entender os dados para características na aprendizagem de máquinas
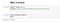
Mean :
Mean também é conhecido como média de todos os números no conjunto de dados que é calculado por abaixo da equação.

>Vamos dizer que temos abaixo das alturas de pessoas.
Alturas=
Median :
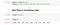
Median é um valor médio neste conjunto de dados encomendado.

Alterar os dados na ordem crescente e depois encontrar o valor médio.

Se tivermos um número par de valores no conjunto de dados, então a mediana é a soma dos dois números médios dividida por 2

No conjunto de dados temos um número ímpar como abaixo temos 9 alturas a mediana será o 5º valor numérico.

>
Modo :
Modo é o número que ocorre mais frequentemente no conjunto de dados.Aqui 150 está ocorrendo duas vezes, portanto este é o nosso modo.

Variação :
Variância são os valores numéricos que descrevem a variabilidade das observações a partir da sua média aritmética e denotada por sigma-squared(σ2 )
Variância mede a extensão dos indivíduos do grupo, no conjunto de dados a partir da média.
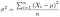
Onde
Xi : Elementos no conjunto de dados
mu : a média da população
= a média da população
Passo 1: Esta fórmula diz que se deve retirar cada elemento do conjunto de dados (população) e subtrair da média do conjunto de dados.Posteriormente somam-se todos os valores.
Passo 2: Pegue a soma no Passo 1 e divida pelo número total de elementos.
Quadrado na fórmula acima irá anular o efeito do sinal negativo(-)

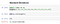
Desvio padrão :
É uma medida de dispersão da observação dentro do conjunto de dados em relação à sua média.É a raiz quadrada da variância e denotada por Sigma (σ) .
Desvio padrão é expresso na mesma unidade que os valores do conjunto de dados, de modo que ele mede o quanto as observações do conjunto de dados diferem da sua média.

Conclusão : Média / Mediana /Modo / Desvio / Desvio Padrão são conceitos simples mas muito importantes em estatística que todos devem conhecer .Espero que gostem do meu artigo. Por favor, carreguem em Clap 👏(50 vezes) para me motivar a escrever mais.
Quer ligar :
Linked In : https://www.linkedin.com/in/anjani-kumar-9b969a39/
Se gostarem dos meus posts aqui no Medium e quiserem que eu continue a fazer este trabalho, considerem apoiar-me no patreon