Las bases nitrogenadas, componentes importantes de los nucleótidos, son moléculas orgánicas y se llaman así porque contienen carbono y nitrógeno. Son bases porque contienen un grupo amino que tiene el potencial de unir un hidrógeno extra, y así, disminuye la concentración de iones hidrógeno en su entorno, haciéndolo más básico. Cada nucleótido del ADN contiene una de las cuatro bases nitrogenadas posibles: adenina (A), guanina (G), citosina (C) y timina (T). Los nucleótidos del ARN también contienen una de las cuatro bases posibles: adenina, guanina, citosina y uracilo (U) en lugar de timina.
La adenina y la guanina se clasifican como purinas. La estructura primaria de una purina es de dos anillos de carbono-nitrógeno. La citosina, la timina y el uracilo se clasifican como pirimidinas que tienen un solo anillo de carbono-nitrógeno como estructura primaria (Figura 1). Cada uno de estos anillos básicos de carbono-nitrógeno tiene diferentes grupos funcionales unidos a él. En la taquigrafía de la biología molecular, las bases nitrogenadas se conocen simplemente por sus símbolos A, T, G, C y U. El ADN contiene A, T, G y C, mientras que el ARN contiene A, U, G y C.
El azúcar pentosa en el ADN es la desoxirribosa, y en el ARN, el azúcar es la ribosa (Figura 1). La diferencia entre los azúcares es la presencia del grupo hidroxilo en el segundo carbono de la ribosa y del hidrógeno en el segundo carbono de la desoxirribosa. Los átomos de carbono de la molécula de azúcar se numeran como 1′, 2′, 3′, 4′ y 5′ (1′ se lee como «un primo»). El residuo de fosfato se une al grupo hidroxilo del carbono 5′ de un azúcar y al grupo hidroxilo del carbono 3′ del azúcar del siguiente nucleótido, lo que forma un enlace fosfodiéster 5′-3′. El enlace fosfodiéster no se forma por simple reacción de deshidratación como los demás enlaces que conectan los monómeros en las macromoléculas: su formación implica la eliminación de dos grupos fosfato. Un polinucleótido puede tener miles de estos enlaces fosfodiéster.
Estructura de doble hélice del ADN
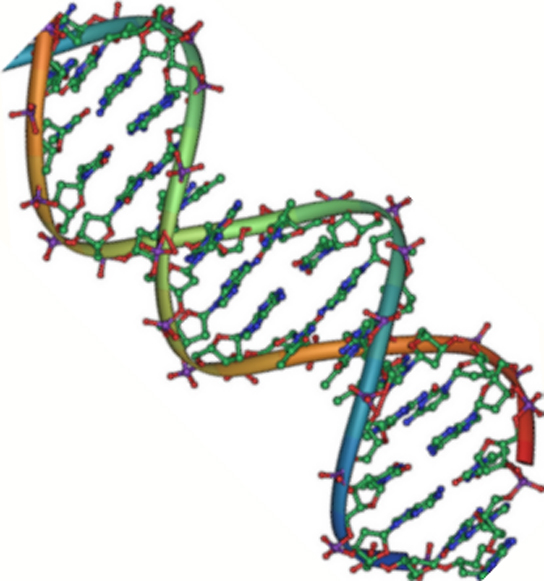
Figura 2. El ADN es una doble hélice antiparalela. La columna vertebral de fosfato (las líneas curvas) está en el exterior, y las bases están en el interior. Cada base interactúa con una base de la cadena opuesta. (crédito: Jerome Walker/Dennis Myts)
El ADN tiene una estructura de doble hélice (Figura 2). El azúcar y el fosfato se encuentran en la parte exterior de la hélice, formando la columna vertebral del ADN. Las bases nitrogenadas se apilan en el interior, como los peldaños de una escalera, por pares; los pares están unidos entre sí por enlaces de hidrógeno. Cada par de bases en la doble hélice está separado del siguiente par de bases por 0,34 nm.
Las dos hebras de la hélice van en direcciones opuestas, lo que significa que el extremo del carbono 5′ de una hebra se enfrentará al extremo del carbono 3′ de su hebra correspondiente. (Esto se conoce como orientación antiparalela y es importante para la replicación del ADN y en muchas interacciones de ácidos nucleicos.)
