Inleiding
Alles wat een compiler is, is slechts een programma. Het programma neemt een invoer (de broncode, ook wel een bestand van bytes of gegevens genoemd) en produceert in het algemeen een heel ander uitziend programma, dat nu uitvoerbaar is; in tegenstelling tot de invoer.
Op de meeste moderne besturingssystemen zijn bestanden georganiseerd in eendimensionale arrays van bytes. Het formaat van een bestand wordt bepaald door de inhoud, aangezien een bestand uitsluitend een container voor gegevens is, hoewel het formaat op sommige platforms meestal wordt aangegeven door de extensie van de bestandsnaam, die de regels specificeert voor hoe de bytes moeten worden georganiseerd en zinvol geïnterpreteerd. Bijvoorbeeld, de bytes van een tekstbestand (
.txtin Windows) worden geassocieerd met ASCII of UTF-8 tekens, terwijl de bytes van beeld-, video- en audiobestanden anders worden geïnterpreteerd. (Wikipedia)
(https://en.wikipedia.org/wiki/Computer_file#File_contents)
De compiler neemt uw door mensen leesbare broncode, analyseert deze, en produceert vervolgens een door de computer leesbare code die machinecode (binair) wordt genoemd. Sommige compilers gaan (in plaats van rechtstreeks naar machinecode) naar assemblage, of een andere door mensen leesbare taal.
Menselijk leesbare talen zijn AKA-talen op hoog niveau. Een compiler die van de ene high-level taal naar een andere high-level taal gaat, wordt een source-to-source compiler, transcompiler of transpiler genoemd.
(https://en.wikipedia.org/wiki/Source-to-source_compiler)
int main() {
int a = 5;
a = a * 5;
return 0;
}
Het bovenstaande is een door een mens geschreven C-programma dat het volgende doet in een eenvoudigere, nog menselijker leesbare taal die pseudocode wordt genoemd:
program 'main' returns an integer
begin
store the number '5' in the variable 'a'
'a' equals 'a' times '5'
return '0'
end
Pseudocode is een informele beschrijving op hoog niveau van het werkingsprincipe van een computerprogramma of ander algoritme. (Wikipedia)
(https://en.wikipedia.org/wiki/Pseudocode)
We zullen dat C-programma compileren in assemblagecode in Intel-stijl, net zoals een compiler dat doet. Hoewel een computer specifiek moet zijn en algoritmen moet volgen om te bepalen wat woorden, gehele getallen en symbolen zijn, kunnen wij gewoon ons gezond verstand gebruiken. Dat maakt onze ontleding weer veel korter dan bij een compiler.
Deze analyse is vereenvoudigd voor een beter begrip.
Tokenization
Voordat een computer een programma kan ontcijferen, moet hij eerst elk symbool opsplitsen in zijn eigen token. Een token is het idee van een karakter, of een groep karakters, in een bronbestand. Dit proces wordt tokenization genoemd, en het wordt gedaan door een tokenizer.
Onze oorspronkelijke broncode zou worden opgesplitst in tokens en in het geheugen van een computer worden bewaard. Ik zal proberen het geheugen van de computer weer te geven in het volgende diagram van de productie van de tokenizer.
Voor:
int main() {
int a = 5;
a = a * 5;
return 0;
}
Na:
Diagram is met de hand geformatteerd voor de leesbaarheid. In werkelijkheid zou het niet worden ingesprongen of per regel worden gesplitst.
Zoals u kunt zien, creëert het een zeer letterlijke vorm van wat het werd gegeven. Je zou in staat moeten zijn om bijna de originele broncode te reproduceren, gegeven alleen de tokens. Tokens moeten een type behouden, en als het type meer dan een waarde kan hebben, moet het token ook de overeenkomstige waarde bevatten.
De tokens zelf zijn niet genoeg om te compileren. We moeten de context kennen, en weten wat die tokens betekenen als ze samengevoegd worden. Dat brengt ons bij parsing, waar we de betekenis van die tokens kunnen achterhalen.
