Einführung
Alles, was ein Compiler ist, ist nur ein Programm. Das Programm nimmt eine Eingabe (den Quellcode – auch bekannt als eine Datei mit Bytes oder Daten) und erzeugt im Allgemeinen ein völlig anders aussehendes Programm, das nun ausführbar ist; im Gegensatz zur Eingabe.
Auf den meisten modernen Betriebssystemen sind Dateien in eindimensionalen Arrays von Bytes organisiert. Das Format einer Datei wird durch ihren Inhalt definiert, da eine Datei nur ein Container für Daten ist, obwohl auf einigen Plattformen das Format normalerweise durch die Dateinamenerweiterung angegeben wird, die die Regeln dafür angibt, wie die Bytes organisiert und sinnvoll interpretiert werden müssen. So werden beispielsweise die Bytes einer reinen Textdatei (
.txtin Windows) entweder mit ASCII- oder UTF-8-Zeichen assoziiert, während die Bytes von Bild-, Video- und Audiodateien anders interpretiert werden. (Wikipedia)
(https://en.wikipedia.org/wiki/Computer_file#File_contents)
Der Compiler nimmt Ihren menschenlesbaren Quellcode, analysiert ihn und erzeugt dann einen computerlesbaren Code, der Maschinencode (Binärcode) genannt wird. Einige Compiler wandeln (statt direkt in Maschinencode) in Assembler oder eine andere menschenlesbare Sprache um.
Menschenlesbare Sprachen werden auch als Hochsprachen bezeichnet. Ein Compiler, der von einer Hochsprache zu einer anderen Hochsprache übergeht, wird als Source-to-Source-Compiler, Transcompiler oder Transpiler bezeichnet.
(https://en.wikipedia.org/wiki/Source-to-source_compiler)
int main() {
int a = 5;
a = a * 5;
return 0;
}
Das obige Programm ist ein von einem Menschen geschriebenes C-Programm, das Folgendes in einer einfacheren, noch besser lesbaren Sprache namens Pseudocode tut:
program 'main' returns an integer
begin
store the number '5' in the variable 'a'
'a' equals 'a' times '5'
return '0'
end
Pseudocode ist eine informelle Beschreibung des Funktionsprinzips eines Computerprogramms oder eines anderen Algorithmus auf hoher Ebene. (Wikipedia)
(https://en.wikipedia.org/wiki/Pseudocode)
Wir werden dieses C-Programm in Assemblercode im Intel-Stil kompilieren, genau wie es ein Compiler tut. Obwohl ein Computer sehr genau sein und Algorithmen folgen muss, um zu bestimmen, was Wörter, ganze Zahlen und Symbole sind, können wir einfach unseren gesunden Menschenverstand benutzen. Das wiederum macht unsere Disambiguierung viel kürzer als bei einem Compiler.
Diese Analyse ist zum besseren Verständnis vereinfacht.
Tokenization
Bevor ein Computer ein Programm entschlüsseln kann, muss er zunächst jedes Symbol in ein eigenes Token aufteilen. Ein Token ist die Vorstellung eines Zeichens oder einer Gruppierung von Zeichen in einer Quelldatei. Dieser Vorgang wird Tokenisierung genannt und von einem Tokenizer durchgeführt.
Unser ursprünglicher Quellcode würde in Token aufgeteilt und im Speicher eines Computers aufbewahrt. Ich werde versuchen, den Speicher des Computers in dem folgenden Diagramm der Tokenizer-Produktion darzustellen.
Vor:
int main() {
int a = 5;
a = a * 5;
return 0;
}
Nach:
Das Diagramm ist aus Gründen der Lesbarkeit handformatiert. In Wirklichkeit würde es nicht eingerückt oder nach Zeilen geteilt werden.
Wie Sie sehen können, wird eine sehr wörtliche Form dessen erstellt, was ihm gegeben wurde. Sie sollten in der Lage sein, den ursprünglichen Quellcode nahezu zu reproduzieren, wenn Sie nur die Token verwenden. Token sollten einen Typ enthalten, und wenn der Typ mehr als einen Wert haben kann, sollte das Token auch den entsprechenden Wert enthalten.
Die Token selbst reichen zum Kompilieren nicht aus. Wir müssen den Kontext kennen und wissen, was diese Token zusammengenommen bedeuten. Das bringt uns zum Parsing, wo wir den Token einen Sinn geben können.
