はじめに
コンパイラは、単なるプログラムです。 プログラムは入力 (ソース コード、別名バイトまたはデータのファイル) を受け取り、一般に、入力とはまったく異なる実行可能なプログラムを生成します。 しかし、いくつかのプラットフォームでは、フォーマットは通常ファイル名拡張子によって示され、バイトがどのように編成され、意味のある解釈をされなければならないかについての規則を指定します。 たとえば、プレーンテキストファイル(Windowsでは.txt)のバイトは、ASCII文字またはUTF-8文字と関連付けられていますが、画像、ビデオ、およびオーディオファイルのバイトは、それ以外の方法で解釈されます。 (Wikipedia)
(https://en.wikipedia.org/wiki/Computer_file#File_contents)
コンパイラは、人間が読めるソースコードを取り込んで解析し、機械語コード (バイナリ) と呼ばれるコンピュータが読めるコードを生成しているのです。 一部のコンパイラーは (マシン コードに直接進むのではなく) アセンブリや別の人間が読める言語に進みます。
人間が読める言語は別名、高級言語です。 ある高級言語から別の高級言語へ移行するコンパイラは、ソース間コンパイラ、トランスコンパイラ、またはトランスパイラと呼ばれます。
(https://en.wikipedia.org/wiki/Source-to-source_compiler)
int main() {
int a = 5;
a = a * 5;
return 0;
}
上記は人間が書いたCプログラムで、疑似コードと呼ばれるより単純でさらに人間が読みやすい言語で次のことを行っています:
program 'main' returns an integer
begin
store the number '5' in the variable 'a'
'a' equals 'a' times '5'
return '0'
end
疑似コードとはコンピュータプログラムまたは他のアルゴリズムの操作原理の非公式な高位記述のことです。 (Wikipedia)
(https://en.wikipedia.org/wiki/Pseudocode)
その C プログラムを、コンパイラが行うように Intel スタイルのアセンブリ コードにコンパイルするのです。 コンピュータは、何が単語、整数、記号になるかを特定し、アルゴリズムに従わなければならないが、我々は常識を働かせればよいのである。
この分析は、理解しやすいように単純化されている。
トークン化
コンピュータがプログラムを解読する前に、まずすべてのシンボルをそれ自身のトークンに分割する必要がある。 トークンとは、ソースファイル内の文字、または文字のグループのことである。 このプロセスはトークン化と呼ばれ、トークナイザーによって行われます。
私たちのオリジナルのソースコードはトークンに分割され、コンピュータのメモリ内に保存されます。
Before:
int main() {
int a = 5;
a = a * 5;
return 0;
}
After:
図は読みやすいように手で整形しています。 実際には、インデントや行分割は行われません。
見てのとおり、与えられたものを非常に忠実に再現しています。 トークンだけを与えれば、ほぼ元のソース コードを再現できるはずです。 トークンは型を保持すべきであり、その型が複数の値を取り得る場合、トークンは対応する値も含むべきです。
トークンそのものはコンパイルするのに十分ではありません。 コンテキストと、これらのトークンを組み合わせたときの意味を知る必要があります。
Parsing
構文解析フェーズでは、トークンを受け取り、抽象構文木 (AST) を作成します。 これは本質的にプログラムの構造を記述し、その名前が示すように非常に抽象的な方法で、プログラムの実行方法を決定するために使用することができます。 これは、中学校の英語で文法木を作成したときに非常に似ています。
パーサーは一般的に、コンパイラーの中で最も複雑な部分となります。 パーサーは複雑で、多くのハードワークと理解を必要とします。 そのため、記述方法に応じてパーサー全体を生成できるプログラムがたくさんあります。
これらの「パーサー作成ツール」は、パーサー ジェネレーターと呼ばれます。 パーサー ジェネレーターは、その言語のコードでパーサーを生成するため、言語に固有です。 Bison (C/C++) は、世界で最も有名なパーサー ジェネレーターの 1 つです。
パーサーは、要するに、トークンをすでに定義されたトークンのパターンにマッチさせようとするのです。 たとえば、assign は EBNF を使用して、次のようなトークンの形式を取ると言うことができます:
EBNF (またはその方言) は文法を定義するためにパーサー ジェネレーターで一般的に使用されています。
assignment = identifier, equals, int | identifier ;
トークンの以下のパターンは代入とみなされます:
a = 5
or
a = a
or
b = 123456789
しかし、以下のパターンはそうであるべきなのにそうではありません:
int a = 5
or
a = a * 5
動作しないものは不可能ではなく、完全に実装できるまでにパーサー内部でのさらなる開発と複雑化が必要です。
