Es ist Sonntagmorgen, die Roster sind dabei, für den frühen Nachmittag zu sperren, und du entscheidest dich zwischen zwei WRs der neunten Reihe für den WR3-Slot. Es ist Woche 3, beide sind Waiver Wire Desperation Picks, für die du noch keine Zeit hattest, dich zu informieren, und ehrlich gesagt, hast du heute Wichtigeres zu tun. Siehe da: Der ESPN Projected Score für den einen ist 7, für den anderen 8. Du nimmst die 8 und denkst: „Dieser Projected Score muss doch etwas bedeuten, oder?“
tl;dr Der Projected Score bedeutet im Grunde gar nichts, und wir können es zeigen, indem wir die (undokumentierte) ESPN Fantasy API und ein wenig Python verwenden.
Ein wenig Hintergrund
Mike Clay ist der Mann hinter dem Vorhang der ESPN Fantasy Projections. Er schwört, dass er einen „langwierigen Prozess“ hat, der „statistische Berechnungen und subjektive Eingaben“ beinhaltet. Ich meine, er wird bezahlt, und ich schreibe Blogposts, also kann ich nicht allzu viel über diesen mysteriösen statistischen Prozess sagen.
Ungeachtet dessen gibt es viele Analysen, die ESPNs Projektionen mit denen anderer Seiten vergleichen, und zwar auf der ganzen Bandbreite von intensiven reddit-Posts bis zu NYT-Blogposts.
Der Konsens scheint zu sein, dass ESPNs Prognosen nicht sehr gut sind, basierend auf Metriken wie „Genauigkeit“ und R-Quadrat, die versuchen, den Gesamtfehler mit einer einzigen zusammenfassenden Statistik zu quantifizieren.
Aber ich stelle auch fest, dass es sehr wenig Informationen darüber gibt, wie man dies selbst überprüfen kann. Diese Seite von footballanalytics.net verlinkt auf einige großartige R-Skripte, aber ich habe nicht gesehen, dass irgendwelche ESPN-Projektionen speziell erfasst werden (obwohl ich mich irren könnte).
Untersuchung …
ESPN pflegt derzeit eine historische Saison von Projektionen, also nehmen wir 2018 und sehen, was wir finden.
Wir werden die ESPN Fantasy API verwenden, deren Verwendung ich hier beschreibe.
Wir werden, kurz gesagt, ESPN die gleiche GET-Anfrage senden, die ihre Website an ihre eigenen Server sendet, wenn wir zu einer historischen Ligaseite navigieren. Mit den Webentwickler-Werkzeugen von Safari oder einem Proxy-Dienst wie Charles oder Fiddler können Sie abhören, wie diese Anfragen gebildet werden.
Bevor wir Code schreiben, um alle benötigten Daten abzurufen, wollen wir einen kleinen Teil davon erforschen:
import requestsswid = 'YOUR_SWID'espn_s2 = 'LONG_ESPN_S2_KEY'league_id = 123456season = 2018week = 5url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn})d = r.json()Dies wird in meinem vorherigen Beitrag etwas ausführlicher erklärt, aber die Idee ist, dass wir eine Anfrage an die API von ESPN senden, um eine bestimmte Ansicht für eine bestimmte Liga, Woche und Saison zu erhalten, die uns vollständige Matchup-/Boxscore-Informationen einschließlich prognostizierter Punkte liefert. Die Cookies werden nur für private Ligen benötigt, und auch hier gehe ich darauf ein.
Wenn Sie durch die JSON-Struktur navigieren, werden Sie feststellen, dass jedes Fantasy-Team eine roster seiner Spieler hat, und jeder Spieler hat eine Auflistung seiner stats.
(Auch hier kann man mit den Webentwickler-Werkzeugen von Safari gut durch diese Struktur navigieren: Gehen Sie zu einer interessanten Seite im Clubhaus Ihrer Fantasy-Liga, öffnen Sie die Webentwickler-Werkzeuge, gehen Sie zu Ressourcen und suchen Sie dann unter XHRs nach einem Objekt mit Ihrer Liga-ID. Dies ist der Rohtext des JSON … ändere „Response“ in „JSON“ in der kleinen Kopfzeile, um eine benutzerfreundlichere Oberfläche im Explorer-Stil zu erhalten.)
Alle 2018-Projektionen erfassen
Es ist ein wenig versteckt, aber in dieser Unterstruktur befinden sich die prognostizierten und tatsächlichen Fantasy-Punkte für jeden Spieler auf jedem Roster.
Ich habe festgestellt, dass die stats-Liste für einen bestimmten Spieler 5-6 Einträge hat, von denen einer immer die prognostizierte Punktzahl und ein anderer die tatsächliche ist. Die geplante Punktzahl wird mit statSourceId=1 identifiziert, die tatsächliche mit statSourceId=0.