Parsing
In der Parsing-Phase wird aus den Token ein abstrakter Syntaxbaum, oder AST, erstellt. Er beschreibt im Wesentlichen die Struktur des Programms und kann dazu verwendet werden, um zu bestimmen, wie es ausgeführt wird, und zwar – wie der Name schon sagt – auf sehr abstrakte Weise. Es ist sehr ähnlich wie bei der Erstellung von Grammatikbäumen im Englischunterricht der Mittelstufe.
Der Parser ist im Allgemeinen der komplexeste Teil des Compilers. Parser sind komplex und erfordern viel harte Arbeit und Verständnis. Deshalb gibt es viele Programme, die einen ganzen Parser generieren können, je nachdem, wie man ihn beschreibt.
Diese „Parser-Erstellungs-Tools“ werden Parser-Generatoren genannt. Parsergeneratoren sind sprachspezifisch, da sie den Parser im Code der jeweiligen Sprache erzeugen. Bison (C/C++) ist einer der bekanntesten Parser-Generatoren der Welt.
Der Parser versucht, kurz gesagt, Token mit bereits definierten Mustern von Token zu vergleichen. Wir könnten zum Beispiel sagen, dass die Zuweisung die folgende Form von Token annimmt, wobei EBNF verwendet wird:
EBNF (oder ein Dialekt davon) wird üblicherweise in Parsergeneratoren verwendet, um die Grammatik zu definieren.
assignment = identifier, equals, int | identifier ;
Die folgenden Muster von Token werden als Zuweisung betrachtet:
a = 5
or
a = a
or
b = 123456789
Aber die folgenden Muster sind es nicht, obwohl sie es sein sollten:
int a = 5
or
a = a * 5
Diejenigen, die nicht funktionieren, sind nicht unmöglich, sondern erfordern eher weitere Entwicklung und Komplexität innerhalb des Parsers, bevor sie vollständig implementiert werden können.
Lesen Sie den folgenden Wikipedia-Artikel, wenn Sie mehr über die Funktionsweise von Parsern wissen möchten. https://en.wikipedia.org/wiki/Parsing
Theoretisch würde unser Parser, nachdem er mit dem Parsen fertig ist, einen abstrakten Syntaxbaum wie den folgenden erzeugen:
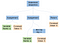
In der Informatik ist ein abstrakter Syntaxbaum (AST), oder einfach Syntaxbaum, eine Baumdarstellung der abstrakten syntaktischen Struktur von Quellcode, der in einer Programmiersprache geschrieben wurde. (Wikipedia)
(https://en.wikipedia.org/wiki/Abstract_syntax_tree)
Nachdem der abstrakte Syntaxbaum die High-Level-Ausführungsreihenfolge und die auszuführenden Operationen festlegt, ist es ziemlich einfach, mit der Generierung von Assemblercode zu beginnen.
Codegenerierung
Da der AST Verzweigungen enthält, die das Programm fast vollständig definieren, können wir diese Verzweigungen schrittweise durchlaufen und nacheinander den entsprechenden Assembler erzeugen. Dies wird „Walking the Tree“ genannt und ist ein Algorithmus für die Codegenerierung unter Verwendung eines AST.
Die Codegenerierung unmittelbar nach dem Parsen ist bei komplexeren Compilern nicht üblich, da sie mehrere Phasen durchlaufen, bevor sie einen endgültigen AST erhalten, wie z.B. Zwischenschritte, Optimierung usw. Es gibt weitere Techniken für die Codegenerierung.
https://en.wikipedia.org/wiki/Code_generation_(compiler)
Wir kompilieren zu Assembler, weil ein einziger Assembler Maschinencode für eine oder mehrere verschiedene CPU-Architekturen erzeugen kann. Wenn unser Compiler beispielsweise NASM-Assembler erzeugt, sind unsere Programme mit Intel x86-Architekturen (16-Bit, 32-Bit und 64-Bit) kompatibel. Eine direkte Kompilierung in Maschinencode wäre nicht so effektiv, da wir für jede Zielarchitektur ein eigenes Backend schreiben müssten. Allerdings wäre das ziemlich zeitaufwendig und hätte weniger Vorteile als die Verwendung eines Assemblers eines Drittanbieters.
