It’s Sunday morning, rosters are about locking for early afternoon slate, and you are deciding between two ninth tier WRs for that WR3 slot. そのため、このような「曖昧さ」があるのです。 見よ、ESPN予想スコアは1人が7で、もう1人が8だ。 あなたは8を選び、「この予想スコアは何か意味があるはずだ」と考える。
tl;dr その予想スコアには本質的に意味がなく、ESPNファンタジーAPIとちょっとしたPythonを使ってそれを示すことができる。 彼は、「統計的な計算と主観的な入力」を含む「長いプロセス」を持っていると断言します。 彼はお金をもらっていて、私はブログ記事を書いているので、この謎の統計的プロセスが何であろうと、あまり嫌うことはできません。
「精度」や「R2乗」のような単一の要約統計で全体的な誤差を定量化しようとする指標に基づいて、ESPN の予測はあまり良くないというのがコンセンサスになっているようです。
Exploring …
ESPN は現時点では予測の歴史的な 1 シーズンを維持しているので、2018 年を取得し、何が見つかるかを見てみましょう。
ここでは、ESPN Fantasy API を使用します。
簡単に言うと、過去のリーグ ページに移動したときに ESPN の Web サイトが自身のサーバーに送信するのと同じ GET リクエストを送信します。 Safari の Web Developer ツール、または Charles や Fiddler などのプロキシ サービスを使用すると、これらの要求がどのように形成されるかを盗み見ることができます。
必要なデータをすべて取得するコードを書く前に、その一部を探ってみましょう。
import requestsswid = 'YOUR_SWID'espn_s2 = 'LONG_ESPN_S2_KEY'league_id = 123456season = 2018week = 5url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn})d = r.json()これは以前の投稿でもう少し詳しく説明しましたが、特定のリーグ、週、シーズンについて、予想ポイントを含むすべてのマッチアップ/ボックススコア情報を提供するための要求を ESPN の API に送信しているということです。 Cookie はプライベート リーグにのみ必要で、ここでも説明しています。
JSON構造を移動すると、各ファンタジー チームにはプレーヤーの roster があり、各プレーヤーにはその stats のリストがあることが分かります。
(この構造をナビゲートするには、Safari の Web Developer ツールを使用します:ファンタジー リーグのクラブハウスで関心のあるページに行き、Web Developer ツールを開き、リソースに移動して、XHRs でリーグ ID のオブジェクトを探します。 これは、JSON の生のテキストになります…小さなヘッダー領域で「Response」を「JSON」に変更すると、より使いやすいエクスプローラ スタイルのインターフェイスになります)
Grabbing all 2018 Projections
少し隠れていますが、このサブ構造の中に、各ロースター上の各プレーヤーの予測および実際のファンタジー ポイントが含まれています。
私は、特定の選手のstatsリストには5~6個のエントリがあり、そのうちの1つは常に予測スコアで、もう1つは実際であることに気づきました。 予測スコアは statSourceId=1 で、実際のスコアは statSourceId=0 で識別されます。
この観察を使用して、各週の GET 要求を送信し、各ロースター上の各選手の予測/実際のスコアを抽出する一連のループを構築してみましょう。
import requestsimport pandas as pdleague_id = 123456season = 2018slotcodes = { 0 : 'QB', 2 : 'RB', 4 : 'WR', 6 : 'TE', 16: 'Def', 17: 'K', 20: 'Bench', 21: 'IR', 23: 'Flex'}url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'data = print('Week ', end='')for week in range(1, 17): print(week, end=' ') r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn}) d = r.json() for tm in d: tmid = tm for p in tm: name = p slot = p pos = slotcodes # injured status (need try/exc bc of D/ST) inj = 'NA' try: inj = p except: pass # projected/actual points proj, act = None, None for stat in p: if stat != week: continue if stat == 0: act = stat elif stat == 1: proj = stat data.append()print('\nComplete.')data = pd.DataFrame(data, columns=)Week 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Complete.このようなものが得られます。
Week Team Player Slot Pos Status Proj Actual0 1 1 Leonard Fournette 2 RB QUESTIONABLE 13.891825 5.01 1 1 Christian McCaffrey 2 RB ACTIVE 11.067053 7.02 1 1 Derrick Henry 20 Bench ACTIVE 10.271163 2.03 1 1 Josh Gordon 4 WR OUT 6.153141 7.04 1 1 Philip Rivers 0 QB QUESTIONABLE 26.212294 42.0そうそう、これはロースターに登録されている選手だけなので、フリーエージェントは捕捉していないのですが…少なくとも、今のところはESPNの予測の精度がわかるはずです。
いくつかの異なるポジションについて、「Proj」と「Actual」をプロットし、指をくわえて見てみましょう…
fig, axs = plt.subplots(1,3, sharey=True, figsize=(12, 4))for i, pos in enumerate(): (data .query('Pos == @pos') .pipe((axs.scatter, 'data'), x='Proj', y='Actual', s=50, c='b', alpha=0.5) ) axs.plot(, , 'k--') axs.set(xlim=, ylim=, xlabel='Projected', title=pos)axs.set_ylabel('Actual')plt.tight_layout()plt.show()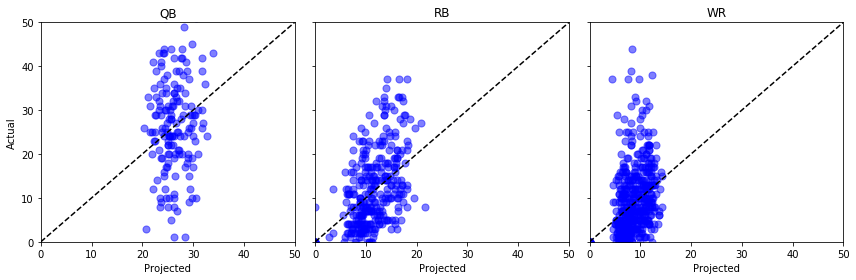
うーん、イマイチですね。 ここでいくつかの統計的なテストを行うことができますが、私の素人目には、これらの予測されたポイントは、均一な分布から出ているのと同じように見えます。 シーズンの後半に、多分? 週ごとに、ポジションごとに、全体の誤差をプロットしてみましょう。
fig, axs = plt.subplots(1,3, sharey=True, figsize=(13,4))data = data - datadata = pd.cut(data, bins=4, labels=)cols = sns.color_palette('Blues')# dummy plots for a legendfor k,cat in enumerate(): axs.plot(,, c=cols, label='Wk ' + cat)axs.legend()for i, pos in enumerate(): for cat in range(4): t = data.query('Pos == @pos & Cat == @cat') sns.kdeplot(t, color=cols, ax=axs, legend=False) axs.set(xlabel='Actual - Proj', title=pos) plt.show()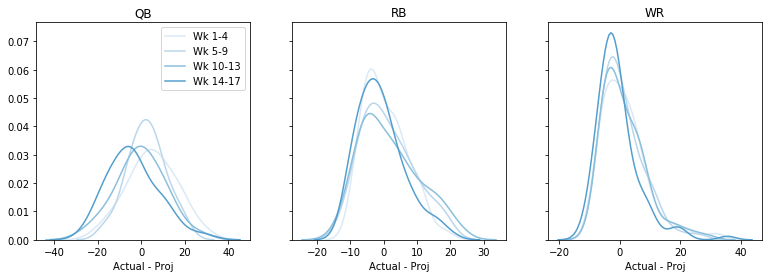
シーズンの後半に過剰予測の傾向があるかもしれませんが、全体としてはここでも何もないと言えるでしょう。 (こうすることで、高い予想と低い予想で誤差が多いか少ないかについての情報が失われることに注意してください。)
次は選手の得点の時系列を見てみたいと思います。 常識的には、ある選手の来週の得点を推測する最良の方法は、彼の過去4-5週間をただ目で追うことです。 (ネタバレ:そうでもないです)
執筆者:スティーブン・モース 2019年8月5日