Je neděle ráno, soupisky se chystají zamknout na brzké odpoledne a vy se rozhodujete mezi dvěma WR deváté úrovně pro tento slot WR3. Je 3. týden, oba jsou zoufalými výběry z waiver listu, které jste neměli čas prozkoumat, a upřímně řečeno, dnes máte jiné ryby na smažení. A hle: prognóza ESPN pro jednoho je 7, pro druhého 8. Vyberete si toho 8 a říkáte si: „To prognózované skóre přece musí něco znamenat, ne?“
tl;dr To prognózované skóre v podstatě nic neznamená a my vám to můžeme ukázat pomocí (nedokumentovaného) rozhraní ESPN Fantasy API a trochu Pythonu.
Malé pozadí
Mike Clay je muž za oponou prognóz ESPN pro fantasy. Přísahá, že má „zdlouhavý proces“, který zahrnuje „statistické výpočty a subjektivní vstupy“. Chci říct, že on za to dostává plat a já píšu blogové příspěvky, takže nemůžu příliš nenávidět, ať už je ten záhadný statistický proces jakýkoli.
Bez ohledu na to, že existuje mnoho analýz porovnávajících projekce ESPN s jinými weby v celém spektru od intenzivních příspěvků na redditu až po příspěvky na blogu NYT.
Shoda panuje v tom, že projekce ESPN nejsou příliš dobré, a to na základě ukazatelů jako „přesnost“ a R-squared, které se snaží kvantifikovat celkovou chybu pomocí jediné souhrnné statistiky.
Ale také jsem si všiml, že je velmi málo informací o tom, jak si to člověk může sám ověřit. Tato stránka z footballanalytics.net odkazuje na několik skvělých skriptů R, ale nevšiml jsem si, že by některý zachycoval projekce ESPN konkrétně (i když se mohu mýlit).
Zkoumání …
ESPN v současné době udržuje jednu historickou sezónu projekcí, takže se chopíme roku 2018 a uvidíme, co najdeme.
Využijeme rozhraní API ESPN Fantasy, o jehož používání píšu zde.
Zjednodušeně řečeno, pošleme ESPN stejný požadavek GET, jaký její web posílá svým vlastním serverům, když přejdeme na stránku historické ligy. Jak jsou tyto požadavky tvořeny, můžete odposlouchávat pomocí nástrojů Safari pro webové vývojáře nebo proxy služby, jako je Charles nebo Fiddler.
Než napíšeme kód pro získání všech potřebných dat, prozkoumáme malý kousek:
import requestsswid = 'YOUR_SWID'espn_s2 = 'LONG_ESPN_S2_KEY'league_id = 123456season = 2018week = 5url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn})d = r.json()Toto je trochu podrobněji vysvětleno v mém předchozím příspěvku, ale jde o to, že posíláme požadavek na API ESPN pro konkrétní zobrazení konkrétní ligy, týdne a sezóny, které nám poskytne kompletní informace o zápasech/boxscore včetně předpokládaných bodů. Soubory cookie jsou potřeba pouze pro soukromé ligy a opět se jimi zabývám zde.
Pokud projdete strukturu JSON, zjistíte, že každý fantasy tým má roster svých hráčů a každý hráč má výpis svých stats.
(Opět platí, že pěkný způsob, jak se v této struktuře orientovat, je pomocí nástrojů Web Developer v prohlížeči Safari: přejděte na stránku, která vás zajímá v klubovně vaší fantasy ligy, otevřete nástroje Web Developer, přejděte do části Zdroje a pak v části XHR vyhledejte objekt s ID vaší ligy. To bude surový text JSON … v malé oblasti záhlaví změňte „Response“ na „JSON“, abyste získali uživatelsky přívětivější rozhraní ve stylu průzkumníka).
Získání všech projekcí 2018
Je to trochu skryté, ale v této dílčí struktuře jsou předpokládané a skutečné fantasy body pro každého hráče na každé soupisce.
Všiml jsem si, že seznam stats pro konkrétního hráče má 5-6 položek, z nichž jedna je vždy předpokládané skóre a druhá skutečné. Předpokládané skóre je identifikováno pomocí statSourceId=1, skutečné pomocí statSourceId=0.