Parsing
De parsing-fase neemt tokens en produceert een abstracte syntax-boom, of AST. Deze beschrijft in wezen de structuur van het programma, en kan worden gebruikt om te bepalen hoe het wordt uitgevoerd, op een zeer – zoals de naam al suggereert – abstracte manier. Het lijkt erg op het maken van grammatica bomen op de middelbare school Engels.
De parser eindigt over het algemeen als het meest complexe deel van de compiler. Parsers zijn ingewikkeld en vereisen veel werk en begrip. Daarom zijn er veel programma’s die een complete parser kunnen genereren, afhankelijk van hoe je die beschrijft.
Deze ‘parser creator tools’ worden parser generators genoemd. Parser-generatoren zijn specifiek voor talen, omdat ze de parser genereren in de code van die taal. Bison (C/C++) is een van de bekendste parser-generatoren ter wereld.
De parser, in het kort, probeert lopers te matchen met reeds gedefinieerde patronen van lopers. We zouden bijvoorbeeld kunnen zeggen dat toewijzing de volgende vorm van tokens aanneemt, met gebruikmaking van EBNF:
EBNF (of een dialect daarvan) wordt gewoonlijk gebruikt in parser-generatoren om de grammatica te definiëren.
assignment = identifier, equals, int | identifier ;
De volgende patronen van tokens worden beschouwd als een toewijzing:
a = 5
or
a = a
or
b = 123456789
Maar de volgende patronen zijn dat niet, hoewel ze dat wel zouden moeten zijn:
int a = 5
or
a = a * 5
De patronen die niet werken zijn niet onmogelijk, maar vereisen eerder verdere ontwikkeling en complexiteit binnen de parser voordat ze volledig kunnen worden geïmplementeerd.
Lees het volgende Wikipedia-artikel als u meer wilt weten over hoe parsers werken. https://en.wikipedia.org/wiki/Parsing
Theoretisch zou onze parser na het parseren een abstracte syntaxisboom genereren zoals hieronder:
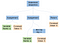
In de informatica is een abstracte syntaxisboom (AST), of gewoon syntaxisboom, een boomweergave van de abstracte syntactische structuur van broncode geschreven in een programmeertaal. (Wikipedia)
(https://en.wikipedia.org/wiki/Abstract_syntax_tree)
Nadat de abstracte syntaxisboom de high-level volgorde van uitvoering en de uit te voeren bewerkingen uiteenzet, wordt het vrij eenvoudig om te beginnen met het genereren van assemblagecode.
Code generatie
Omdat de AST takken bevat die bijna volledig het programma definiëren, kunnen we door die takken stappen en sequentieel de equivalente assemblage genereren. Dit wordt “walking the tree” genoemd, en het is een algoritme voor codegeneratie met behulp van een AST.
Codegeneratie onmiddellijk na parsing is niet gebruikelijk voor complexere compilers, aangezien deze meer fasen doorlopen alvorens een definitieve AST te hebben, zoals intermediair, optimalisatie, enz. Er zijn meer technieken voor het genereren van code.
https://en.wikipedia.org/wiki/Code_generation_(compiler)
We compileren naar assemblage omdat een enkele assembler machinecode kan produceren voor één, of een paar verschillende CPU-architecturen. Als onze compiler bijvoorbeeld NASM-assemblage zou genereren, zouden onze programma’s compatibel zijn met Intel x86-architecturen (16-bit, 32-bit en 64-bit). Rechtstreeks compileren naar machinecode zou niet zo effectief zijn, omdat we dan voor elke doelarchitectuur apart een backend zouden moeten schrijven. Hoewel, het zou behoorlijk tijdrovend zijn, en met minder winst dan het gebruik van een assembler van een derde partij.
