Introdução
Todos os compiladores são, é apenas um programa. O programa pega um input (que é o código fonte – aka um arquivo de bytes ou dados) e geralmente produz um programa de aparência completamente diferente, que agora é executável; ao contrário do input.
Na maioria dos sistemas operacionais modernos, os arquivos são organizados em arrays unidimensionais de bytes. O formato de um arquivo é definido pelo seu conteúdo, já que um arquivo é apenas um container de dados, embora, em algumas plataformas, o formato é normalmente indicado pela sua extensão de nome de arquivo, especificando as regras de como os bytes devem ser organizados e interpretados de forma significativa. Por exemplo, os bytes de um ficheiro de texto simples (
.txtno Windows) estão associados a caracteres ASCII ou UTF-8, enquanto os bytes de ficheiros de imagem, vídeo e áudio são interpretados de outra forma. (Wikipedia)
(https://en.wikipedia.org/wiki/Computer_file#File_contents)
O compilador está pegando seu código fonte legível por humanos, analisando-o, e então produzindo um código legível por computador chamado código de máquina (binário). Alguns compiladores irão (ao invés de ir direto para o código da máquina) ir para a montagem, ou uma linguagem diferente legível por humanos.
Línguas legíveis por humanos são línguas de alto nível AKA. Um compilador que vai de uma linguagem de alto nível para uma linguagem de alto nível diferente é chamado de compilador de fonte para fonte, transcompilador ou transpiler.
(https://en.wikipedia.org/wiki/Source-to-source_compiler)
int main() {
int a = 5;
a = a * 5;
return 0;
}
O acima é um programa em C escrito por um humano que faz o seguinte numa linguagem mais simples, ainda mais legível por humanos, chamada pseudo-código:
program 'main' returns an integer
begin
store the number '5' in the variable 'a'
'a' equals 'a' times '5'
return '0'
end
Pseudocódigo é uma descrição informal de alto nível do princípio de funcionamento de um programa de computador ou outro algoritmo. (Wikipedia)
(https://en.wikipedia.org/wiki/Pseudocode)
Compilaremos esse programa em C em código de montagem estilo Intel-, tal como um compilador faz. Embora um computador tenha que ser específico e seguir algoritmos para determinar o que faz palavras, inteiros e símbolos; nós podemos usar apenas o bom senso. Isso, por sua vez, torna nossa desambiguação muito mais curta do que para um compilador.
Esta análise é simplificada para facilitar a compreensão.
Tokenization
Antes de um computador poder decifrar um programa, ele deve primeiro dividir cada símbolo em seu próprio token. Um símbolo é a idéia de um caractere, ou agrupamento de caracteres, dentro de um arquivo fonte. Este processo é chamado de tokenization, e é feito por um tokenizer.
O nosso código fonte original seria dividido em tokens e mantido dentro da memória de um computador. Vou tentar transmitir a memória do computador no seguinte diagrama da produção do tokenizer.
Antes:
int main() {
int a = 5;
a = a * 5;
return 0;
}
Depois:
Diagrama é formatado à mão para legibilidade. Na realidade, ele não seria indentado ou dividido por linha.
Como você pode ver, ele cria uma forma muito literal do que foi dado a ele. Você deve ser capaz de quase replicar o código-fonte original dado apenas os tokens. Os tokens devem reter um tipo, e se o tipo pode ser de mais de um valor, o token também deve conter o valor correspondente.
Os tokens em si não são suficientes para compilar. Precisamos saber o contexto, e o que esses tokens significam quando colocados juntos. Isso nos leva ao parsing, onde podemos dar sentido a esses tokens.
Parsing
A fase de parsing pega tokens e produz uma árvore de sintaxe abstrata, ou AST. Ela essencialmente descreve a estrutura do programa, e pode ser usada para determinar como ele é executado, de uma forma muito – como o nome sugere – abstrata. É muito similar a quando você fez árvores gramaticais no inglês do ensino médio.
O analisador geralmente acaba sendo a parte mais complexa do compilador. Os analisadores são complexos e requerem muito trabalho e compreensão. É por isso que existem muitos programas por aí que podem gerar um parser inteiro dependendo de como você o descreve.
Estas ‘ferramentas de criação de parser’ são chamadas de geradores de parser. Os geradores de parser são específicos para idiomas, pois geram o parser no código do idioma em questão. Bison (C/C+++) é um dos geradores de analisadores mais conhecidos no mundo.
O analisador, em suma, tenta combinar tokens com padrões já definidos de tokens. Por exemplo, podemos dizer que a atribuição toma a seguinte forma de fichas, usando EBNF:
EBNF (ou um dialeto, do mesmo) é comumente usado em geradores de parser para definir a gramática.
>
assignment = identifier, equals, int | identifier ;
Atuando os seguintes padrões de fichas são considerados como uma atribuição:
a = 5
or
a = a
or
b = 123456789
Mas os seguintes padrões não são, embora devam ser:
int a = 5
or
a = a * 5
Aquelas que não funcionam não são impossíveis, mas requerem maior desenvolvimento e complexidade dentro do analisador antes de poderem ser implementadas por completo.
