Voraussetzung – Abstandsmaße im Data Mining
Im Data Mining bezieht sich das Ähnlichkeitsmaß auf den Abstand zwischen den Dimensionen, die die Merkmale des Datenobjekts in einem Datensatz darstellen. Wenn dieser Abstand geringer ist, besteht ein hoher Grad an Ähnlichkeit, aber wenn der Abstand groß ist, besteht ein geringer Grad an Ähnlichkeit.
Einige der populären Ähnlichkeitsmaße sind –
- Euklidischer Abstand.
- Manhattan-Distanz.
- Jaccard-Ähnlichkeit.
- Minkowski-Distanz.
- Cosinus-Ähnlichkeit.
Cosinus-Ähnlichkeit ist eine Metrik, die dabei hilft, zu bestimmen, wie ähnlich die Datenobjekte unabhängig von ihrer Größe sind. Wir können die Ähnlichkeit zwischen zwei Sätzen in Python mit Cosinus-Ähnlichkeit messen. Bei der Kosinusähnlichkeit werden die Datenobjekte in einem Datensatz als Vektor behandelt. Die Formel zur Ermittlung der Kosinusähnlichkeit zwischen zwei Vektoren lautet –
Cos(x, y) = x . y / ||x|| * ||y||
wobei,
- x . y = Produkt (Punkt) der Vektoren ‚x‘ und ‚y‘.
- ||x|| und ||y|| = Länge der beiden Vektoren ‚x‘ und ‚y‘.
- ||x|| * ||y|| = Kreuzprodukt der beiden Vektoren ‚x‘ und ‚y‘.
Beispiel :
Betrachten Sie ein Beispiel, um die Ähnlichkeit zwischen zwei Vektoren – ‚x‘ und ‚y‘ – mit Hilfe der Cosinus-Ähnlichkeit zu finden.
Der Vektor ‚x‘ hat die Werte, x = { 3, 2, 0, 5 }
Der Vektor ‚y‘ hat die Werte, y = { 1, 0, 0, 0 }
Die Formel zur Berechnung der Cosinus-Ähnlichkeit lautet : Cos(x, y) = x . y / ||x|| * ||y||
x . y = 3*1 + 2*0 + 0*0 + 5*0 = 3||x|| = √ (3)^2 + (2)^2 + (0)^2 + (5)^2 = 6.16||y|| = √ (1)^2 + (0)^2 + (0)^2 + (0)^2 = 1∴ Cos(x, y) = 3 / (6.16 * 1) = 0.49
Die Unähnlichkeit zwischen den beiden Vektoren ‚x‘ und ‚y‘ ist gegeben durch –
∴ Dis(x, y) = 1 - Cos(x, y) = 1 - 0.49 = 0.51
- Die Kosinusähnlichkeit zwischen zwei Vektoren wird in ‚θ‘ gemessen.
- Wenn θ = 0° ist, überschneiden sich die Vektoren ‚x‘ und ‚y‘ und sind somit ähnlich.
- Wenn θ = 90° ist, sind die Vektoren ‚x‘ und ‚y‘ unähnlich.
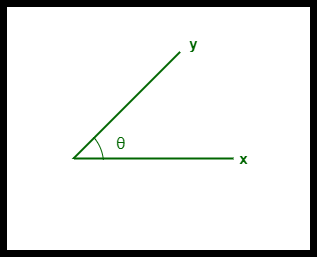
Cosinus-Ähnlichkeit zwischen zwei Vektoren
Vorteile:
- Die Cosinus-Ähnlichkeit ist vorteilhaft, denn selbst wenn die beiden ähnlichen Datenobjekte aufgrund ihrer Größe weit voneinander entfernt sind, kann zwischen ihnen ein kleinerer Winkel bestehen. Je kleiner der Winkel, desto größer die Ähnlichkeit.
- Wenn sie in einem mehrdimensionalen Raum aufgetragen wird, erfasst die Kosinusähnlichkeit die Ausrichtung (den Winkel) der Datenobjekte und nicht die Größe.