Úvod
Vše, co je překladač, je jen program. Program přijme vstup (což je zdrojový kód – neboli soubor bajtů nebo dat) a zpravidla vytvoří zcela jinak vypadající program, který je nyní spustitelný; na rozdíl od vstupu.
Ve většině moderních operačních systémů jsou soubory uspořádány do jednorozměrných polí bajtů. Formát souboru je definován jeho obsahem, protože soubor je výhradně kontejnerem pro data, ačkoli na některých platformách je formát obvykle označen příponou názvu souboru, která určuje pravidla, jak musí být bajty uspořádány a smysluplně interpretovány. Například bajty prostého textového souboru (
.txtv systému Windows) jsou spojeny se znaky ASCII nebo UTF-8, zatímco bajty obrazových, video a zvukových souborů jsou interpretovány jinak. (Wikipedie)
(https://en.wikipedia.org/wiki/Computer_file#File_contents)
Kompilátor přebírá váš lidsky čitelný zdrojový kód, analyzuje jej a poté vytváří počítačem čitelný kód nazývaný strojový kód (binární kód). Některé kompilátory (místo přímého přechodu do strojového kódu) přejdou do assembleru nebo jiného lidsky čitelného jazyka.
Lidsky čitelné jazyky jsou AKA jazyky vysoké úrovně. Překladač, který přechází z jednoho vysokoúrovňového jazyka do jiného vysokoúrovňového jazyka, se nazývá překladač ze zdroje do zdroje, překladač nebo transpiler.
(https://en.wikipedia.org/wiki/Source-to-source_compiler)
int main() {
int a = 5;
a = a * 5;
return 0;
}
Výše uvedený program v jazyce C napsaný člověkem provádí následující činnosti v jednodušším, pro člověka ještě čitelnějším jazyce zvaném pseudokód:
program 'main' returns an integer
begin
store the number '5' in the variable 'a'
'a' equals 'a' times '5'
return '0'
end
Pseudokód je neformální popis principu fungování počítačového programu nebo jiného algoritmu na vysoké úrovni. (Wikipedie)
(https://en.wikipedia.org/wiki/Pseudocode)
Tento program v jazyce C zkompilujeme do kódu assembleru ve stylu Intelu stejně jako kompilátor. Ačkoli počítač musí být specifický a řídit se algoritmy, aby určil, co tvoří slova, celá čísla a symboly; my můžeme použít jen zdravý rozum. Díky tomu je zase naše rozklíčování mnohem kratší než u překladače.
Tento rozbor je pro snazší pochopení zjednodušený.
Tokenizace
Předtím, než počítač může program rozklíčovat, musí nejprve každý symbol rozdělit na vlastní token. Token je představa znaku nebo skupiny znaků uvnitř zdrojového souboru. Tento proces se nazývá tokenizace a provádí ho tokenizér.
Náš původní zdrojový kód by byl rozdělen na tokeny a uložen uvnitř paměti počítače. Paměť počítače se pokusím zprostředkovat v následujícím diagramu výroby tokenizéru.
Před:
int main() {
int a = 5;
a = a * 5;
return 0;
}
Po:
Diagram je kvůli čitelnosti ručně formátován. Ve skutečnosti by nebyl odsazen ani rozdělen na řádky.
Jak vidíte, vytváří velmi doslovnou podobu toho, co mu bylo zadáno. Měli byste být schopni téměř zkopírovat původní zdrojový kód, pokud máte k dispozici pouze tokeny. Tokeny by měly zachovávat typ, a pokud může mít typ více než jednu hodnotu, měl by token obsahovat i odpovídající hodnotu.
Samotné tokeny ke kompilaci nestačí. Potřebujeme znát kontext a vědět, co tyto tokeny znamenají, když se dají dohromady. To nás přivádí k parsování, kde můžeme těmto tokenům dát smysl.
Parsování
Fáze parsování bere tokeny a vytváří abstraktní syntaktický strom neboli AST. Ten v podstatě popisuje strukturu programu a lze jej použít pro určení způsobu jeho provádění, a to velmi – jak název napovídá – abstraktním způsobem. Je to velmi podobné, jako když jste na střední škole v angličtině vytvářeli gramatické stromy.
Parser je nakonec obecně nejsložitější částí překladače. Parsery jsou složité a vyžadují spoustu práce a porozumění. Proto existuje spousta programů, které dokáží vygenerovat celý parser podle toho, jak ho popíšete.
Těmto „nástrojům pro tvorbu parserů“ se říká generátory parserů. Generátory parserů jsou specifické pro jednotlivé jazyky, protože generují parser v kódu daného jazyka. Jedním z nejznámějších generátorů parserů je Bison (C/C++).
Parser se zkrátka snaží přiřadit tokeny k již definovaným vzorům tokenů. Můžeme například říci, že přiřazení přebírá následující tvar tokenů, přičemž se používá EBNF:
EBNF (nebo jeho dialekt) se v generátorech parserů běžně používá k definici gramatiky.
assignment = identifier, equals, int | identifier ;
Následující vzory tokenů se považují za přiřazení:
a = 5
or
a = a
or
b = 123456789
Následující vzory však ne, i když by měly být:
int a = 5
or
a = a * 5
Ty, které nefungují, nejsou nemožné, ale spíše vyžadují další vývoj a složitost uvnitř parseru, než je bude možné zcela implementovat.
