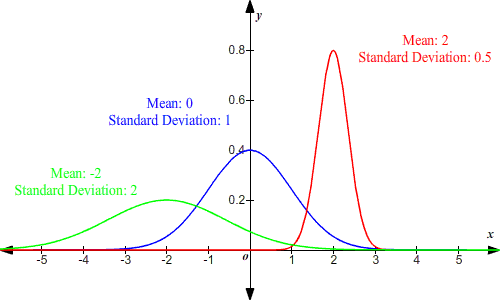
Een normale verdeling is een gebruikelijke kansverdeling. Zij heeft een vorm die vaak wordt aangeduid als een “belcurve”.
Veel alledaagse gegevensverzamelingen volgen doorgaans een normale verdeling: bijvoorbeeld de lengte van volwassen mensen, de scores op een toets die aan een grote klas wordt gegeven, fouten in metingen.
De normale verdeling is altijd symmetrisch rond het gemiddelde.
De standaardafwijking is de maat voor de spreiding van een normaal verdeelde reeks gegevens. Het is een statistiek die aangeeft hoe dicht alle voorbeelden rond het gemiddelde in een gegevensverzameling zijn verzameld. De vorm van een normale verdeling wordt bepaald door het gemiddelde en de standaardafwijking. Hoe steiler de klokcurve, hoe kleiner de standaardafwijking. Als de voorbeelden ver uit elkaar liggen, zal de klok veel vlakker zijn, wat betekent dat de standaardafwijking groot is.
In het algemeen ligt ongeveer 68 % van het gebied onder een normale verdelingskromme binnen één standaardafwijking van het gemiddelde.
Dat wil zeggen, als x ¯ het gemiddelde is en σ de standaardafwijking van de verdeling, dan valt 68 % van de waarden in het bereik tussen ( x ¯ – σ ) en ( x ¯ + σ ) . In de onderstaande figuur komt dit overeen met het roze gearceerde gebied.
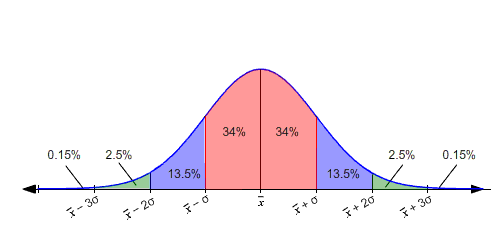
Ongeveer 95 % van de waarden ligt binnen twee standaardafwijkingen van het gemiddelde, d.w.z. tussen ( x ¯ – 2 σ ) en ( x ¯ + 2 σ ) .
(In de figuur is dit de som van de roze en blauwe gebieden: 34 % + 34 % + 13.5 % + 13.5 % = 95 % .)
Ongeveer 99,7 % van de waarden ligt binnen drie standaardafwijkingen van het gemiddelde, dat wil zeggen tussen ( x ¯ – 3 σ ) en ( x ¯ + 3 σ ) .
(De roze, blauwe en groene gebieden in de figuur.)
(Merk op dat deze waarden bij benadering zijn.)
Voorbeeld 1:
Een reeks gegevens is normaal verdeeld met een gemiddelde van 5 . Hoeveel procent van de gegevens is kleiner dan 5 ?
Een normale verdeling is symmetrisch rond het gemiddelde. Dus de helft van de gegevens zal kleiner zijn dan het gemiddelde en de helft van de gegevens zal groter zijn dan het gemiddelde.
Daarom is 50 procent van de gegevens kleiner dan 5 .
Voorbeeld 2:
De levensduur van een volledig opgeladen batterij van een mobiele telefoon is normaal verdeeld met een gemiddelde van 14 uur met een standaardafwijking van 1 uur. Wat is de kans dat een batterij ten minste 13 uur meegaat?
Het gemiddelde is 14 en de standaardafwijking is 1 .
50 % van de normale verdeling ligt rechts van het gemiddelde, dus 50 % van de tijd gaat de batterij langer mee dan 14 uur.
Het interval van 13 tot 14 uur vertegenwoordigt één standaardafwijking links van het gemiddelde. In ongeveer 34 % van de gevallen gaat de batterij dus tussen 13 en 14 uur mee.
De kans dat de batterij het ten minste 13 uur volhoudt, is dus ongeveer 34 % + 50 % of 0,84 .
Voorbeeld 3:
Het gemiddelde gewicht van een framboos is 4,4 gm met een standaardafwijking van 1,3 gm. Hoe groot is de kans dat een willekeurig gekozen framboos ten minste 3,1 gm maar niet meer dan 7,0 gm weegt?
Het gemiddelde is 4,4 en de standaardafwijking is 1,3 .
Merk op dat
4,4 – 1,3 = 3,1
en
4,4 + 2 ( 1,3 ) = 7,0
Het interval 3,1 ≤ x ≤ 7,0 ligt dus eigenlijk tussen 1 standaardafwijking onder het gemiddelde en 2 standaardafwijkingen boven het gemiddelde.
Bij normaal verdeelde gegevens ligt ongeveer 34 % van de waarden tussen het gemiddelde en één standaardafwijking onder het gemiddelde, en 34 % tussen het gemiddelde en één standaardafwijking boven het gemiddelde.
Bovendien ligt 13,5 % van de waarden tussen de eerste en de tweede standaardafwijking boven het gemiddelde.
Als we de oppervlakten optellen, krijgen we 34 % + 34 % + 13,5 % = 81,5 % .
De kans dat een willekeurig gekozen framboos ten minste 3,1 gram weegt, maar niet meer dan 7,0 gram, is dus 81,5 % of 0,815 .
Voorbeeld 4:
Een stad telt 330.000 volwassenen. Hun lengte is normaal verdeeld met een gemiddelde van 175 cm en een variantie van 100 cm 2. Hoeveel mensen zijn naar verwachting langer dan 205 cm?
De variantie van de gegevensverzameling is gegeven als 100 cm 2 . De standaardafwijking is dus 100 of 10 cm.
Nu is 175 + 3 ( 10 ) = 205 , dus het aantal mensen dat groter is dan 205 cm komt overeen met de deelverzameling van gegevens die meer dan 3 standaardafwijkingen boven het gemiddelde ligt.
Uit bovenstaande grafiek blijkt dat dit ongeveer 0,15 % van de gegevens is. Dit percentage is echter bij benadering, en in dit geval hebben we meer precisie nodig. Het werkelijke percentage, tot op 4 decimalen nauwkeurig, is 0,1318 % .
330 , 000 × 0,001318 ≈ 435
Er zullen dus ongeveer 435 mensen in de stad zijn die langer zijn dan 205 cm.