Nutzen wir diese Beobachtung, um eine Reihe von Schleifen zu erstellen, um GET-Anfragen für jede Woche zu senden und dann jede geplante/ tatsächliche Punktzahl für jeden Spieler in jedem Dienstplan zu extrahieren.
import requestsimport pandas as pdleague_id = 123456season = 2018slotcodes = { 0 : 'QB', 2 : 'RB', 4 : 'WR', 6 : 'TE', 16: 'Def', 17: 'K', 20: 'Bench', 21: 'IR', 23: 'Flex'}url = 'https://fantasy.espn.com/apis/v3/games/ffl/seasons/' + \ str(season) + '/segments/0/leagues/' + str(league_id) + \ '?view=mMatchup&view=mMatchupScore'data = print('Week ', end='')for week in range(1, 17): print(week, end=' ') r = requests.get(url, params={'scoringPeriodId': week}, cookies={"SWID": swid, "espn_s2": espn}) d = r.json() for tm in d: tmid = tm for p in tm: name = p slot = p pos = slotcodes # injured status (need try/exc bc of D/ST) inj = 'NA' try: inj = p except: pass # projected/actual points proj, act = None, None for stat in p: if stat != week: continue if stat == 0: act = stat elif stat == 1: proj = stat data.append()print('\nComplete.')data = pd.DataFrame(data, columns=)Week 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Complete.Wir erhalten etwa Folgendes:
data.head() Week Team Player Slot Pos Status Proj Actual0 1 1 Leonard Fournette 2 RB QUESTIONABLE 13.891825 5.01 1 1 Christian McCaffrey 2 RB ACTIVE 11.067053 7.02 1 1 Derrick Henry 20 Bench ACTIVE 10.271163 2.03 1 1 Josh Gordon 4 WR OUT 6.153141 7.04 1 1 Philip Rivers 0 QB QUESTIONABLE 26.212294 42.0Ja, ja, das sind nur die Spieler auf den Dienstplänen, also erfassen wir keine freien Agenten … aber es sollte uns zumindest ein Gefühl für die Genauigkeit der ESPN-Prognosen geben, fürs Erste.
Lasst uns „Proj“ gegen „Actual“ für ein paar verschiedene Positionen aufstellen und die Daumen drücken …
fig, axs = plt.subplots(1,3, sharey=True, figsize=(12, 4))for i, pos in enumerate(): (data .query('Pos == @pos') .pipe((axs.scatter, 'data'), x='Proj', y='Actual', s=50, c='b', alpha=0.5) ) axs.plot(, , 'k--') axs.set(xlim=, ylim=, xlabel='Projected', title=pos)axs.set_ylabel('Actual')plt.tight_layout()plt.show()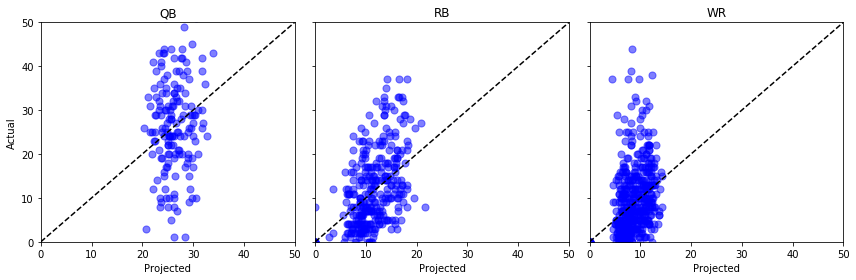
Um, nicht gut. Wir könnten hier ein paar statistische Tests machen, aber für mein ungeschultes Auge sieht es so aus, als ob diese hochgerechneten Punkte genauso gut aus einer Gleichverteilung stammen könnten.
Vielleicht ist es in bestimmten Wochen besser? Vielleicht später in der Saison? Lassen Sie uns den Gesamtfehler nach Woche und Position darstellen. Dieser Code ist ein wenig hakelig 🙁 aber ich bin bereit, damit zu leben:
fig, axs = plt.subplots(1,3, sharey=True, figsize=(13,4))data = data - datadata = pd.cut(data, bins=4, labels=)cols = sns.color_palette('Blues')# dummy plots for a legendfor k,cat in enumerate(): axs.plot(,, c=cols, label='Wk ' + cat)axs.legend()for i, pos in enumerate(): for cat in range(4): t = data.query('Pos == @pos & Cat == @cat') sns.kdeplot(t, color=cols, ax=axs, legend=False) axs.set(xlabel='Actual - Proj', title=pos) plt.show()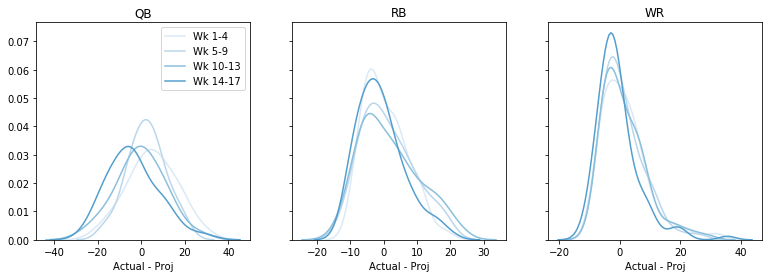
Vielleicht gibt es eine Tendenz zur Überprojektion später in der Saison, aber insgesamt würde ich auch hier nichts sagen. (Beachten Sie, dass wir dadurch einige Informationen darüber verloren haben, ob der Fehler bei hohen oder niedrigen Prognosen größer oder kleiner ist.)
Als Nächstes möchte ich mir die Zeitreihen der Punkte der Spieler ansehen. Der gesunde Menschenverstand sagt, dass man am besten abschätzen kann, was ein Spieler in der nächsten Woche erreichen wird, wenn man seine letzten 4-5 Wochen im Auge behält … wie zuverlässig ist diese Strategie?
In diesem Beitrag versuche ich, die ESPN-Projektionen auf Roster-Ebene zu überprüfen – vielleicht sind die einzelnen Projektionen nicht beeindruckend, aber sind sie in der Summe auf magische Weise hilfreich? (Spoiler: nicht wirklich.)
Geschrieben am 5. August 2019 von Steven Morse