Přečtěte si následující článek na Wikipedii, pokud vás zajímá více o tom, jak parsery fungují. https://en.wikipedia.org/wiki/Parsing
Teoreticky by po dokončení parsování náš parser vygeneroval abstraktní syntaktický strom, jako je následující:
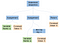
Abstraktní syntaktický strom (AST) nebo jen syntaktický strom je v informatice stromová reprezentace abstraktní syntaktické struktury zdrojového kódu zapsaného v programovacím jazyce. (Wikipedie)
(https://en.wikipedia.org/wiki/Abstract_syntax_tree)
Poté, co abstraktní syntaktický strom stanoví vysokoúrovňové pořadí provádění a operace, které je třeba provést, je poměrně jednoduché začít generovat kód assembleru.
Generování kódu
Protože AST obsahuje větve, které téměř zcela definují program, můžeme těmito větvemi postupně procházet a postupně generovat ekvivalentní assembler. Tomuto postupu se říká „procházení stromem“ a je to algoritmus pro generování kódu pomocí AST.
Generování kódu ihned po parsování není u složitějších překladačů běžné, protože než mají konečný AST, procházejí více fázemi, jako je meziprodukt, optimalizace atd. Technik generování kódu je více.
https://en.wikipedia.org/wiki/Code_generation_(compiler)
Kompilujeme do assembleru, protože jeden assembler může vytvořit strojový kód pro jednu, nebo několik různých architektur CPU. Pokud by například náš kompilátor generoval assembler NASM, byly by naše programy kompatibilní s architekturami Intel x86 (16bitová, 32bitová a 64bitová). Kompilace přímo do strojového kódu by nebyla tak efektivní, protože bychom museli napsat backend pro každou cílovou architekturu zvlášť. I když by to bylo dost časově náročné a s menším ziskem než použití assembleru třetí strany.
S LLVM stačí zkompilovat do LLVM IR a ten se postará o zbytek. Zkompiluje se až na širokou škálu assemblerových jazyků, a tak se zkompiluje na mnohem více architektur. Pokud jste o LLVM už někdy slyšeli, asi už chápete, proč je tak ceněný.
https://en.wikipedia.org/wiki/LLVM
Pokud bychom vstoupili do větví posloupnosti příkazů, našli bychom všechny příkazy, které se spouštějí zleva doprava. Tyto větve můžeme rozkročit zleva doprava a umístit do nich ekvivalentní kód assembleru. Pokaždé, když dokončíme větev, musíme se vrátit nahoru a začít pracovat na nové větvi.
Nejlevější větev naší posloupnosti příkazů obsahuje první přiřazení nové celočíselné proměnné a. Přiřazenou hodnotou je list, který obsahuje konstantní integrální hodnotu, 5. Podobně jako nejlevější větev je i prostřední větev přiřazením. Přiřazuje binární operaci (bin op) násobení mezi a a 5, do a . Pro zjednodušení jen dvakrát odkazujeme na a ze stejného uzlu, místo abychom měli dva uzly a.
Koncová větev je jen návratová a je určena pro výstupní kód programu. Vrácením nuly sdělíme počítači, že normálně ukončil program.
Následující ukázka je produkce překladače GNU C Compiler (x86-64 GCC 8.1) vzhledem k našemu zdrojovému kódu bez použití optimalizací.
Mějte na paměti, že překladač negeneroval komentáře ani mezery.
main:
push rbp
mov rbp, rsp
mov DWORD PTR , 5 ; leftmost branch
mov edx, DWORD PTR ; middle branch
mov eax, edx
sal eax, 2
add eax, edx
mov DWORD PTR , eax
mov eax, 0 ; rightmost branch
pop rbp
ret
Úžasný nástroj; Compiler Explorer od Matta Godbolta, umožňuje psát kód a vidět produkci kompilátoru v assembleru v reálném čase. Vyzkoušejte náš experiment na adrese https://godbolt.org/g/Uo2Z5E.
Generátor kódu se obvykle pokouší kód nějakým způsobem optimalizovat. Technicky nikdy nepoužíváme naši proměnnou a. I když do ní přiřazujeme, už ji nikdy nepřečteme. Překladač by to měl rozpoznat a ve finální produkci assembleru nakonec celou proměnnou odstranit. Naše proměnná tam zůstala, protože jsme ji nezkompilovali s optimalizací.
V Průzkumníku překladače můžete překladači přidat argumenty.
-O3Je to příznak pro GCC, který znamená maximální optimalizaci. Zkuste jej přidat a uvidíte, co se stane s vygenerovaným kódem.
Po vygenerování kódu assembleru můžeme assembler zkompilovat až do strojového kódu, a to pomocí assembleru. Strojový kód funguje pouze pro jedinou cílovou architekturu procesoru. Chceme-li cílit na novou architekturu, musíme přidat tuto cílovou architekturu assembleru, aby byla produkovatelná naším generátorem kódu.
Assembler, který použijete ke kompilaci assembleru dolů na strojový kód, je také napsán v programovacím jazyce. Mohl by být dokonce napsán ve vlastním jazyce assembleru. Napsání kompilátoru v jazyce, který kompiluje, se nazývá bootstrapping.
https://en.wikipedia.org/wiki/Bootstrapping_(compilers)
Závěr
Kompilátory berou text, analyzují ho a zpracovávají a pak ho převedou do binární podoby, kterou počítač přečte. Díky tomu nemusíte binární kód pro počítač psát ručně a navíc můžete snadněji psát složité programy.
Zadní text
A to je vše! Tokenizovali jsme, analyzovali a vygenerovali náš zdrojový kód. Doufám, že po přečtení tohoto článku lépe porozumíte počítačům a softwaru. Pokud jste stále zmateni, podívejte se na některé z výukových zdrojů, které jsem uvedl dole. Nikdy jsem to všechno nezvládl po přečtení jednoho článku. Pokud máte nějaké otázky, podívejte se, jestli se na ně už nezeptal někdo jiný, než se pustíte do sekce komentářů.