Met LLVM kun je gewoon compileren naar LLVM IR en het regelt de rest. Het compileert naar een breed scala aan assemblertalen, en dus naar veel meer architecturen. Als u al eerder van LLVM hebt gehoord, ziet u nu waarschijnlijk waarom het zo geliefd is.
https://en.wikipedia.org/wiki/LLVM
Als we in de takken van de statementreeks zouden stappen, zouden we alle statements vinden die van links naar rechts worden uitgevoerd. We kunnen die takken van links naar rechts aflopen en de equivalente assemblagecode plaatsen. Elke keer als we klaar zijn met een tak, moeten we terug omhoog gaan en beginnen te werken aan een nieuwe tak.
De meest linkse tak van onze statement reeks bevat de eerste toewijzing aan een nieuwe integer variabele, a. De toegewezen waarde is een blad dat de constante integraal bevat, 5. Net als de meest linkse tak, is de middelste tak een toewijzing. Het wijst de binaire operatie (bin op) van vermenigvuldiging tussen a en 5, toe aan a . Voor de eenvoud verwijzen we gewoon twee keer naar a vanuit hetzelfde knooppunt, in plaats van twee a knooppunten te hebben.
De laatste tak is gewoon een return en het is voor de exit code van het programma. We vertellen de computer dat het normaal is verlopen door nul terug te geven.
Het volgende is de productie van de GNU C Compiler (x86-64 GCC 8.1) gegeven onze broncode zonder optimalisaties.
Bedenk wel dat de compiler niet het commentaar of de spatiëring heeft gegenereerd.
main:
push rbp
mov rbp, rsp
mov DWORD PTR , 5 ; leftmost branch
mov edx, DWORD PTR ; middle branch
mov eax, edx
sal eax, 2
add eax, edx
mov DWORD PTR , eax
mov eax, 0 ; rightmost branch
pop rbp
ret
Een geweldige tool; de Compiler Explorer van Matt Godbolt, stelt je in staat om code te schrijven en de assemblage producties van de compiler in real-time te zien. Probeer ons experiment op https://godbolt.org/g/Uo2Z5E.
De code generator probeert meestal om de code op een of andere manier te optimaliseren. Technisch gezien gebruiken we onze variabele a nooit. Ook al wijzen we er aan toe, we lezen het nooit meer. Een compiler zou dit moeten herkennen en uiteindelijk de hele variabele moeten verwijderen in de uiteindelijke assemblage. Onze variabele is erin gebleven omdat we niet met optimalisaties hebben gecompileerd.
U kunt argumenten toevoegen aan de compiler in de Compiler Explorer.
-O3is een vlag voor GCC die maximale optimalisatie betekent. Probeer deze toe te voegen en kijk wat er gebeurt met de gegenereerde code.
Nadat de assemblagecode is gegenereerd, kunnen we de assemblage compileren tot machinecode, met behulp van een assembler. De machinecode werkt alleen voor de enkele doel-CPU-architectuur. Als we een nieuwe architectuur willen gebruiken, moeten we die architectuur toevoegen aan onze codegenerator.
De assembler die u gebruikt om de assembly te compileren tot machinecode is ook geschreven in een programmeertaal. Hij kan zelfs in zijn eigen assembleertaal zijn geschreven. Het schrijven van een compiler in de taal die hij compileert, wordt bootstrapping genoemd.
https://en.wikipedia.org/wiki/Bootstrapping_(compilers)
Conclusie
Compilers nemen tekst, parseren en verwerken die, en zetten die vervolgens om in binaire code die uw computer kan lezen. Hierdoor hoeft u niet handmatig binair voor uw computer te schrijven, en kunt u bovendien gemakkelijker complexe programma’s schrijven.
Backmatterie
En dat is het! We hebben onze broncode getoken, geparsed, en gegenereerd. Ik hoop dat je na dit gelezen te hebben een beter begrip hebt van computers en software. Als je nog steeds verward bent, kijk dan eens naar de leermiddelen die ik onderaan heb opgesomd. Ik heb dit nooit allemaal begrepen na het lezen van één artikel. Als je vragen hebt, kijk dan eerst of iemand anders ze al gesteld heeft voordat je naar de commentaarsectie gaat.