Použijeme toto pozorování k sestavení sady smyček pro odesílání požadavků GET pro každý týden a následné extrahování každého předpokládaného/skutečného skóre pro každého hráče na každé soupisce.
import requestsimport pandas as pdleague_id = 123456season = 2018slotcodes = { 0 : 'QB', 2 : 'RB', 4 : 'WR', 6 : 'TE', 16: 'Def', 17: 'K', 20: 'Bench', 21: 'IR', 23: 'Flex'}url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'data = print('Week ', end='')for week in range(1, 17): print(week, end=' ') r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn}) d = r.json() for tm in d: tmid = tm for p in tm: name = p slot = p pos = slotcodes # injured status (need try/exc bc of D/ST) inj = 'NA' try: inj = p except: pass # projected/actual points proj, act = None, None for stat in p: if stat != week: continue if stat == 0: act = stat elif stat == 1: proj = stat data.append()print('\nComplete.')data = pd.DataFrame(data, columns=)Week 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Complete.Dostaneme něco takového:
data.head() Week Team Player Slot Pos Status Proj Actual0 1 1 Leonard Fournette 2 RB QUESTIONABLE 13.891825 5.01 1 1 Christian McCaffrey 2 RB ACTIVE 11.067053 7.02 1 1 Derrick Henry 20 Bench ACTIVE 10.271163 2.03 1 1 Josh Gordon 4 WR OUT 6.153141 7.04 1 1 Philip Rivers 0 QB QUESTIONABLE 26.212294 42.0Ano, ano, jedná se pouze o hráče na soupiskách, takže nezachycujeme žádné volné hráče … ale mělo by nám to alespoň prozatím poskytnout představu o přesnosti projekcí ESPN.
Postavme si graf „Proj“ proti „Actual“ pro několik různých pozic a držme si palce …
fig, axs = plt.subplots(1,3, sharey=True, figsize=(12, 4))for i, pos in enumerate(): (data .query('Pos == @pos') .pipe((axs.scatter, 'data'), x='Proj', y='Actual', s=50, c='b', alpha=0.5) ) axs.plot(, , 'k--') axs.set(xlim=, ylim=, xlabel='Projected', title=pos)axs.set_ylabel('Actual')plt.tight_layout()plt.show()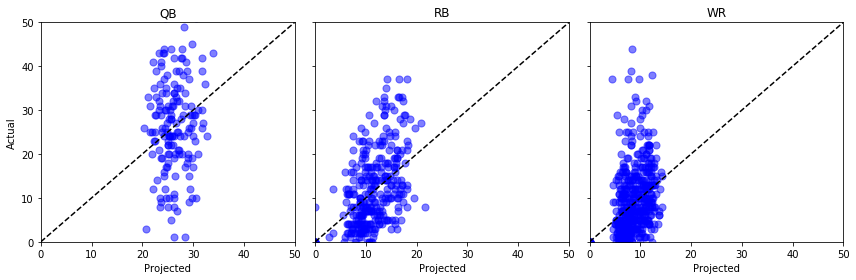
Hm, nic moc. Mohli bychom tu udělat nějaké statistické testy, ale mému necvičenému oku se zdá, že ty předpokládané body mohou stejně dobře vycházet z rovnoměrného rozdělení.
Možná je to v určitých týdnech lepší? Třeba v pozdějších částech sezony? Vyneseme do grafu celkovou chybu podle týdnů a pozic. Tento kód trochu hapruje :(, ale jsem připraven s ním žít:
fig, axs = plt.subplots(1,3, sharey=True, figsize=(13,4))data = data - datadata = pd.cut(data, bins=4, labels=)cols = sns.color_palette('Blues')# dummy plots for a legendfor k,cat in enumerate(): axs.plot(,, c=cols, label='Wk ' + cat)axs.legend()for i, pos in enumerate(): for cat in range(4): t = data.query('Pos == @pos & Cat == @cat') sns.kdeplot(t, color=cols, ax=axs, legend=False) axs.set(xlabel='Actual - Proj', title=pos) plt.show()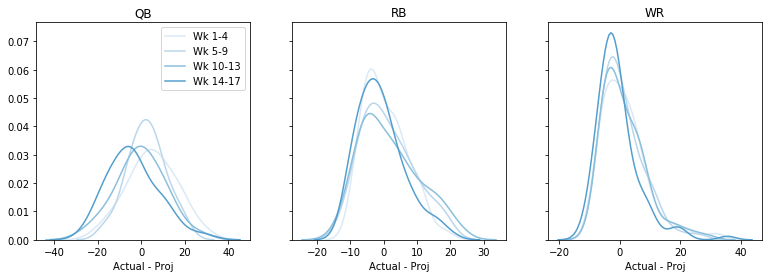
Možná je tendence k nadprojekci v pozdějších fázích sezóny, ale celkově bych ani tady nic neřekl. (Všimněte si, že tím jsme přišli o informaci, zda je chyba větší nebo menší u vysokých a nízkých projekcí.)
Rád bych se dále podíval na časovou řadu bodů hráčů. Zdravý rozum říká, že nejlepší způsob, jak odhadnout, jaký bude mít hráč příští týden bodový zisk, je prostě se podívat na jeho poslední 4-5 týdnů… Jak spolehlivá je to strategie?“
V tomto příspěvku zkusím zkontrolovat projekce ESPN na úrovni soupisky – možná jednotlivé projekce nejsou působivé, ale v souhrnu začnou zázračně pomáhat? (Spoiler: ani ne.)
Napsal Steven Morse 5. srpna 2019.