Mit LLVM kann man einfach nach LLVM IR kompilieren und es erledigt den Rest. Es kompiliert auf eine breite Palette von Assemblersprachen und somit auf viel mehr Architekturen. Wenn Sie schon einmal von LLVM gehört haben, wissen Sie jetzt wahrscheinlich, warum es so geschätzt wird.
https://en.wikipedia.org/wiki/LLVM
Wenn wir in die Verzweigungen der Anweisungssequenz einsteigen würden, würden wir alle Anweisungen finden, die von links nach rechts ausgeführt werden. Wir können diese Verzweigungen von links nach rechts abwärts gehen und den entsprechenden Assemblercode platzieren. Jedes Mal, wenn wir eine Verzweigung beenden, müssen wir wieder nach oben gehen und mit der Arbeit an einer neuen Verzweigung beginnen.
Der ganz linke Zweig unserer Anweisungssequenz enthält die erste Zuweisung an eine neue Ganzzahlvariable, a. Der zugewiesene Wert ist ein Blatt, das den konstanten ganzzahligen Wert 5 enthält. Ähnlich wie der ganz linke Zweig ist auch der mittlere Zweig eine Zuweisung. Er weist die binäre Operation (bin op) der Multiplikation zwischen a und 5 a zu. Der Einfachheit halber referenzieren wir a zweimal von demselben Knoten aus, anstatt zwei a-Knoten zu haben.
Der letzte Zweig ist nur ein Return und dient dem Exit-Code des Programms. Wir teilen dem Computer mit, dass das Programm normal beendet wurde, indem wir Null zurückgeben.
Das Folgende ist die Produktion des GNU C Compilers (x86-64 GCC 8.1) für unseren Quellcode ohne Optimierungen.
Denken Sie daran, dass der Compiler die Kommentare oder Abstände nicht generiert hat.
main:
push rbp
mov rbp, rsp
mov DWORD PTR , 5 ; leftmost branch
mov edx, DWORD PTR ; middle branch
mov eax, edx
sal eax, 2
add eax, edx
mov DWORD PTR , eax
mov eax, 0 ; rightmost branch
pop rbp
ret
Ein großartiges Tool, der Compiler Explorer von Matt Godbolt, ermöglicht es Ihnen, Code zu schreiben und die Assembler-Produktionen des Compilers in Echtzeit zu sehen. Probieren Sie unser Experiment unter https://godbolt.org/g/Uo2Z5E.
Der Codegenerator versucht normalerweise, den Code in irgendeiner Weise zu optimieren. Wir verwenden unsere Variable a technisch gesehen nie. Auch wenn wir sie zuweisen, lesen wir sie nie wieder aus. Ein Compiler sollte dies erkennen und schließlich die gesamte Variable in der endgültigen Assemblerproduktion entfernen. Unsere Variable ist geblieben, weil wir nicht mit Optimierungen kompiliert haben.
Sie können dem Compiler im Compiler-Explorer Argumente hinzufügen.
-O3ist ein Flag für GCC, das maximale Optimierung bedeutet. Versuchen Sie, es hinzuzufügen, und sehen Sie, was mit dem generierten Code passiert.
Nachdem der Assembler-Code generiert wurde, können wir den Assembler mit einem Assembler in Maschinencode kompilieren. Der Maschinencode funktioniert nur für eine einzige Ziel-CPU-Architektur. Um eine neue Architektur anzusteuern, müssen wir diese Assembler-Zielarchitektur hinzufügen, damit sie von unserem Codegenerator erzeugt werden kann.
Der Assembler, den Sie verwenden, um den Assembler in Maschinencode zu kompilieren, ist ebenfalls in einer Programmiersprache geschrieben. Er könnte sogar in seiner eigenen Assemblersprache geschrieben sein. Einen Compiler in der Sprache zu schreiben, die er kompiliert, nennt man Bootstrapping.
https://en.wikipedia.org/wiki/Bootstrapping_(compilers)
Schlussfolgerung
Compiler nehmen Text, analysieren und verarbeiten ihn und wandeln ihn dann in Binärcode um, den Ihr Computer lesen kann. Das erspart Ihnen das manuelle Schreiben von Binärdateien für Ihren Computer und ermöglicht es Ihnen außerdem, komplexe Programme einfacher zu schreiben.
Hintergrundinformationen
Und das war’s! Wir haben unseren Quellcode tokenisiert, geparst und generiert. Ich hoffe, Sie haben nach dieser Lektüre ein besseres Verständnis für Computer und Software. Wenn Sie immer noch verwirrt sind, schauen Sie sich einfach einige der Lernressourcen an, die ich am Ende des Artikels aufgelistet habe. Ich habe das alles nie nach dem Lesen eines Artikels verstanden. Wenn Sie Fragen haben, sehen Sie nach, ob jemand anderes sie bereits gestellt hat, bevor Sie sich in den Kommentarbereich begeben.