Het is zondagochtend, de roosters zijn bijna klaar voor de vroege middag slate, en je bent aan het kiezen tussen twee negende rang WRs voor die WR3 slot. Het is Week 3, het zijn allebei waiver wire desperation picks waar je geen tijd voor had om te onderzoeken, en eerlijk gezegd, heb je vandaag andere vissen te bakken. Zie: de ESPN Projected score voor de een is 7, voor de ander is 8. Je kiest voor de 8 en denkt: “die projected score moet toch iets betekenen?”
tl;dr Die projected score betekent in wezen niets, en we kunnen het laten zien, met behulp van de (ongedocumenteerde) ESPN Fantasy API en een beetje Python.
Een beetje achtergrond
Mike Clay is de man achter het gordijn van ESPN’s fantasy projecties. Hij zweert dat hij een “langdurig proces” heeft dat bestaat uit “statistische berekeningen en subjectieve inputs.” Ik bedoel, hij wordt betaald en ik schrijf blogberichten, dus ik kan niet te veel haten op wat dit mysterieuze statistische proces ook mag zijn.
Hoe dan ook, er zijn veel analyses geweest die ESPN’s projecties vergelijken met andere sites over het hele spectrum, van intense reddit-posts tot NYT-blogposts.
De consensus lijkt te zijn, ESPN’s projecties zijn niet erg goed, gebaseerd op metrieken als “nauwkeurigheid” en R-kwadraat die proberen om de totale fout te kwantificeren met een enkele samenvatting statistiek.
Maar ik merk ook dat er zeer weinig info over hoe dit te controleren voor jezelf. Deze site van footballanalytics.net linkt naar een aantal geweldige R scripts, maar ik heb niet gezien dat een specifiek ESPN projecties pakt (hoewel ik me kan vergissen).
Exploring …
ESPN houdt op dit moment één historisch seizoen van projecties bij, dus laten we 2018 pakken en kijken wat we vinden.
We zullen gebruik maken van de ESPN Fantasy API die ik hier behandel hoe te gebruiken.
We gaan, in een notendop, ESPN hetzelfde GET-verzoek sturen dat zijn website naar zijn eigen servers stuurt wanneer we naar een historische competitiepagina navigeren. Je kunt afluisteren hoe deze verzoeken tot stand komen door gebruik te maken van Safari’s Web Developer tools of een proxy service als Charles of Fiddler.
Voordat we code schrijven om alle data te verzamelen die we nodig hebben, laten we eerst een klein stukje verkennen:
import requestsswid = 'YOUR_SWID'espn_s2 = 'LONG_ESPN_S2_KEY'league_id = 123456season = 2018week = 5url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn})d = r.json()Dit wordt iets gedetailleerder uitgelegd in mijn vorige post, maar het idee is dat we een verzoek sturen naar ESPN’s API voor een specifieke weergave van een specifieke competitie, week en seizoen die ons volledige matchup/boxscore info zal geven inclusief verwachte punten. De cookies zijn alleen nodig voor privécompetities, en nogmaals, ik behandel het hier.
Als je door de JSON-structuur navigeert, zul je merken dat elk fantasy-team een roster van zijn spelers heeft, en elke speler heeft een lijst met zijn stats.
(Nogmaals, een goede manier om door deze structuur te navigeren is met Safari’s Web Developer tools: ga naar een interessante pagina in het clubhuis van je fantasy league, open Web Developer tools, ga naar Resources, kijk dan onder XHRs voor een object met je league ID. Dit zal de ruwe tekst van de JSON zijn … verander “Response” in “JSON” in de kleine kop voor een meer gebruiksvriendelijke explorer-stijl interface.)
Grabbing all 2018 Projections
Het is een beetje verborgen, maar binnen deze substructuur zijn de verwachte en werkelijke fantasy-punten voor elke speler op elk roster.
Het viel me op dat de stats-lijst voor een bepaalde speler 5-6 vermeldingen heeft, waarvan de ene altijd de geprojecteerde score is en de andere de werkelijke. De verwachte score wordt aangeduid met statSourceId=1, de werkelijke met statSourceId=0.
Laten we deze observatie gebruiken om een reeks lussen te bouwen om GET verzoeken voor elke week te verzenden, en dan elke verwachte/werkelijke score voor elke speler op elk rooster te extraheren.
