Introducción
Todo lo que un compilador es, es sólo un programa. El programa toma una entrada (que es el código fuente – aka un archivo de bytes o datos) y generalmente produce un programa de aspecto completamente diferente, que ahora es ejecutable; a diferencia de la entrada.
En la mayoría de los sistemas operativos modernos, los archivos se organizan en matrices unidimensionales de bytes. El formato de un archivo se define por su contenido ya que un archivo es únicamente un contenedor de datos, aunque, en algunas plataformas el formato se suele indicar por su extensión de nombre de archivo, especificando las reglas de cómo los bytes deben ser organizados e interpretados con sentido. Por ejemplo, los bytes de un archivo de texto plano (
.txten Windows) se asocian con caracteres ASCII o UTF-8, mientras que los bytes de los archivos de imagen, vídeo y audio se interpretan de otra manera. (Wikipedia)
(https://en.wikipedia.org/wiki/Computer_file#File_contents)
El compilador toma el código fuente legible por el ser humano, lo analiza y luego produce un código legible por el ordenador llamado código máquina (binario). Algunos compiladores (en lugar de pasar directamente a código máquina) pasan a ensamblador, o a otro lenguaje legible por el ser humano.
Los lenguajes legibles por el ser humano son conocidos como lenguajes de alto nivel. Un compilador que va de un lenguaje de alto nivel a otro lenguaje de alto nivel diferente se denomina compilador fuente a fuente, transcompilador o transpilador.
(https://en.wikipedia.org/wiki/Source-to-source_compiler)
int main() {
int a = 5;
a = a * 5;
return 0;
}
Lo anterior es un programa en C escrito por un humano que hace lo siguiente en un lenguaje más simple y aún más legible para los humanos llamado pseudocódigo:
program 'main' returns an integer
begin
store the number '5' in the variable 'a'
'a' equals 'a' times '5'
return '0'
end
El pseudocódigo es una descripción informal de alto nivel del principio de funcionamiento de un programa informático u otro algoritmo. (Wikipedia)
(https://en.wikipedia.org/wiki/Pseudocode)
Compilaremos ese programa C en código ensamblador al estilo de Intel como hace un compilador. Aunque un ordenador tiene que ser específico y seguir algoritmos para determinar qué son las palabras, los enteros y los símbolos; nosotros podemos usar simplemente el sentido común. Eso, a su vez, hace que nuestra desambiguación sea mucho más corta que la de un compilador.
Este análisis está simplificado para facilitar la comprensión.
Tokenización
Antes de que un ordenador pueda descifrar un programa, primero debe dividir cada símbolo en su propio token. Un token es la idea de un carácter, o agrupación de caracteres, dentro de un archivo fuente. Este proceso se llama tokenización, y es realizado por un tokenizador.
Nuestro código fuente original sería dividido en tokens y guardado dentro de la memoria de un ordenador. Intentaré transmitir la memoria del ordenador en el siguiente diagrama de la producción del tokenizador.
Antes:
int main() {
int a = 5;
a = a * 5;
return 0;
}
Después:
El diagrama está formateado a mano para facilitar la lectura. En la actualidad, no tendría sangría ni división por líneas.
Como puede ver, crea una forma muy literal de lo que se le dio. Usted debe ser capaz de casi replicar el código fuente original dado sólo los tokens. Los tokens deben retener un tipo, y si el tipo puede ser de más de un valor, el token también debe contener el valor correspondiente.
Los tokens por sí mismos no son suficientes para compilar. Necesitamos conocer el contexto, y lo que esos tokens significan cuando se juntan. Eso nos lleva al análisis sintáctico, donde podemos dar sentido a esos tokens.
Parificación
La fase de análisis sintáctico toma los tokens y produce un árbol sintáctico abstracto, o AST. Esencialmente describe la estructura del programa, y se puede utilizar para determinar cómo se ejecuta, de una manera muy – como el nombre sugiere – abstracta. Es muy similar a cuando se hacían árboles gramaticales en la escuela secundaria de inglés.
El analizador sintáctico generalmente termina siendo la parte más compleja del compilador. Los parsers son complejos y requieren mucho trabajo y comprensión. Por eso hay muchos programas que pueden generar un parser completo dependiendo de cómo lo describas.
Estas ‘herramientas creadoras de parsers’ se llaman generadores de parsers. Los generadores de parser son específicos de los lenguajes, ya que generan el parser en el código de ese lenguaje. Bison (C/C++) es uno de los generadores de parser más conocidos del mundo.
El parser, en definitiva, intenta hacer coincidir tokens con patrones de tokens ya definidos. Por ejemplo, podríamos decir que la asignación toma la siguiente forma de tokens, utilizando EBNF:
EBNF (o un dialecto, del mismo) se utiliza comúnmente en los generadores de parser para definir la gramática.
assignment = identifier, equals, int | identifier ;
Los siguientes patrones de tokens se consideran una asignación:
a = 5
or
a = a
or
b = 123456789
Pero los siguientes patrones no lo son, aunque deberían serlo:
int a = 5
or
a = a * 5
Los que no funcionan no son imposibles, sino que requieren un mayor desarrollo y complejidad dentro del parser antes de que puedan ser implementados por completo.