パーサーがどのように動作するかにもっと興味がある場合は、次の Wikipedia の記事を読んでください。 https://en.wikipedia.org/wiki/Parsing
Theoretically, after our parser is done parsing, it would generate an abstract syntax tree like the following:
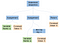
コンピュータサイエンスにおいて、抽象構文木 (AST) または単に構文木は、プログラミング言語で書かれたソースコードの抽象構文構造の木表現である。 (Wikipedia)
(https://en.wikipedia.org/wiki/Abstract_syntax_tree)
AST が高レベルの実行順序と実行するオペレーションをレイアウトしたら、アセンブリ コードの生成を始めるのは非常に簡単です。 これは「ツリーを歩く」と呼ばれ、AST を使用したコード生成のアルゴリズムです。
パース後すぐにコードを生成することは、より複雑なコンパイラーでは一般的ではない。中間、最適化など、最終の AST を持つまでにさらに段階を踏むからである。 コード生成にはさらに多くのテクニックがあります。
https://en.wikipedia.org/wiki/Code_generation_(compiler)
1 つのアセンブラで 1 つまたは複数の異なる CPU アーキテクチャ用のマシン コードを生成できるため、アセンブリにコンパイルするのです。 たとえば、コンパイラが NASM アセンブリを生成した場合、プログラムは Intel x86 アーキテクチャ (16ビット、32ビット、および 64 ビット) と互換性があります。 機械語に直接コンパイルすると、各ターゲットアーキテクチャ用のバックエンドを個別に書く必要があるため、あまり効果的ではありません。 しかし、これはかなり時間がかかり、サードパーティのアセンブラを使用するよりも得策ではありません。
LLVM では、LLVM IR にコンパイルするだけで、あとは LLVM が処理します。 広範なアセンブラ言語までコンパイルできるため、より多くのアーキテクチャにコンパイルできます。 LLVM のことを以前聞いたことがあるなら、なぜそれが大事にされているのか、今ならわかるでしょう。
https://en.wikipedia.org/wiki/LLVM
Statement sequence の分岐に踏み込むとしたら、左から右へ実行するすべてのステートメントを見つけることでしょう。 それらのブランチを左から右へステップダウンし、同等のアセンブリ コードを配置することができます。 ステートメント シーケンスの左端の分岐には、新しい整数型変数 a への最初の代入が含まれています。 代入された値は、定数積分値である 5 を含むリーフです。一番左の枝と同様に、真ん中の枝も代入されています。 これは、aと5の掛け算の2項演算(bin op)をaに代入している。
最後の分岐は単なる戻り値で、プログラムの終了コードを指定するものである。
GNU C コンパイラー (x86-64 GCC 8.1) が最適化なしのソース コードに対して行った処理は以下のとおりです。
コード ジェネレーターは通常、何らかの方法でコードを最適化しようとします。 私たちは技術的に変数 a を使用することはありません。 代入しても、二度と読み込まないのです。 コンパイラはこれを認識し、最終的なアセンブリ生成で変数全体を削除するはずです。 私たちの変数は、最適化でコンパイルしなかったので残ったのです。
Compiler Explorer で、コンパイラーに引数を追加することができます。
-O3は GCC のフラグで、最大限の最適化を意味します。 これを追加してみて、生成されたコードに何が起こるか見てください。
アセンブリコードが生成された後、アセンブラを使用して、マシンコードまでコンパイルすることができます。 マシン コードは、単一のターゲット CPU アーキテクチャに対してのみ機能します。 新しいアーキテクチャをターゲットにするには、コード ジェネレーターで生成可能なアセンブリ ターゲット アーキテクチャを追加する必要があります。
アセンブリをマシン コードにコンパイルするために使用するアセンブラもプログラミング言語で書かれています。 独自のアセンブリ言語で書かれている可能性さえあります。 コンパイルする言語でコンパイラーを書くことをブートストラップと呼びます。
https://en.wikipedia.org/wiki/Bootstrapping_(compilers)
結論
コンパイラーはテキストを取って解析、処理し、コンピューターが読めるようにバイナリに変換します。 これにより、コンピュータのために手動でバイナリを記述する必要がなくなり、さらに、複雑なプログラムを簡単に書くことができるようになります。 トークン化し、解析し、ソース コードを生成しました。 これを読んで、コンピュータとソフトウェアについて理解を深めていただけたと思います。 それでもまだわからないことがあれば、一番下に挙げた学習リソースをチェックしてみてください。 私は、1つの記事を読んだだけで、このすべてを理解したわけではありません。 もし何か質問があれば、コメント欄に書き込む前に、他の人がすでに質問していないかどうか見てください
。