import requestsimport pandas as pdleague_id = 123456season = 2018slotcodes = { 0 : 'QB', 2 : 'RB', 4 : 'WR', 6 : 'TE', 16: 'Def', 17: 'K', 20: 'Bench', 21: 'IR', 23: 'Flex'}url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'data = print('Week ', end='')for week in range(1, 17): print(week, end=' ') r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn}) d = r.json() for tm in d: tmid = tm for p in tm: name = p slot = p pos = slotcodes # injured status (need try/exc bc of D/ST) inj = 'NA' try: inj = p except: pass # projected/actual points proj, act = None, None for stat in p: if stat != week: continue if stat == 0: act = stat elif stat == 1: proj = stat data.append()print('\nComplete.')data = pd.DataFrame(data, columns=)Week 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Complete.We krijgen iets als dit:
data.head() Week Team Player Slot Pos Status Proj Actual0 1 1 Leonard Fournette 2 RB QUESTIONABLE 13.891825 5.01 1 1 Christian McCaffrey 2 RB ACTIVE 11.067053 7.02 1 1 Derrick Henry 20 Bench ACTIVE 10.271163 2.03 1 1 Josh Gordon 4 WR OUT 6.153141 7.04 1 1 Philip Rivers 0 QB QUESTIONABLE 26.212294 42.0Ja, ja, dit zijn alleen spelers op roosters, dus we nemen geen vrije spelers op … maar het zou ons in ieder geval een idee moeten geven van de nauwkeurigheid van ESPN’s projecties, voor nu.
Laten we “Proj” tegen “Actual” uitzetten voor een paar verschillende posities en onze vingers kruisen …
fig, axs = plt.subplots(1,3, sharey=True, figsize=(12, 4))for i, pos in enumerate(): (data .query('Pos == @pos') .pipe((axs.scatter, 'data'), x='Proj', y='Actual', s=50, c='b', alpha=0.5) ) axs.plot(, , 'k--') axs.set(xlim=, ylim=, xlabel='Projected', title=pos)axs.set_ylabel('Actual')plt.tight_layout()plt.show()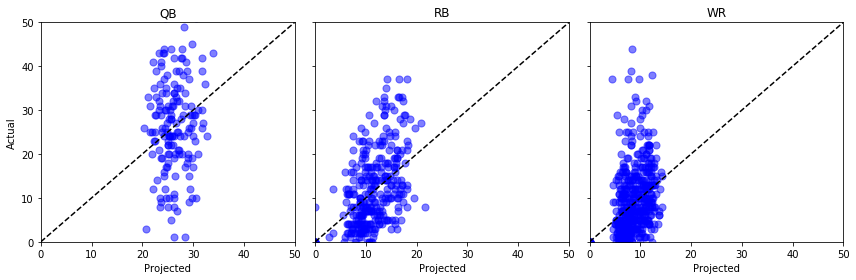
Um, niet geweldig. We zouden hier wat statistische tests kunnen doen, maar voor mijn ongetrainde oog lijkt het erop dat die geprojecteerde punten net zo goed uit een uniforme verdeling kunnen komen.
Misschien is het in bepaalde weken beter? Later in het seizoen, misschien? Laten we de totale fout plotten, per week, per positie. Deze code wordt een beetje hacky 🙁 maar ik ben bereid ermee te leven:
fig, axs = plt.subplots(1,3, sharey=True, figsize=(13,4))data = data - datadata = pd.cut(data, bins=4, labels=)cols = sns.color_palette('Blues')# dummy plots for a legendfor k,cat in enumerate(): axs.plot(,, c=cols, label='Wk ' + cat)axs.legend()for i, pos in enumerate(): for cat in range(4): t = data.query('Pos == @pos & Cat == @cat') sns.kdeplot(t, color=cols, ax=axs, legend=False) axs.set(xlabel='Actual - Proj', title=pos) plt.show()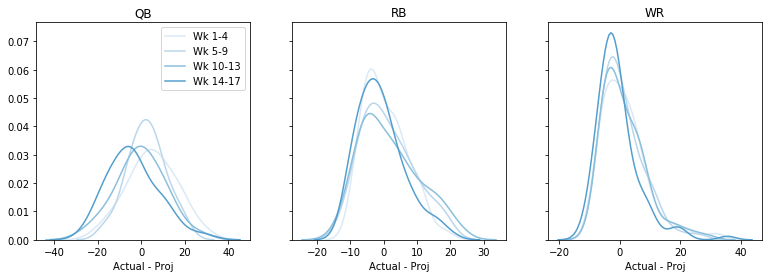
Misschien is er een tendens om later in het seizoen over te projecteren, maar over het algemeen zou ik ook hier niets zeggen. (Merk op dat we door dit te doen wat informatie kwijtraakten over de vraag of de fout meer of minder is voor hoge versus lage projecties.)
Ik wil nu graag kijken naar de tijdreeksen van de punten van spelers. Het gezond verstand zegt dat de beste manier om te raden wat een speler volgende week zal scoren is om gewoon naar zijn laatste 4-5 weken te kijken … hoe betrouwbaar is deze strategie?
In deze post probeer ik ESPN projecties op een rooster niveau te controleren – misschien zijn de individuele projecties niet indrukwekkend, maar in totaal beginnen ze op magische wijze te helpen? (Spoiler: niet echt.)
Geschreven op 5 augustus 2019 door Steven Morse