Ler o seguinte artigo da Wikipedia se você estiver mais interessado em como os analisadores funcionam. https://en.wikipedia.org/wiki/Parsing
Teóricamente, após o nosso analisador ser feito, ele geraria uma árvore de sintaxe abstrata como a seguinte:
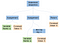
Em informática, uma árvore de sintaxe abstrata (AST), ou apenas árvore de sintaxe, é uma representação em árvore da estrutura sintática abstrata do código fonte escrito em uma linguagem de programação. (Wikipedia)
(https://en.wikipedia.org/wiki/Abstract_syntax_tree)
Após a árvore de sintaxe abstrata estabelecer a ordem de execução de alto nível, e as operações a realizar, torna-se bastante simples começar a gerar código assembly.
Geração de código
Desde que a AST contém ramos que definem quase inteiramente o programa, podemos passar por esses ramos, gerando sequencialmente o assembly equivalente. Isto é chamado de “andar na árvore”, e é um algoritmo para geração de código usando um AST.
Geração de código imediatamente após a análise não é comum para compiladores mais complexos, pois eles passam por mais fases antes de ter um AST final, como intermediário, otimização, etc. Existem mais técnicas para geração de código.
https://en.wikipedia.org/wiki/Code_generation_(compiler)
Compilamos para montagem porque um único assembler pode produzir código de máquina para qualquer uma, ou para algumas arquiteturas diferentes de CPU. Por exemplo, se nosso compilador gerasse a montagem NASM, nossos programas seriam compatíveis com arquiteturas Intel x86 (16-bit, 32-bit, e 64-bit). Compilar diretamente no código da máquina não seria tão eficaz, porque precisaríamos escrever um backend para cada arquitetura de destino independentemente. Embora, seria bastante demorado, e com menos ganho do que usar um assembler de terceiros.
Com LLVM, você pode simplesmente compilar para LLVM IR e ele lida com o resto. Ele compila para uma grande variedade de linguagens assembler, e assim compila para muitas outras arquiteturas. Se você já ouviu falar de LLVM antes, você provavelmente verá porque ele é tão apreciado, agora.
https://en.wikipedia.org/wiki/LLVM
Se nós entrássemos nos ramos da sequência de comandos, encontraríamos todos os comandos que são executados da esquerda para a direita. Podemos descer esses ramos da esquerda para a direita, colocando o código de montagem equivalente. Toda vez que terminamos um ramo, temos que voltar para cima e começar a trabalhar em um novo ramo.
O ramo mais à esquerda da nossa sequência de comandos contém a primeira atribuição a uma nova variável inteira, a. O valor atribuído é uma folha que contém o valor integral constante, 5. Semelhante ao ramo mais à esquerda, o ramo do meio é uma atribuição. Ela atribui a operação binária (bin op) de multiplicação entre a e 5, para a . Para simplificar só referimos a duas vezes do mesmo nó, ao invés de ter dois a nós.
O ramo final é apenas um retorno e é para o código de saída do programa. Dizemos ao computador que ele saiu normalmente retornando zero.
O seguinte é a produção do Compilador C GNU (x86-64 GCC 8.1) dado o nosso código fonte sem otimizações.
Calma, o compilador não gerou os comentários ou espaçamentos.
main:
push rbp
mov rbp, rsp
mov DWORD PTR , 5 ; leftmost branch
mov edx, DWORD PTR ; middle branch
mov eax, edx
sal eax, 2
add eax, edx
mov DWORD PTR , eax
mov eax, 0 ; rightmost branch
pop rbp
ret
Uma ferramenta incrível; o Compiler Explorer de Matt Godbolt, permite que você escreva código e veja as produções de montagem do compilador em tempo real. Tente nosso experimento em https://godbolt.org/g/Uo2Z5E.
O gerador de código normalmente tenta otimizar o código de alguma forma. Nós tecnicamente nunca usamos a nossa variável a. Mesmo que a atribuamos a ela, nunca mais a lemos. Um compilador deve reconhecer isto e finalmente remover toda a variável na produção final da montagem. Nossa variável permaneceu porque não compilamos com otimizações.
Você pode adicionar argumentos para o compilador no Compiler Explorer.
-O3é uma bandeira para o GCC que significa otimização máxima. Tente adicioná-lo, e veja o que acontece com o código gerado.
Após o código assembly ter sido gerado, podemos compilar o assembly até o código máquina, usando um assembler. O código da máquina só funciona para a arquitetura da CPU de destino único. Para ter uma nova arquitetura, precisamos adicionar essa arquitetura assembly target para ser produzida pelo nosso gerador de código.
O assembler que você usa para compilar o assembly até o código máquina também é escrito em uma linguagem de programação. Ele poderia até mesmo ser escrito em sua própria linguagem assembly. Escrever um compilador na linguagem que ele compila é chamado de bootstrapping.
https://en.wikipedia.org/wiki/Bootstrapping_(compilers)
Conclusion
Compilers pegam texto, analisam e processam, depois o transformam em binário para o seu computador ler. Isto evita que você tenha que escrever binário manualmente para o seu computador, e além disso, permite-lhe escrever programas complexos mais facilmente.
Backmatter
E é isso! Nós tokenized, parsed, e geramos nosso código fonte. Espero que você tenha uma maior compreensão de computadores e softwares depois de ter lido isto. Se você ainda estiver confuso, basta checar alguns dos recursos de aprendizado que eu listei no final. Eu nunca tive tudo isso em baixo depois de ler um artigo. Se você tiver alguma pergunta, veja se alguém já a fez antes de levar para a seção de comentários.