Lee el siguiente artículo de Wikipedia si te interesa más cómo funcionan los parsers. https://en.wikipedia.org/wiki/Parsing
Teóricamente, después de que nuestro parser termine de analizar, generaría un árbol sintáctico abstracto como el siguiente:
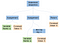
En informática, un árbol sintáctico abstracto (AST), o simplemente árbol sintáctico, es una representación en forma de árbol de la estructura sintáctica abstracta del código fuente escrito en un lenguaje de programación. (Wikipedia)
(https://en.wikipedia.org/wiki/Abstract_syntax_tree)
Después de que el árbol de sintaxis abstracta establece el orden de ejecución de alto nivel, y las operaciones a realizar, se hace bastante sencillo comenzar a generar código ensamblador.
Generación de código
Dado que el AST contiene ramas que definen casi por completo el programa, podemos recorrer esas ramas, generando secuencialmente el ensamblador equivalente. Esto se llama «recorrer el árbol», y es un algoritmo para la generación de código usando un AST.
La generación de código inmediatamente después del análisis sintáctico no es habitual en los compiladores más complejos, ya que pasan por más fases antes de tener un AST final, como la intermedia, la de optimización, etc. Hay más técnicas para la generación de código.
https://en.wikipedia.org/wiki/Code_generation_(compiler)
Compilamos a ensamblador porque un solo ensamblador puede producir código máquina para una, o varias arquitecturas de CPU diferentes. Por ejemplo, si nuestro compilador generara el ensamblador NASM, nuestros programas serían compatibles con las arquitecturas Intel x86 (16 bits, 32 bits y 64 bits). Compilar directamente a código máquina no sería tan eficaz, porque tendríamos que escribir un backend para cada arquitectura de destino de forma independiente. Aunque, sería bastante lento, y con menos ganancia que el uso de un ensamblador de terceros.
Con LLVM, puedes simplemente compilar a LLVM IR y éste se encarga del resto. Compila a una amplia gama de lenguajes ensambladores, y por lo tanto compila a muchas más arquitecturas. Si has oído hablar de LLVM antes, probablemente veas por qué es tan apreciado, ahora.
https://en.wikipedia.org/wiki/LLVM
Si fuéramos a dar un paso en las ramas de la secuencia de declaraciones, encontraríamos todas las declaraciones que se ejecutan de izquierda a derecha. Podemos recorrer esas ramas de izquierda a derecha, colocando el código ensamblador equivalente. Cada vez que terminamos una rama, tenemos que volver a subir y empezar a trabajar en una nueva rama.
La rama más a la izquierda de nuestra secuencia de sentencias contiene la primera asignación a una nueva variable entera, a. El valor asignado es una hoja que contiene el valor integral constante, 5. Similar a la rama más a la izquierda, la rama del medio es una asignación. Asigna la operación binaria (bin op) de multiplicación entre a y 5, a a . Para simplificar hacemos referencia a a dos veces desde el mismo nodo, en lugar de tener dos nodos a.
La rama final es sólo un retorno y es para el código de salida del programa. Le decimos a la computadora que salió normalmente devolviendo cero.
Lo siguiente es la producción del Compilador GNU C (x86-64 GCC 8.1) dado nuestro código fuente sin optimizaciones.
Tenga en cuenta que el compilador no generó los comentarios o espaciamientos.
main:
push rbp
mov rbp, rsp
mov DWORD PTR , 5 ; leftmost branch
mov edx, DWORD PTR ; middle branch
mov eax, edx
sal eax, 2
add eax, edx
mov DWORD PTR , eax
mov eax, 0 ; rightmost branch
pop rbp
ret
Una herramienta impresionante; el Compiler Explorer de Matt Godbolt, le permite escribir código y ver las producciones de ensamblaje del compilador en tiempo real. Prueba nuestro experimento en https://godbolt.org/g/Uo2Z5E.
El generador de código suele intentar optimizar el código de alguna manera. Técnicamente nunca usamos nuestra variable a. Aunque la asignemos, nunca la volvemos a leer. Un compilador debería reconocer esto y, en última instancia, eliminar toda la variable en la producción final de ensamblaje. Nuestra variable se quedó dentro porque no compilamos con optimizaciones.
Puedes añadir argumentos al compilador en el Explorador del Compilador.
-O3es una bandera para GCC que significa máxima optimización. Pruebe a añadirla, y vea lo que ocurre con el código generado.
Después de generar el código ensamblador, podemos compilar el ensamblador a código máquina, utilizando un ensamblador. El código máquina sólo funciona para la única arquitectura de CPU de destino. Para apuntar a una nueva arquitectura, tenemos que añadir esa arquitectura de destino de ensamblaje para que sea producible por nuestro generador de código.
El ensamblador que se utiliza para compilar el ensamblaje a código máquina también está escrito en un lenguaje de programación. Incluso podría estar escrito en su propio lenguaje ensamblador. Escribir un compilador en el lenguaje que compila se llama bootstrapping.
https://en.wikipedia.org/wiki/Bootstrapping_(compilers)
Conclusión
Los compiladores toman el texto, lo analizan y procesan, y luego lo convierten en binario para que su ordenador lo lea. Esto evita que tengas que escribir manualmente el binario para tu ordenador y, además, te permite escribir programas complejos con mayor facilidad.
Asunto de fondo
¡Y eso es todo! Hemos tokenizado, parseado y generado nuestro código fuente. Espero que tengas una mayor comprensión de las computadoras y el software después de haber leído esto. Si todavía estás confundido, sólo mira algunos de los recursos de aprendizaje que he enumerado en la parte inferior. Yo nunca he entendido todo esto después de leer un solo artículo. Si tienes alguna pregunta, mira a ver si alguien ya la ha hecho antes de ir a la sección de comentarios.