Sólo se permiten ciertos tipos de emparejamiento de bases. Por ejemplo, una determinada purina sólo puede emparejarse con una determinada pirimidina. Esto significa que A puede emparejarse con T, y G puede emparejarse con C, como se muestra en la Figura 3. Esto se conoce como la regla de complementariedad de bases. En otras palabras, las cadenas de ADN son complementarias entre sí. Si la secuencia de una hebra es AATTGGCC, la hebra complementaria tendría la secuencia TTAACCGG. Durante la replicación del ADN, cada hebra se copia, dando lugar a una doble hélice de ADN hija que contiene una hebra de ADN parental y una hebra recién sintetizada.
Pregunta de práctica
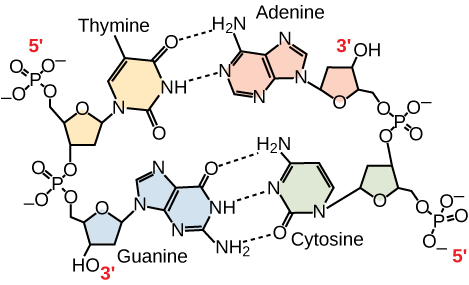
Figura 3. En una molécula de ADN de doble cadena, las dos cadenas discurren antiparalelas entre sí, de modo que una cadena discurre de 5′ a 3′ y la otra de 3′ a 5′. La espina dorsal de fosfato se encuentra en el exterior y las bases en el centro. La adenina forma enlaces de hidrógeno (o pares de bases) con la timina, y la guanina pares de bases con la citosina.
Se produce una mutación, y la citosina se sustituye por adenina. ¿Qué impacto cree que tendrá esto en la estructura del ADN?
ARN
El ácido ribonucleico, o ARN, participa principalmente en el proceso de síntesis de proteínas bajo la dirección del ADN. El ARN suele ser monocatenario y está formado por ribonucleótidos que están unidos por enlaces fosfodiéster. Un ribonucleótido de la cadena de ARN contiene ribosa (el azúcar pentosa), una de las cuatro bases nitrogenadas (A, U, G y C) y el grupo fosfato.
Hay cuatro tipos principales de ARN: el ARN mensajero (ARNm), el ARN ribosómico (ARNr), el ARN de transferencia (ARNt) y el microARN (ARNm). El primero, el ARNm, transporta el mensaje del ADN, que controla todas las actividades celulares de una célula. Si una célula necesita que se sintetice una determinada proteína, el gen de este producto se «enciende» y el ARN mensajero se sintetiza en el núcleo. La secuencia de bases del ARN es complementaria a la secuencia codificadora del ADN del que se ha copiado. Sin embargo, en el ARN, la base T está ausente y en su lugar está presente la U. Si la cadena de ADN tiene una secuencia AATTGCGC, la secuencia del ARN complementario es UUAACGCG. En el citoplasma, el ARNm interactúa con los ribosomas y otra maquinaria celular (Figura 4).
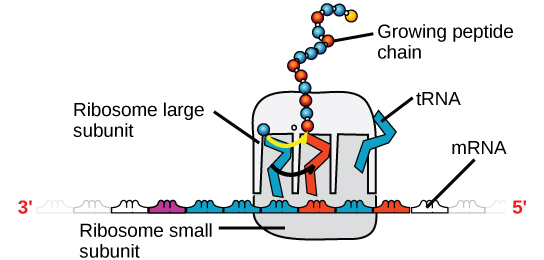
Figura 4. Un ribosoma tiene dos partes: una subunidad grande y una subunidad pequeña. El ARNm se sitúa entre las dos subunidades. Una molécula de ARNt reconoce un codón en el ARNm, se une a él mediante el emparejamiento de bases complementarias y añade el aminoácido correcto a la cadena peptídica en crecimiento.
El ARNm se lee en conjuntos de tres bases conocidos como codones. Cada codón codifica un único aminoácido. De este modo, se lee el ARNm y se fabrica el producto proteico. El ARN ribosómico (ARNr) es uno de los principales componentes de los ribosomas a los que se une el ARNm. El ARNr asegura la correcta alineación del ARNm y los ribosomas; el ARNr del ribosoma también tiene una actividad enzimática (peptidil transferasa) y cataliza la formación de los enlaces peptídicos entre dos aminoácidos alineados. El ARN de transferencia (ARNt) es uno de los más pequeños de los cuatro tipos de ARN, normalmente de 70-90 nucleótidos. Lleva el aminoácido correcto al lugar de la síntesis de proteínas. El emparejamiento de bases entre el ARNt y el ARNm es lo que permite insertar el aminoácido correcto en la cadena polipeptídica. Los microARN son las moléculas de ARN más pequeñas y su función consiste en regular la expresión de los genes interfiriendo en la expresión de determinados mensajes de ARNm.